Bearer認証についてまとめる
目次
- 目次
- Bearer認証(トークン認証)とは
- Bearerトークンとは
- BearerトークンとPoPトークンの違い
- Bearer認証のフロー
- Bearer認証のメリットデメリット
- クッキーとローカルストレージの特徴をまとめる
- Goでサーバーサイド側のBearer認証を実装してみた
- 終わり
- 参考記事
Bearer認証(トークン認証)とは
Bearer認証とは、Bearerトークンを用いたHTTPベースの認証のことです。Bearer認証はトークン認証とも呼ばれます。JWT認証もや外部APIへのリクエスト方法はBearer認証に似ているので、JWT認証や外部APIへのリクエスト方法は、Bearer認証の考え方をベースにされているのかなと思います(おそらく)。
Bearerトークンとは
Bearerトークンとは、リソースへのアクセス制御を担うトークン(アクセストークン)の一つの種類です。Bearerトークンは、署名なしトークンとも呼ばれます。BearerトークンはBearer(それを持ってきた存在)にアクセス権限を与える特性を持ちます。Bearerトークンは以下のフォーマットに従います。
b64token = 1*( ALPHA / DIGIT /
"-" / "." / "_" / "‾" / "+" / "/" ) *"="
credentials = "Bearer" 1*SP b64token
BearerトークンとPoPトークンの違い
Bearerトークンは電車の切符に例えられます。切符は電車へのアクセスを制限するトークンであるとも言えます。切符の利用権利は「切符を持ってきた人(Bearer)」に付与されます。ゆえにBearerトークンは電車のきっぷに例えられます。拾った切符であっても、持ってきた人(Bearer)に乗車権利が付与されます。
Bearerトークンと対極の存在であるPoPトークンでは、そのトークンを所有している人であることを証明しなければなりません。そのためPoPトークンは国際線飛行機のチケットに例えられます。
Bearer認証のフロー
以下に一般的なBearer認証のフローをまとめます
- ユーザーがログイン情報を入力してサーバーにリクエストを出す。
- ログイン情報が正常だった場合、サーバーはBearerトークンを発行する。その後、レスポンスボディにBearerトークンを格納してレスポンスする。
- クライアントは受け取ったBearerトークンをクッキーまたはローカルストレージに格納する。
- ページへのアクセス時にはAuthorizationリクエストヘッダのvalueにBearerトークンをセットして、サーバーにリクエストを出す。
- サーバーはトークンが有効であるかどうかを確認して、有効ならリクエストされたリソースをレスポンスする。
Authorizationリクエストヘッダとは
HTTP の Authorization リクエストヘッダーは、ユーザーエージェントがサーバーから認証を受けるための証明書を保持するヘッダーです。ふつうは、必ずではないが、サーバーが 401 Unauthorized ステータスと WWW-Authenticate ヘッダーを返した後に使われます。
↓ 構文
Authorization: <type> <credentials>
Bearer認証のメリットデメリット
メリット
- クライアントのローカルストレージ or クッキーにBearerトークンを入れるので、Redisのようなセッションストレージを使わないです。その結果、サービスがスケールしてもサーバーリソースを増やしたりする必要がないです。
- これはRailsでセッションストレージをデフォルト でクッキーにしているのと同じメリットです。
デメリット
- この認証方法の場合、ログアウトしてもローカルストレージに存在するトークンを消すだけです。つまり、ログアウトの前にローカルストレージに存在するトークンが盗まれてしまった場合、ログアウト後に、そのトークンを使って、セッションを再開することができます。そのため、この認証方式ではサーバーサイドでセッションを削除することができないことが分かります。
- Railsのクッキーをデフォルトのセッションストレージにするやり方でも同じデメリットを持ちます。
- 先ほど説明したBearer認証の場合、トークンとユーザー情報をどのように紐付けるかが課題です。JWT認証でJWTトークンにユーザー情報を含めるようにBearerトークンにuser_idなどのユーザー情報を含めるか、または、トークンをステートフルなトークンとして扱い、ユーザー情報とトークン情報を紐付けてデータストレージに保存する方法が考えられます。後者のやり方の場合、サーバー側でセッションを切れるのでセッションの問題も解決しています(ただ、それだともはやJWTじゃなくて従来のセッションクッキーでよくね?という気もしますが)
クッキーとローカルストレージの特徴をまとめる
Bearer認証の際に利用するBearerトークンをクッキーに保存するかのか、ローカルストレージに保存するのかでよく議論が起こります。それぞれ状況に応じて良し悪しあると思うので、まずはその2つの特徴をまとめます。
クッキー
- クッキーとは、(クッキーの名前, クッキーの値)が成すペアと、それに結び付けられた0個以上のメタデータです。
- Set-Cookieヘッダを使うと、サーバーからクライアント(ブラウザ)に対してクッキーを送信できます。クッキーの数だけSet-Cookieヘッダを用意する必要があります。
- クライアントはサーバーからクッキーが送られてきたら、そのクッキーをおそらくクライアント独自の保存領域に保存します。
- クッキーに対して特に制限がかけられていなければ、クライアントはクッキー生成元サーバーにリクエストをするたびに、そのサーバーが生成したクッキーをCookieヘッダを使って送信します。(Cookieヘッダにはクッキー名とクッキーのvalueしか指定せず、クッキーのメタデータは指定しないので注意)
