最近知ったRubyのメソッドについてまとめる
目次
概要
最近知ったRubyのメソッドをまとめます。 Rubyのメソッドを知る過程で知った、Ruby以外の知識もまとめます。
最近知ったRubyのメソッド
Enumerable#tally
tallyメソッドは、self に含まれる要素を数え上げた結果を Hash で返します。Hashのキーが数え上げ対象の要素で、valueが要素の出現回数です。 ちなみに、tallyは多動詞で、「集計する」という意味です。
このメソッドを使うことで、以下のような配列の重複要素を数え上げる処理が簡潔に書くことができます。
↓ before
# @param [Array<Integer>] numbers # @return [Integer] def get_unique_number(numbers) number_counter = Hash.new(0) numbers.each { |number| number_counter[number] += 1 } unique_numbers = number_counter.filter { |_, count| count == 1 }.keys unique_numbers[0] end
↓ after(keyメソッドを使うことで、valueが1のkeyを取得できます)
# @param [Array<Integer>] numbers # @return [Integer] def get_unique_number(numbers) numbers.tally.key(1) end
Enumerable#all?
Enumerable#all?は、すべての要素が条件を満たす場合に true を返します。偽である要素があれば、ただちに false を返します。 このall?を使うことで、以下の処理を簡潔に書くことができます。
↓ before
# @param [Array<Array<Integer>>] matrix # @return [Boolean] def square_matrix?(matrix) row_count = matrix.length matrix.each do |numbers| return false unless numbers.length == row_count end true end
↓ after
# @param [Array<Array<Integer>>] matrix # @return [Boolean] def square_matrix?(matrix) row_count = matrix.length matrix.all? { |numbers| numbers.length == row_count } end
Array#transpose
transposeメソッドを使うことで、selfを行列と見立てて、行列の転置(行と列の入れ換え)を行います。転置した配列を生成して返します(生成するので、このメソッドは破壊的ではない)。空の配列に対しては空の配列を生成して返します。
irb irb(main):001:0> a = [[1, 2, 3], [3, 5, 5]] irb(main):003:0> a.transpose => [[1, 3], [2, 5], [3, 5]] irb(main):004:0> a => [[1, 2, 3], [3, 5, 5]] irb(main):005:0>
Array#concat
Array#concatメソッドを使うことで、selfの末尾に引数の配列を破壊的に追加します。この際に気をつけるのが、配列自体を要素として、selfに追加されるわけではなく、引数の配列は展開されて、selfに追加されます。ちなみに、concatは、concatenateの略で、concatenateは他動詞で、「~を連結させる」という意味です。
irb(main):005:0> a = [1, 2, 3] irb(main):006:0> b = [4, 5, 5] irb(main):007:0> a.concat(b) => [1, 2, 3, 4, 5, 5] irb(main):008:0> a => [1, 2, 3, 4, 5, 5] irb(main):009:0> b => [4, 5, 5] irb(main):010:0>
配列から要素を追加、取得系のメソッド
破壊的、非破壊的の観点からまとめていきます。
破壊的
配列に破壊的に要素を追加するなら、push/unshiftを使います。 配列から破壊的に要素を取得する、pop/shiftを使います。
Array#pushメソッドは、指定された objを順番に配列の末尾に破壊的に追加します。
irb(main):001:0> a = [1, 2, 3] irb(main):002:0> a.push(5) => [1, 2, 3, 5] irb(main):003:0> a => [1, 2, 3, 5] irb(main):004:0> a.push([6, 6]) => [1, 2, 3, 5, [6, 6]] irb(main):005:0> a => [1, 2, 3, 5, [6, 6]] irb(main):001:0> a = [1, 2, 3] irb(main):002:0> a.push(1, 2) => [1, 2, 3, 1, 2] irb(main):022:0> a = [1, 2, 3] irb(main):023:0> a.push([1, 2]) => [1, 2, 3, [1, 2]] irb(main):024:0> a.push(*[1, 2]) => [1, 2, 3, [1, 2], 1, 2] irb(main):001:0> a = [1, 2, 3] # 配列を展開して追加するなら、concatを使う方が綺麗 irb(main):002:0> a.push(*[1, 2]) => [1, 2, 3, 1, 2] irb(main):003:0> a.concat([5, 6]) => [1, 2, 3, 1, 2, 5, 6]