- リクエスト時にCookieを送るか送らないかは、Same Origin Policyを基準にしているわけではなくて、リクエスト先のドメインを元に判断しています(ここごっちゃになりやすいので注意)。クッキー生成時に特にドメインを指定しない場合、クッキー生成元サーバーのドメインにリクエストをするたびに、そのサーバーが生成したクッキーをCookieヘッダを使って送信します。
- Cookieヘッダー自体はHTTPリクエストメッセージに1つだけ含めることができます。そのため、複数のクッキーを送る場合は;で区切ります。
クッキーの重要な属性について
クッキーの重要な属性についてまとめます。
Domain属性
Secure属性
- サーバーは、この属性を使うことでセキュアなチャンネルで通信が行われる場合にのみCookieを送信するように求めることができます。
- HttpOnly属性
- HttpOnly 属性は、クッキーの視野を HTTP 要請に制限します。要するに、HttpOnly属性は、クッキーの利用範囲をHTTPリクエストの時だけに制限するということです。ややこしいのですが、httpOnly属性が指定されたCookieをfetch APIで送信することはできますが、JavaScriptからそのCookieの値にアクセスすることはできないということです(確かそうだった)。
- Same-Site属性
- Same-Site属性は、リクエスト元とリクエスト先が異なるサイトの場合、クッキーを送信するかしないかを制限できる属性です。Sam-Site属性があることで、この属性を指定することで、CSRF攻撃に対して防御をすることができます。
- Domain属性は送信先のドメインに対して制限をかけます。Same-Site属性は送り元のサイトに対して制限をかけます。
- Domain属性はあくまでどのサーバーにリクエストをする際にクッキーを送信するかを指定するだけです。そのため、「ある罠サイトからDomain属性に指定されたドメインにHTTPリクエストをする」とクッキーは送信できてしまいます。Same-Site属性を使うことでリクエスト元のサイトがリクエスト先のサイトと異なる場合、クッキーを送信しないようにできます。
- None: 過去にサイトBから付与されたCookieは、サイトAから無条件にサイトBへ送信されます
- Lax: 過去にサイトBから付与されたCookieは、サイトAから(大雑把にいえば)GETリクエストのみ送信しますが、POSTやPUTなどのリクエストではCookieは送信しません。
- Strict: 過去にサイトBから付与されたCookieは、サイトAからサイトBへは送信されません
- サイトはドメイン名の登録可能なドメイン部分によって決定されます。 つまり、api.example.comとexample.comでは、登録可能なドメイン部分(example.com)が一緒なので、同一サイトとして扱われます。ゆえに、Same-Site属性をStrictにしてもフロントエンドからクッキーを送信することができ、かつCSRFの脅威から防御することができます(同一サイトではないとSame-Site属性をNoneにしないと、クッキーを送信できない。それではCSRF対策したことにならない)
セキュリティを高めるためにも、Cookieのこれらの属性はできるだけ付けた方が良いでしょう。
ローカルストレージ
- localStorage は window プロパティの読み取り専用プロパティで、この Document の origin における Storage オブジェクトにアクセスできます。
- 格納されたデータは、ブラウザーのセッションを跨いで保存されます。
- JavaScriptでブラウザに保存したり、参照したり、削除したりできる
- シンプルなキーバリューストレージで、サーバーに勝手に送信されない。
- アクセスの範囲は同一オリジンに限定されています。 つまり、別オリジンのサイトを見ていたときに、そのクライアントに保存されている別のオリジンのローカルストレージに対して、別オリジンのサイトがJSでアクセスしたりはできません。
- localStorage は sessionStorage によく似ていまが、 localStorage のデータには期限がないのに対し、 sessionStorage のデータはページセッションが終了したとき、すなわちページが閉じられたときにクリアされます。
ローカルストレージはjsでトークンが取られるからだめだとよく聞きますが、罠サイト(https://hoge.com)からapiサーバー(https://api.amazon.com)のローカルストレージへのアクセスはできないです。ローカルストレージへのアクセスは、同一オリジンに限定されるためです。そのため、そんな騒ぐほど危険ではないです。しかし、投稿できる系のサービスで投稿内容をサイニタイズをしていない場合、同一オリジンのjsとして実行されてしまうので、jsからローカルストレージへアクセスできてしまう気もします。そのため、Cookieを使うならCSRF対策、ローカルストレージを使うなら、XSS対策を入念にした方が良いでしょう。
Goでサーバーサイド側のBearer認証を実装してみた
ステートフルなトークンを使って、Bearer認証を実装してみようと思います。この実装のデメリットは、ストレージを用意する必要があるということです(今回はDBを利用した)。メリットとしては、従来のBearer認証よりセキュリティを高めることができるということです。Laravelなどにステートフルなトークン認証があるそうです。
こちらにリポジトリのリンクを貼っておきます。
終わり
若干まだまだわかっていないところもあるので、再度深ぼってみます。
参考記事
様々な認証方式について(Bearer,Basic,Digest,Form,OAuth)
どうしてリスクアセスメントせずに JWT をセッションに使っちゃうわけ? - co3k.org
君はできるかな?Cookie & Same Origin Policyセキュリティークイズ4問 #JavaScript - Qiita
Window: localStorage プロパティ - Web API | MDN
The OAuth 2.0 Authorization Framework
The OAuth 2.0 Authorization Framework: Bearer Token Usage(日本語)
Cookieを扱う|伸び悩んでいる3年目Webエンジニアのための、Python Webアプリケーション自作入門
JWTを認証用トークンに使う時に調べたこと - Carpe Diem
PHP Conference Japan 2021: SPAセキュリティ入門 / 徳丸 浩 - YouTube
トークンを利用した認証・認可 API を実装するとき Authorization: Bearer ヘッダを使っていいのか調べた #API - Qiita
転職の軸を定める
目次
- 目次
- 概要
- なぜこの記事を書こうと思ったのか
- これまでの経歴を振り返ってみる
- 仕事をしていた際の反省点
- 転職の思考法を読んで今の自分のフェーズにあってそうだなという考えをまとめる
- 自分の就活の軸とは
- 転職面接の際にしたい質問
- もし受かったらしたい質問
- 終わり
- 参考記事
概要
今回の転職の軸をどうするかを決めようと思います。
なぜこの記事を書こうと思ったのか
最近受けたカジュアル面談を担当していたCEOが、たまたま元人事兼エンジニアの方だったので、色々キャリアについて相談させていただきました。その際に以下のようなことを指摘されました。
- 0 → 1なら個人開発をいっぱいした方が良い。0 → 1できないのに、そもそも任せない。
- バックエンドはパフォーマンスチューニングの仕事とかも全然ある
- 事業ドメインに興味を持てなかったって言わない方が良い。入る前からわかったでしょって言われたら詰むだけだから。入ってみて実際にやってみていうのでも良いけど、どっちみし入る前にわからなった時点で評価は下がる。
- やりたいことの軸がはっきりしていないとすぐやめると思われる
- ユーザーの顔が見えないからやめるって理由はあんま良くない。どのサービスやってもどっちみしみえないから。ユーザーの顔はどのサービスに携わっても見えないって思っておいた方が良い。想像力の問題。想像力を掻き立ててサービスを作れるかの話。それができないなら想像力がないだけの話。
- 仕事なんで、っていうスタンスでやった方が良い。何が好きなのか自分で考える
- プロダクトマネージャーが決めたものをエンジニアは作る。エンジニアは降ってきた課題に対して、技術的でどうやってエレガントに解決するかに全力を振った方が良い。それがプロのエンジニア(プロマネが決めなくても自分で仕様は考えたいけどね)。
- 言っていることとやっていることに一貫性がないとダメ。何がやりたいかがわからないので、一貫性がない。意味がわからないなこの人、何考えているんだろうなって思われるだけ
- 会社に入ってどんなことをやりたいのか、やりたいことがはっきりしていないと、すぐ辞めると思われるし、入った後になんか違うってなってすぐ辞めてしまう。
- 自分が何をしたいのか、自分が行きたいところをもっと言語化した方が良い。
これを言われた時は、この人理論的すぎて無理だなと思ったんですけど、よくよく考えてみると確かにそうだなと感じました(ストレートに言ってくれて良い人だなと思ったけど、一緒に働きたくないタイプ)。改めて自分の軸を定めたいなと思い、今回記事にすることにしました。
これまでの経歴を振り返ってみる
今回転職の軸を定める際に、たまたまある記事を見ました。
転職する際に確認すべきは「どんな成果を求められるのか」と「業務の中に自分が楽しいと感じられるポイントがあるか」だ。今回の場合、この両方が自分には向いていなかった。
自分が何にモチベーションを感じるか、その業務に楽しいと思えるポイントはあるかを把握し、次に活かすことが大切だ。
個人的な意見だが、直感で少しでも迷いがあるなら現職に残ったほうがいいと思う。入社後に自分が選んだ選択肢を正解にしていく道もあるが、これは自分のモチベーションを上げる成果や楽しいと思えるプロセスが転職先にあることが前提だ。
この記事を読んで確かにそうだなと思いました。求められる成果が何なのか、その成果は自分のモチベーションを上げてくれるものなのか、またその成果を出す際に取り組む業務は自分にとって楽しいのか、やりたいことなのか、 ここを決めることで、楽しいと思える時間を最大化することができ、逆につまらない時間を最小化できます。ゆえに、QOLが上げることができます。
今までの経歴を振り返ってみて、どの成果に自分のモチベーションが上がると感じたのか、その成果を出す際にでどの業務が楽しかったのか、どの業務がつまらなかったのか(または不満だったのか)を考えてみます。
前職(ネットスーパー系事業)
どんな成果を出す必要があったか
- ユーザーや会社が求めている機能を、CEOやテックリード、プロダクトマネージャーと仕様を相談した上で、フロントエンド ~ バックエンドを通して実装すること
その成果は自分のモチベーションを上げてくれたのか
- 正直機能を作れても、成果自体にはあまりモチベーションを感じなかった。あ、できたって感じ。
- むしろこの会社の場合、状態に対してモチベーションが上がっていたと思う。
- モダンな環境でテストから実装までちゃんとやれて、初めて開発のイロハを学べている状態に対してモチベーションが上がっていた(TDDやOpenAPIも初めて知った)
- 超優秀なテックリードの方にレビューをもらいながら開発ができたので、自分の技術力が向上しているなと感じた。つまり、自分が成長しているなというところにモチベーションを感じていた。
- 徐々に難易度の高い機能を実装する中で、自分が成長しているなと感じたのが嬉しかった。
まとめると、「技術的にモダンな環境で、強強エンジニアにフィードバックをもらいながら自分が成長していることを実感できていることに対してモチベーションが上がっていた」ということがわかりました。成果というか状態や自分の成長ですね。つまり、この環境の場合、成果自体が自分のモチベーションを上げてくれていなくて、場の状態や自分の成長に足してモチベーションが上がっていました。場の状態や自分の成長に問題があると、一気に楽しくないと感じてしまうということですね。