Array#unshiftは、指定された obj を引数の最後から順番に配列の先頭に破壊的に挿入します。Array#pushとArray#unshiftの違いは、pushは配列の末尾に要素を追加するのに対して、unshiftは配列の先頭に要素を追加します。
irb(main):001:0> a = [1, 2, 3] irb(main):002:0> a.push(1, 2) => [1, 2, 3, 1, 2] irb(main):003:0> a = [1, 2, 3] irb(main):004:0> a.unshift(1) => [1, 1, 2, 3] irb(main):005:0> a.unshift(1, 2) => [1, 2, 1, 1, 2, 3] irb(main):006:0> a.unshift(8) => [8, 1, 2, 1, 1, 2, 3] irb(main):007:0> a.unshift(9, 10) => [9, 10, 8, 1, 2, 1, 1, 2, 3] irb(main):014:0> a.unshift([2, 3]) => [[2, 3], 9, 1, 2, 3] irb(main):015:0> a.unshift(*[2, 3]) => [2, 3, [2, 3], 9, 1, 2, 3]
Array#popは、自身の末尾から要素を破壊的に取り除いて、その要素を返します。引数を指定した場合はその個数だけ取り除き、それを配列で返します。
irb(main):004:0> a = [1, 2, 3] irb(main):005:0> a.pop => 3 irb(main):006:0> a => [1, 2] irb(main):007:0> a.push(3) => [1, 2, 3] irb(main):008:0> a => [1, 2, 3] irb(main):009:0> a.pop(2) => [2, 3] irb(main):010:0> a = [1, [2, 3], 4] irb(main):011:0> a.pop => 4 irb(main):012:0> a => [1, [2, 3]] irb(main):013:0> a.pop => [2, 3] irb(main):014:0> a => [1]
Array#shiftは、配列の先頭の要素を破壊的に取り除いて、その要素を返します。引数を指定した場合はその個数だけ取り除き、それを配列で返します。
irb(main):001:0> a = [1, 2] irb(main):002:0> a.shift => 1 irb(main):003:0> a => [2] irb(main):004:0> a = [1, [2, 3], 5] irb(main):005:0> a.shift => 1 irb(main):006:0> a => [[2, 3], 5] irb(main):007:0> a.shift => [2, 3] irb(main):008:0> a => [5] irb(main):011:0> a => [5] irb(main):012:0> a.push([1, 2]) => [5, [1, 2]] irb(main):013:0> a.shift(2) => [5, [1, 2]] irb(main):014:0> a => []
これらの配列の破壊的メソッドをいつ使うかを表にまとめます。
| 配列に要素を追加する | 配列から要素を取り出す | |
|---|---|---|
| 先頭 | unshift | shift |
| 末尾 | push | pop |
この表から、 配列の先頭に要素を追加したいなら、unshift 配列の要素を先頭から取り出したいなら、shift (shiftはずらすって意味だから、前の要素がずれて取り出せるってイメージでなんとなくメソッドの動作が理解できる) 配列の末尾に要素を追加したいなら、push 配列の要素を末尾から取り出したいなら、pop
を使えば良いということが分かりました。
非破壊的
配列を破壊的に操作したいなら、まずはその配列のコピーを作ることが大事です。そのような場合、スプラット演算子を使いましょう。
irb irb(main):001:0> a = [1, 2, 3] irb(main):002:0> a => [1, 2, 3] irb(main):003:0> a.push(1, 2) => [1, 2, 3, 1, 2] irb(main):004:0> a => [1, 2, 3, 1, 2] irb(main):005:0> a = [1, 2, 3] irb(main):006:0> [*a].push(4) => [1, 2, 3, 4] irb(main):007:0> a => [1, 2, 3] irb(main):008:0> [*a, 4] => [1, 2, 3, 4] irb(main):009:0> [*a].shift => 1 irb(main):010:0> a => [1, 2, 3] irb(main):011:0> [*a].unshift(3) => [3, 1, 2, 3] irb(main):012:0> a => [1, 2, 3] irb(main):013:0> [3, *a] => [3, 1, 2, 3] irb(main):014:0> a => [1, 2, 3] irb(main):015:0> [*a, 4] => [1, 2, 3, 4] irb(main):016:0> a => [1, 2, 3] irb(main):017:0> [*a].push(4) => [1, 2, 3, 4] irb(main):018:0> a => [1, 2, 3] irb(main):019:0> [*a].pop => 3 irb(main):020:0> a => [1, 2, 3] irb(main):021:0>