成果を出す際のプロセスの業務において、どの業務が楽しかったか
- バックエンドでどんなロジックでコードを書けばエンドポイントをちゃんと実装できるかを考えるのは楽しかった。機能単位で考えるのが自分に合ってて楽しかった。
- どこにコードを書いたら他のエンジニアにとってわかりやすいか、どこにコードを書いたら問題があるか、どんな実装をしたら拡張性がって変更をせずに済むかを考えるのは楽しかった。
- どんなライブラリ群を組み合わせれば機能として成立するかを考えるのが面白かった。
- インフラ、DB、メモリ、アプリケーションなど、いろんなものを考慮しながら、組み合わせて機能を作る感じが楽しかった。
- テーブルの設計でどうすれば、仕様が変更してもある機能が増えてもテーブルを大幅に変更しなくても良いかを考えて設計するのが楽しかった。
- どんなインフラ構成にすればシステムが安定的に稼働するかを考えるのが楽しかった(実際にやったわけではないけど)
- デザインのような目にみえるものよりかは機能のような、目に見えないけど機能単位で考えられる抽象的なものの方が好きな気がする。
成果を出す際のプロセスの業務において、どの業務がつまらなかったのか(または不満だったのか)
- コードとは関係のない仕事(店頭調査や冷蔵庫の搬入、商品の梱包など)。これはエンジニアの成長という点でも関係ないので、嫌だった
- 好きではない場所での仕事。Door to Doorで1時間を超えると流石に嫌だなと思ってた。
- 出社すると自分の業務とはどうでも良い仕事(洗剤買ってたりちょっと梱包手伝う)をやらないといけないので、それが嫌だった。コードに集中したいというか、自分の業務で結果を出したいし成長を感じたい。なので途中からリモートしたいですと提案してリモートにしてもらった(そこら辺を理解してくれる社長でもあったので良い人なのは間違いない)。
- フロントエンドはデザインと紐付きすぎていて、デザインも考慮しないといけないからあんま好きではない。デザインって人の感覚に強く依存する。自分はこれでも良くねってデザインでも普通にダメだったりするからなんでやねんって思うことがよくあった。そこに自分の人生の時間を使いたくない。
- cssが嫌い。cssはいろんな書き方で目的のデザインを達成できるので、やり方に正解がない(まあ良いという書き方はあるけど)。あんまりそこのやり方に対してこだわりがなく、目的のデザインが成立してればよくね?と思ってしまうので、そこをうるさく言われるのが嫌だった。
- htmlでサイトの骨組みを作る際も、個人的には成立していればよくねって思ってしまうので、そこをうるさく言われても知らんがなって感じだった。
- 多分自分の中でcssやhtmlに関して何か強いこだわりはなかったんだろうなそこに対して面白いと思わなかったり興味がなかったためだと思う。
- 唯一フロントエンドで面白いなと思うのは、「ユーザーにとってどうやったら使いやすくなるかを考える部分」だと思う。ユーザービリティは割と好きかも。
- バックエンドが楽しいからバックエンドを専門的にやりたかったけど、会社的にはフルスタックな人材が求められる。フルスタックはどちらかのスキルがめちゃくちゃ向上するわけではなく、中途半端にスキルが向上するから、ある領域に特化して勉強したりがしづらく、かつある領域がめちゃくちゃできるって状態にはなりづらい。その結果、スキルがあまり向上しないから玉拾い的な仕事からなかなか抜け出せない(会社的にはそういう人を求めていたと思うけど)。
- 事業立ち上げたばっかのスタートアップが故に気軽に失敗ができる環境ではなく、大きな仕事をなかなかできなかった(これに関しては自分の仕事の実力にも原因があるけど)。
- バックエンドにこだわりを持ってレビューしてくれるのは嬉しかったけど、フロントエンドのcssとかhtmlに関しては興味なさすぎてもうええやん何回レビューやり取りすんねん、こだわり強すぎんねんって感じだった。
- テックリードの方と2人でやっていたけど、圧倒的な実力差があったり、相性が悪いと2人は辛いなと感じた。コミュニケーションを取りたいと思わないけど、難しい機能を任せられる、でも作った成果に対してはモチベーションが上がったりしないのですごい負のループだった。いろんな人に聞けたり、相性が良いと良いんだろうなと感じた。
- どのようなキャリアパスを目指せる会社なのかはめちゃ大事。バックエンドが専門的にできるようになったりクラウドインフラがめちゃくちゃできるようになったり、割とそっちに関心があるからそこを目指せる会社に行った方が良い。
- この時はフロントエンド5割、バックエンド5割くらいでやってたかも。入った当初はどっちもやりたかったんだけど、入って半年くらいしてから、バックエンドメインでやりてええと思うようになって、そっからフロント嫌だなと思うようになったのかもしれない。
前々色職(SaaS系事業)
どんな成果を出す必要があったか
- ユーザーや会社が求めている機能を、CEOやCTOと仕様を相談した上で、フロントエンド ~ バックエンドを通して実装すること
その成果は自分のモチベーションを上げてくれたのか
- 正直機能を作れても、成果自体にはあまりモチベーションを感じなかった。やっとできたって感じ。
- 成果というか、修羅場を乗り越えてきたCTOにレビューをしてもらいながら、自分が成長しているんだって感じることにモチベーションを感じていたのかもしれない。
- だんだんと難しいタスクに挑戦できることが嬉しかった。あの時はフル出社だったしコードを書くことに専念できたから、良くも悪くもサポート体制は充実していたと思う。CTOもこれはどっちでもいいよねってところに関してはフラットにレビューしてくれるし、優しく教えてくれるのですごいやりやすかった。
成果を出す際のプロセスの業務において、どの業務が楽しかったか
- 初めてReact * TSとRailsで難しい機能(ページネーション)とかを実装できた時は達成感がすごかった。