ファイルは改行で終わらす
unixでは、テキスト・ファイルは一連の行で構成され、それぞれの行は改行文字( \n)で終わる。したがって、空でなく改行で終わらないファイルはテキスト・ファイルではない。
テキスト・ファイルを操作することを想定したユーティリティは、改行で終わらないファイルにうまく対処できないかもしれません
ファイルに書いた一連の行は改行文字で終わらせる方が良いので、そのため、ファイルには改行が含まれているそうです。 これはunixの規約なので、必ずしも守る必要はないですが、Github上で赤くマイナスが表示される時は、ファイルの末尾に改行が含まれていない指摘です。
終わり
Rubyに関して色々メソッドが知れてよかったです。 また、この機会で、配列を操作する系のメソッドも整理できて良かったです。
参考記事
leet codeのSQL問題を1日1題解く【1378. Replace Employee ID With The Unique Identifier】
目次
初めに
今日もSQLの問題を解いて行きます。
問題
セットアップ
以下のSQL文をローカル環境で実行します。
Create table If Not Exists Employees (id int, name varchar(20)); Create table If Not Exists EmployeeUNI (id int, unique_id int); Truncate table Employees; insert into Employees (id, name) values ('1', 'Alice'); insert into Employees (id, name) values ('7', 'Bob'); insert into Employees (id, name) values ('11', 'Meir'); insert into Employees (id, name) values ('90', 'Winston'); insert into Employees (id, name) values ('3', 'Jonathan'); Truncate table EmployeeUNI; insert into EmployeeUNI (id, unique_id) values ('3', '1'); insert into EmployeeUNI (id, unique_id) values ('11', '2'); insert into EmployeeUNI (id, unique_id) values ('90', '3');
知らなかった or 理解があやふやな知識
結合について
結合に関しては、以下の記事でまとめています。
解答
以下のSQL文を実行することで、画像のような結果を取得できます。
SELECT * FROM Employees LEFT OUTER JOIN EmployeeUNI ON Employees.id = EmployeeUNI.id
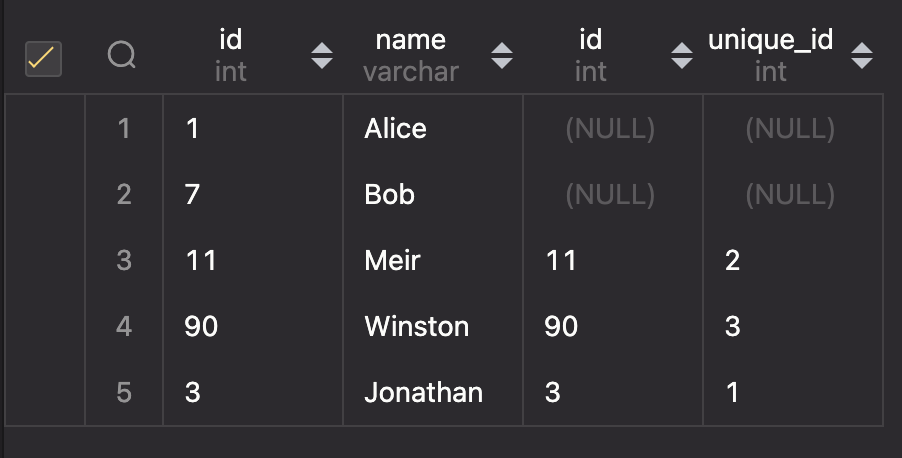
左外部結合を使っているので、メインで指定したテーブルの内容は全て表示して、結合条件に一致するようなレコードが結合先のテーブルに存在しない場合、NULLが入ったレコードが結合されます。そのことが実行結果から確認できました。
以下のSQL文を実行したら、無事クリアできました。
SELECT UNI.unique_id, E.name FROM Employees AS E LEFT OUTER JOIN EmployeeUNI AS UNI ON E.id = UNI.id
終わり
明日もやります!
参考記事
leet codeのSQL問題を1日1題解く【1683. Invalid Tweets】
目次
初めに
今日もSQLの問題を解いて行きます。
問題
セットアップ
以下のSQL文をローカル環境で実行します。
Create table If Not Exists Tweets(tweet_id int, content varchar(50)); Truncate table Tweets; insert into Tweets (tweet_id, content) values ('1', 'Vote for Biden'); insert into Tweets (tweet_id, content) values ('2', 'Let us make America great again!');
知らなかった or 理解があやふやな知識
CHAR_LENGTH関数
CHAR_LENGTH関数は、カラムに格納されている文字列の文字数を取得できます。
解答
以下のSQL文を実行したら、無事クリアできました。 このSQLを実行することで、contentが15より大きい(つまり、コンテンツに書いてある文字数が15文字より多い)ツイートを特定することができます。
select tweet_id from `Tweets` WHERE CHAR_LENGTH(content) > 15
終わり
明日もやります!