- この時はフロントエンドを7割、バックエンド3割くらいのレベルでやってた。この時はどっちもやりたかったので、どっちもできてよかった。
成果を出す際のプロセスの業務において、どの業務がつまらなかったのか(または不満だったのか)
- 割とビジネス色が強いエンジニアで実装できれば良しみたいなタイプだったので、コードがめちゃくちゃ汚かった。故にそれを読むのが辛かった。これサービス成長したら絶対リファクタリング必要だし、てか拡張性あるの?っていう話。
- ビジネスを進めることに重点が置かれていたので、拡張性を意識したコードを書いたり、TDDに乗っとてテストを書くみたいなのはなかなか教えてもらえなかったし、会社がそれを重視していなかった(テストを書かない文化の会社だったので、デグレしまくりだった)。
- 社長が論理的すぎて、一緒にやってて辛いなと思っていた。ただ、フル出社で顔が見える分まだ怖くはなかった。フルリモートで論理的で顔が見えないとまじで何考えているか分からなくて、怖いよ。その人のテンションも見えづらいし。
- 最後ら辺リサーチャー業務をやっていたので、エンジニアじゃなくね?と思ってモチベーションダダ下がりしていた。
- 事業を前に進めようって話をよく聞いていたけど、そこに全く興味がなかった。まずはエンジニアリング力を磨きたいってのが本音だった。
- 給与がめちゃ低いし、昇給の幅も小さかったので、そこもモチベーションが落ちる原因の一つだったと思う。
前々前職(クレジットカードの金融系事業)
どんな成果を出す必要があったか
- システムを安定的に稼働させるために、インシデントが発生したら保守すること
- 議事録を書く
- 庶務(ゴミ捨てや備品補助の注文、手紙配達や出力シートを整理して配布すること)を全うすること。
その成果は自分のモチベーションを上げてくれたのか
- 全くあげない。成果自体にモチベーションは上がらんし、成果を出すプロセスの業務もめっちゃつまらんかった。
- IT企業に入ってコードを書きたかったのに、そことは全く違う部署に入れられたのでそもそも問題があった(配属ガチャは大企業を選ぶ際のデメリット、ただ大企業は人の質は良いと思う。同期や先輩はすごい良い人ばかりだった、ただ業務がつまらなかった)。
- てかそもそも自分がどんな仕事をしたいのかもまだ定まってなかったし、その時は彼女がいて彼女と一緒に楽しく人生送れればいいなって甘い考え方をしていたので、そこにも問題があると思う。結局人生の大半の時間は仕事なので、仕事が楽しくなかったり自分がやりたいことではないとそもそも自分の人生を楽しいと思えないし、その分を彼女との楽しい時間で補おうとすると余計彼女に執着して良くない関係になってしまう。自分は、自分のやりたい仕事をやらなくても、プライベートを充実させて嫌いな仕事でも適当にやろうと考えることができる人間ではなかったんだな、自分の人生を向上させたいなら、自分のやりたい仕事をやる必要があるんだなとそこで実感した。
成果を出す際のプロセスの業務において、どの業務が楽しかったか
- 楽しい業務はなかったが、強いていうなら、SQLのプログラムを作ってた時が楽しかった。
成果を出す際のプロセスの業務において、どの業務がつまらなかったのか(または不満だったのか)
- 庶務や議事録に関しては、なんでSEとして入ったのにこんなことやる必要があるんだよという気持ちが強かった
- 保守も、マニュアルが決まっていて、それ通りやれば解決するので、全然面白くなかった。不規則なタイミングでインシデントが出るから夜に急に対応したりして、インシデントに人生振り回されている時間が無駄すぎて嫌だった。
- 新しいツールの導入に反対するような保守的な文化だったので、そこもあまり自分にあってないなと感じた。新しいツール導入すればもっとコミュニケーションが潤滑になって仕事の生産性が上がるのにと思っていた。
- 割とめんどくさい仕事は後輩に押し付ければ良いやの精神の人が先輩に多くて、自分は、「根本的にこの庶務のプロセスがどうやったら楽になるか、またどうやったら庶務をしなくて済むか考えようよ」ってタイプだったので、全く合わなかった(議事録書くのが嫌すぎて、課長に議事録を楽にするツールを提案して、導入してもらえたのは良い思い出)。
- 企業文化が保守的だと、保守的な人が集まる。その人たちは変化を恐れるタイプだと思う。まあめんどくさいのは分からなくはないが、実際にやっている身としては嫌だった。生産性はどんどん向上させた方が良い。
仕事をしていた際の反省点
前職を通して、「毎日運動する」、「健康的な食事を摂る」、「仕事が終わったら仕事のことは一切考えないで別のことを考える」を実践すれば良かったなと思いました。
「毎日運動する」を選んだ理由としては、運動すると運動することに必死になって考えることをやめようとするのが良いなと感じたためです。あと体力がないと長時間仕事したりするのが辛くなるので、運動は継続してた方が良いなと感じました。
「健康的な食事を摂る」を選んだ理由としては、食事は自分自身のモチベーションを上げてくれたり、体の体調が良くなったりして、結果的に仕事のパフォーマンスに直結するためです。
「仕事が終わったら仕事のことは一切考えないで別のことを考える」を選んだ理由としては、仕事が終わったら仕事のことは一切考えない方が、メリハリが効くし、視野が狭くなって思い詰めなくても良いためです。仕事以外に必ず楽しいイベントだったり、仲良い人と話す時間を週に1回は作った方が良いなと思いました。あと運動している間も仕事のことを考えなくて済むので、運動も良いなと思いました。
転職の思考法を読んで今の自分のフェーズにあってそうだなという考えをまとめる
市場価値について
市場価値の高い人は、ざっくり以下の傾向がある
- 会社を変えても価値のあるスキルを持っている
- つまり世の中の流れに合っている技術を扱っている。
- そのスキルの賞味期限はいつまでか
- 他の会社でも通用する「レアな経験」がどれだけあるか、その経験は世の中からどれだけ強いニーズがあるか。
- 社内に自分が会社を変えても喜んで力を貸してくれる人がどれだけ存在するか。
- 自分が所属しているマーケットに今後の「成長性」はあるか
- 今後、どれだけ「自分の市場価値」は成長が見込まれるか?
どうやって市場価値を高めていくか
- 20代は専門性、30代は経験、40代は人的資産でキャリアを作れ。
- 専門性があるから、難しい貴重な経験ができる仕事が降ってくる。人的資産はほどほどにしつつ20代で専門性と経験は欲しい。P.39に書いてあった
会社選びの3つの基準
- 市場価値は上がるか
- 働きやすいか
- 活躍の可能性は十分か
- 「働きやすさ」は「市場価値」と相反しない。むしろ長期的には一致する。
活躍の可能性を確かめる3つの質問
- どんな人物を求めていて、どんな活躍を期待しているのか。
- 今一番社内で活躍して、評価されている人はどんな人か?なぜか?
- 自分と同じように中途で入った人物で、今活躍されている人はどんな社内パスを得てどんな業務を担当しているか。
会社を見極めるポイント
- 次の会社は長く勤めたいので、一番長く時間を過ごす現場のメンバーと会う会をセッティングしてもらうようリクエストした方がよい。
- 同業他社からの評判は悪くないか。
新卒で入るべき会社と中途で入るべき会社の違い
- 中途を活かすカルチャーはあるか
- 役員が新卒出身者で占められている会社は要注意。
- 自分が行きたい会社の商品やサービスに触れてどこが好きなのかをメモする
- そうか、エンジニア組織に強みを持っている会社だと、エンジニアが裁量権を持ちやすいってことか。
- どんな人材でも回るビジネスモデルかどうか
- 転職する側からすると、市場価値が上がりづらいケースが多い
転職後の給料について
既に給料が高い成熟企業と、今の給与は低いけど今後の自分のマーケットバリューが高まる会社とで悩むなら、迷わず後者を取った方が良い。マーケットバリューと給与は長期的には必ず一致する。
being型
being型は、「どんな人でありたいか、どんな状態でありたいか」を重視する人。自分は確実にそっちやな。
being型にとって重要な2つの状態
仕事をRPGとして考えるとわかりやすい。
- 自分の状態(主人公は適切な強さか)
- 自分の状態を強めたいなら、自分の仕事の面における市場価値を高めた方が良い。
- その上で、仕事でつく嘘を最小化する(いくらマーケットバリューが高まり、自分が強くなっても自分を好きでなければ、仕事(ゲーム)を楽しむことはできない)
- 環境の状態(自分を成長させるいい緊張があるか)
- より難しい業務をやったり、やったことのないことに挑戦できている。
being型の人間が好きなことを見つける方法
小さなやりたいことを以下の方法で探す。
- 他の人から上手と言われるが、自分ではピンとこないもの
- 普段の仕事の中で「全くストレスを感じないこと」
- css嫌いすぎるし、苦痛。レイアウト組むの面白いって思わないし、これ別にこういうレイアウトでもよくね?と人の感覚に左右されることがあるので、フロントエンドは絶対向いていない気がする(人生の時間の無駄だなと感じる)。何よりも解決する課題領域が少ない。例えばログイン機能を作ろうってなった場合、ログインページとログインフォーム、apiを叩くロジック、リダイレクトさせて、別の画面にいく処理くらい。 バックエンドだったら、テーブル設計、DBとの接続処理、メールを送信する処理、スラックに送信する処理、セッションを作る処理、ユーザーに適切なjsonを返す処理など、いろんなシステムが組み合わさって一つの機能を作っている。それが面白い。
自分にラベルをはれ
変えのきく存在から脱出したければ、自分の好きなこと、苦にならないことを「ラベル」にして貼れ。
- 自分の好きなこと、苦ににならないことって、なるとやっぱバックエンドとかクラウド領域か。
ラベルに書く内容は、理想が入っていても、まだできないことでも構わない。
ラベルをつけたら、「そのラベルがより強固になるか」という判断軸で仕事を選んでいくこと。
転職における失敗とは何か
- 選択が失敗かどうかは、あくまで事後的にしかわからない。失敗につながる唯一の条件は、「覚悟を決める時に覚悟を決められないこと」