参考記事
leet codeのSQL問題を1日1題解く【1148. Article Views I】
目次
初めに
今日もSQLの問題を解いて行きます。
問題
セットアップ
以下のSQL文をローカル環境で実行します。
Create table If Not Exists Views (article_id int, author_id int, viewer_id int, view_date date); Truncate table Views; insert into Views (article_id, author_id, viewer_id, view_date) values ('1', '3', '5', '2019-08-01'); insert into Views (article_id, author_id, viewer_id, view_date) values ('1', '3', '6', '2019-08-02'); insert into Views (article_id, author_id, viewer_id, view_date) values ('2', '7', '7', '2019-08-01'); insert into Views (article_id, author_id, viewer_id, view_date) values ('2', '7', '6', '2019-08-02'); insert into Views (article_id, author_id, viewer_id, view_date) values ('4', '7', '1', '2019-07-22'); insert into Views (article_id, author_id, viewer_id, view_date) values ('3', '4', '4', '2019-07-21'); insert into Views (article_id, author_id, viewer_id, view_date) values ('3', '4', '4', '2019-07-21');
知らなかった or 理解があやふやな知識
SELECT文の評価順序
SELECT文は以下のの順序で評価されます
1. FROM 2. ON 3. JOIN 4. WHERE 5. GROUP BY 6. HAVING 7. SELECT 8. DISTINCT 9. ORDER BY 10. TOP(LIMIT)
ORDER BYを書くと取得した行に対してソートを実行できます。ソートは重い処理なので、SELECTした後の結果に対してソートを実行した方が、考慮すべき行数が減るので、この順序で実行されるのはなんとなく理解できます。 WHEREがGROUP BYより上にあるのも、グループ化させるよりも前にWHEREの条件を適用させた方が、考慮すべき行数が減るので、WHEREの後にGROUP BYが実行されるのもなんとなく理解できます。
GROUP BYを使う時に、SELECTにGROUP BYで指定したカラム以外を指定するとエラーになる
GROUP BYを使う場合、SELECTにはGROUP BYで指定したカラムを指定しましょう
WHERE と HAVINGの違い
WHEREはあくまで、テーブルの行に対してのみしか条件を指定できません。 グループごとの行に対して条件を指定したい場合、HAVINGを使います。
ORDER BY
ORDER BYを使うことで、SELECTした結果を昇順または降順に並べ替えることができます。(デフォルトはASCです)
SQL文を書くときにカラム名やテーブル名をバッククォートで囲む理由
MySQL側での予約語は、テーブル名やカラム名などに使うことはできません。 ただし、MySQLでは予約語をバッククォートで囲むことで、テーブル名やカラム名として使用可能になります。普通はテーブル名やカラム名を予約語にしない気がするので、一応知識として持っておきます。
解答
以下のSQL文を実行したら、無事クリアできました。
SELECT author_id AS id FROM `Views` WHERE author_id = viewer_id GROUP BY author_id ORDER BY author_id
終わり
明日もやります!
参考記事
leet codeのSQL問題を1日1題解く【595. Big Countries】
目次
初めに
今日もSQLの問題を解いて行きます。
問題
セットアップ
以下のSQL文をローカル環境で実行します。
Create table If Not Exists World (name varchar(255), continent varchar(255), area int, population int, gdp bigint); Truncate table World; insert into World (name, continent, area, population, gdp) values ('Afghanistan', 'Asia', '652230', '25500100', '20343000000'); insert into World (name, continent, area, population, gdp) values ('Albania', 'Europe', '28748', '2831741', '12960000000'); insert into World (name, continent, area, population, gdp) values ('Algeria', 'Africa', '2381741', '37100000', '188681000000'); insert into World (name, continent, area, population, gdp) values ('Andorra', 'Europe', '468', '78115', '3712000000'); insert into World (name, continent, area, population, gdp) values ('Angola', 'Africa', '1246700', '20609294', '100990000000');
知らなかった or 理解があやふやな知識
Rubyの場合==で等価比較ができるのですが、SQLだと=で等価比較ができるので、ごっちゃにならないように気をつけます。
解答
以下のSQL文を実行したら、無事クリアできました。
SELECT name, area, population from `World` WHERE area >= 3000000 OR population >= 25000000;
終わり
明日もやります!