- 転職を阻害するのは、現実的な危険性ではなく、ほとんどが見栄か恐怖
このラベルを貼るって考え方良いなと感じた。自分がバックエンドやサーバー、クラウドインフラ周りの専門家ってポジションを気付きたい。そこが一番苦にならず、楽しいって感じるから。
自分の就活の軸とは
これらを踏まえて、自分の思考には以下の傾向があるなと感じました。
- バックエンド(Rails, Rspec, AWS, terraform, MySQL)を専門的にやりたい
- てことはバックエンドのポジションに応募するのは大前提か
- クラウド系やDB、パフォーマンスチューニングの領域にも幅を広げていきたい。
- 開発メンバーやCSメンバーの生産性が上がるような施策をサクッと実装できたら、意外と結構嬉しいかも。
- バックエンドのポジションで成果を出せたら結構楽しい気がする。バックエンドの業務自体が楽しいから。
- 心理的安全性が欲しい
- 具体的には、失敗しやすくてチャレンジしやすい環境か、ビジネスと開発組織がある程度分かれていて、バックアップ体制は存在するのか。
- 少なくとも開発組織は8人くらい欲しい。バックエンドできる人は最低でも2~3人欲しい(1人だとその人に依存してしまう)。
- おただやかな人が多い方が良い。理詰めで物事語りすぎる人はいないで欲しい。
- お互いを尊重して、発言がしやすいエンジニアチームになっているか、
- 具体的には、失敗しやすくてチャレンジしやすい環境か、ビジネスと開発組織がある程度分かれていて、バックアップ体制は存在するのか。
- できればテストやOpenAPIを書いている環境であってほしい。
- 優秀でかつ優しい人からレビューをもらいたい。
- コードとは関係のない仕事、自分の成長とは関係のない仕事はやりたいない。
- できればDoor to Doorで1時間超えて欲しくない。
- コードは綺麗であって欲しい。読むから。
- 給与は420以上が良い。
- 一緒にやるメンバーが論理的すぎない。長期的な視点を持つとやりづらいから。
- 開発組織がうまく確立されていて、ビジネスを前に進めようって意識を開発メンバーが持たなくても済むか。
- バックエンドとクラウド領域を磨けるか。
- terraformとAWSを使ってたら直よし。
- てか長期的に働ける会社が良い(最低でも2年)
- 今は事業を作っていくより、エンジニアとして成長したい。そこがあっている会社が良い。
- プロダクトを重視する考え方はあんまやめた方が良い。それよりも大事なものはいっぱいある。フリーランスになったらプロダクトはどうでも良くなるから。そこに楽しみを持ってはあかん。もっと技術寄りな部分が好きだと思う。目的はプロダクトの向上だけど。プロダクトってそれくらい。だから、そこをメインにしてはあかん。
- コードを書きたいと言うか、課題を解決できるようなコードを書きたい,
全部が全部揃ってなくても良いんですけど、
- バックエンド領域を専門にやれて、クラウド系やDB、パフォーマンスチューニングの領域にも幅を広げられる
- 心理的安全性がある。失敗がしやすい。自分よりできるバックエンドエンジニアが2 ~ 3人いる
- テスト書いてる(OpenAPI書いてたら直よし)。
ここら辺が揃ってたら全然ありな会社だなと思います。この3つを軸にしていこうと思います。 そう考えるとフルスタックの求人とかを応募すると、自分のやりたいこととは合わないかもね。フェーズはめちゃくちゃ大事。 プロダクトとかは正直どうでも良くて、自分のラベル(バックエンド、サーバー、アプリやテーブル、インフラアーキテクチャの設計、クラウド、パフォーマンスチューニングの専門家)を伸ばせるような環境なのかを重視している気がします。
転職面接の際にしたい質問
- どのようなキャリアパスを目指せる会社なのか?
- どんな人物を求めていて、どんな活躍を期待しているのか。
- 今一番社内で活躍して、評価されている人はどんな人か?なぜか?