参考記事
leet codeのSQL問題を1日1題解く【584. Find Customer Referee】
目次
初めに
今日もSQLの問題を解いて行きます。
問題
セットアップ
以下のSQL文をローカル環境で実行します。
Create table If Not Exists Customer (id int, name varchar(25), referee_id int); Truncate table Customer; insert into Customer (id, name, referee_id) values ('1', 'Will', NULL); insert into Customer (id, name, referee_id) values ('2', 'Jane', NULL); insert into Customer (id, name, referee_id) values ('3', 'Alex', '2'); insert into Customer (id, name, referee_id) values ('4', 'Bill', NULL); insert into Customer (id, name, referee_id) values ('5', 'Zack', '1'); insert into Customer (id, name, referee_id) values ('6', 'Mark', '2');
知らなかった or 理解があやふやな知識
デフォルトでは、カラムはNULL値を保持することができる
カラムはデフォルトでは、NULL値を保持することができます。 そのため、Integerカラムと言いつつも、NULL値を保持することができます。もし、NULLを許容したくないなら、NOT NULL制約をカラムに適用させます。
CREATE TABLE Persons ( ID int NOT NULL, LastName varchar(255) NOT NULL, FirstName varchar(255) NOT NULL, Age int );
SQLでnot equalな条件文を作りたいなら、!= or <>のどちらかの比較演算子を使う
SQLでnot equalな条件文を作りたい場合、!= or <>のどちらかの比較演算子を使います。
SQL文で、NULLかどうかを判定したいなら、IS NULLを使う
NULLかどうかを判定したいならIS NULL、NULLではないを判定したいなら、IS NOT NULLを使います。
解答
以下のSQL文を実行したら、無事クリアできました。
SELECT name FROM Customer WHERE referee_id != 2 OR referee_id IS NULL
終わり
明日もやります!
参考記事
leet codeのSQL問題を1日1題解く【1757. Recyclable and Low Fat Products】
目次
初めに
SQL力はやっぱ書かないと落ちるなと感じたので、1日1題解いて行きます。
問題
セットアップ
以下の記事を参考にして、VSCode上でもSQLを実行できるようにします。DB環境をDockerを用いて構築しています。
以下のsqlを実行して、データベースにテーブルを作成したり、データをインサートします。
Create table If Not Exists Products (product_id int, low_fats ENUM('Y', 'N'), recyclable ENUM('Y','N')); Truncate table Products; insert into Products (product_id, low_fats, recyclable) values ('0', 'Y', 'N'); insert into Products (product_id, low_fats, recyclable) values ('1', 'Y', 'Y'); insert into Products (product_id, low_fats, recyclable) values ('2', 'N', 'Y'); insert into Products (product_id, low_fats, recyclable) values ('3', 'Y', 'Y'); insert into Products (product_id, low_fats, recyclable) values ('4', 'N', 'N');
知らなかった or 理解があやふやな知識
CREATE TABLE if NOT EXISTS
CREATE TABLE IF NOT EXISTS t1 ( c1 INT, c2 VARCHAR(10) );
ここで、t1はテーブル名で、括弧の間はすべてテーブルの定義(カラムなど)である。 この場合、t1というテーブルがまだ存在しない場合にのみ、テーブルが作成される。
CREATE TABLEにIF NOT EXISTSを書くことで、同じテーブルが既に存在する場合、CREATE TABLEを実行しないようにできることがわかりました。
TRUNCATE TABLEステートメント
TRUNCATE [TABLE] tbl_name
TRUNCATE TABLE は、テーブルを完全に空にします。 これには DROP 権限が必要です。 TRUNCATE TABLE は論理的に、すべての行を削除する DELETE ステートメントや、DROP TABLE および CREATE TABLE ステートメントのシーケンスに似ています。
TRUNCATE TABLE は DELETE と違い、AUTO_INCREMENT 値がすべて開始値にリセットされたり、パフォーマンスの面で優れているそうです。テーブルを完全に空にしたい時に、TRUNCATE TABLEステートメントを使ってみようと思います。
Enum
ENUM は、テーブル作成時にカラム仕様に明示的に列挙された、許可されている値のリストから選択された値を持つ文字列オブジェクトです。
ENUMカラムは一見優れているように見えますが、アプリケーション側で許可する値を追加したい場合、ENUMカラムの定義も変更しないといけません。つまり、一つの変更をしたいだけなのに、それ以外の別の変更(ENUM定義の変更)もしなければなりません。そのため、値を制限するカラムをテーブルに追加する場合、「RailsのようにInteger型のカラムにしてアプリケーション側でカラム値を制限するようにする」 or「 そのカラムの値を表す別テーブルを用意して、そのカラムには外部キーを格納する」が良いでしょう。
解答
こんな感じのSQL文を書きました。無事AC(Accepted(正解))できてよかったです。
select product_id from Products WHERE low_fats = "Y" AND recyclable = "Y";