- 自分と同じように中途で入った人物で、今活躍されている人はどんな社内パスを得てどんな業務を担当しているか。
- テストを書いているか
- (terraformやOpenAPIを導入していない場合) terraformやOpenAPiなどのツールは導入しても良いのか
- ジュニア、ミドル、シニアの割合はどのくらいか。リードはいるのか
- 開発組織や開発メンバーの雰囲気はどんな感じか。
もし受かったらしたい質問
- 実際のメンバーと会う会をセッティングしてほしい。
終わり
自分は結構、「尊敬する人やすごい人たちと事業の立ち上げに0から関われる、先の見えない感じが楽しそう」って思って直感的に会社を決めていたけど、それって「求められる成果が何なのか、その成果は自分のモチベーションを上げてくれるものなのか、またその成果を出す際に取り組む業務は自分にとって楽しいのか、やりたいことなのか」等の自分が実際にやる仕事を具体レベルまで落とし込んで考えられていないんですよね。そんな直感で選んでしまったことを今は反省しています。
事業自体に直感的に面白さを感じるのは別に良いですが、実際に自分がする業務はその事業を成立させるための一部の仕事なわけであって、その一部である仕事の成果に対してモチベーションが上がったり、その成果を出す際のプロセスの業務に面白さややりたいって感じないと、結果的に自分のやりたいことと違ってしまい、モチベーションが下がってしまったり、この仕事やりたくないなと思ってしまうんですよね。そのため、事業はよっぽど嫌いでなければ、もはやなんでもよくて、むしろ自分がどんな仕事を担当するのか、どんな環境なのか、ある程度バックアップ体制が整っていて失敗に許容かに重点をおいた方が良いのかなと、自分は割とそっちのタイプなのかなと思いました。
実際に自分がするのは事業を成立させるための一部の仕事なので、「その仕事の中でも、モチベーションが上がる成果はなんなのか、その成果を上げるためのプロセスの業務は楽しいと思えるなのか」その時間を最大化した方が良いです(おそらく)。次はそこを考えてから、会社を受けてみようと思います。
以上です。
参考記事
Basic認証についてざっくりまとめる
目次
- 目次
- 概要
- Basic認証とは
- Basic認証とよくあるフォーム認証との違いとは
- Basic認証とフォーム認証の認証フローを比較してみる
- Basic認証の問題点
- Basic認証を実装してみる
- 動作確認
- 終わり
- 参考記事
概要
Basic認証とフォーム認証の違いをあまりよくわかっていなかったので、まとめます。
Basic認証とは
Basic認証とは、HTTPのプロトコルに標準で用意されている認証方法の1つです。Basic認証を導入している場合、Basic認証が必要なページをリクエストすると、ブラウザがフォームのポップアップを自動で表示してくれます。そこで正しいユーザー名とパスワードを入力して認証に成功すると、ページを表示できます。認証に失敗した場合、再度フォームのポップアップが表示されます。
HTTPがステートレスなプロトコルなので、Basic認証はステートレスな認証方式であると言えます。Basic認証では一度認証が成功すると、HTTPリクエストのたびにAuthorizationヘッダを用いて認証情報を送っています。そのため、HTTPのようなステートレスなプロトコルでもステートフルな通信ができます。Basic認証では、従来のフォーム認証のようにサーバー側でクライアントの認証状態を保持したりしません。ゆえに、Basic認証はステートレスな認証方式であることが分かります。
Basic認証では、認証情報がブラウザに保存されるそうです。 また、一度ブラウザを閉じてしまうと認証情報が破棄されるので、再度Basic認証が必要なページをアクセスする場合、また認証情報を入力する必要があります。
Basic認証とよくあるフォーム認証との違いとは
いくつかの観点で違いがあるので、まとめます。
ステートレス、ステートフルについて
Basic認証はHTTPリクエストのたびに認証情報を送っているので、ステートレスな認証方法です。 フォーム認証では、HTTPリクエストのたびにクッキーを送っていますが、サーバー側でクライアントの状態をセッション情報として保持しているので、ステートフルな認証方式です。
認証フォームについて
Basic認証の認証フォームは、ブラウザによって自動で表示されるものです。 フォーム認証のフォームは、HTMLのフォームです。そのため、自分でHTMLを用いてフォームを作る必要があります。
認証情報の保持について
Basic認証ではブラウザを閉じたら認証情報が消えます。 フォーム認証では、ブラウザを閉じても、クッキーにsession_idが存在して、サーバー側にセッション情報が存在していてれば、ブラウザを再度開いても認証状態を維持できます。
認証情報の有効範囲について
Basic認証の場合、http://example.com/basicでBasic認証をした場合、/basic以下のリソースをリクエストする際に、ブラウザが自動的にAuthorizationヘッダを付与してくれます。 そのため、http://example.com/basicでBasic認証をした場合、http://example.com/basic/sampleがBasic認証を必要とするリソースだとしても、リクエスト時にブラウザが自動でAuthorizationヘッダを付与してくれるので、認証フォームに入力しなくてもhttp://example.com/basic/sampleのページを閲覧することができます。
フォーム認証の場合、ログインフォームで認証が成功すれば、あとは認証が必要なページは全て見ることができます。Basic認証のようにあるリソース配下のリソースしか見れないという制約はないです。
ユーザー情報について
Basic認証も、フォーム認証も事前にユーザー情報を登録しておく必要があります。登録フォームでユーザー情報を登録すれば良い話なので、ここはあまり差がないかなという印象です。
ログアウトについて
Basic認証にはログアウトという機能はありませんが、フォーム認証にはログアウトという機能があります。Basic認証でログアウトをしたい場合、一度ブラウザを閉じて認証情報が破棄する必要があります。
Basic認証とフォーム認証の認証フローを比較してみる
1.クライアント(ブラウザ)がBasic認証が必要なページをリクエストする。
GET / HTTP/1.1
2.サーバーは、Basic認証の必要性を表すHTTPレスポンスを返す。Basicの部分はauth-schemeと呼び、認証方式を指定する。
HTTP/1.1 401 Unauthorized WWW-Authenticate: Basic realm="Private page"
3.それを受け取ったクライアントはフォームのポップアップを自動で表示する。
4.フォームのポップアップにusernameとpasswordを入力して送信するボタンを押す。この送信するボタンを押したタイミングで、クライアントはusernameとpasswordを読み取って、username:passwordをBase64でエンコードしたものをHTTPヘッダのAuthorizationヘッダに含めて、サーバーにHTTPリクエストする。
GET / HTTP/1.1 Authorization: Basic YWxhZGRpbjpvcGVuc2VzYW
5.サーバー側ではそのAuthorizationヘッダに指定してあるエンコードされているデータが、サーバー側で事前に登録してあるユーザー情報と一致するかをチェックして、もし一致するなら、認証後のページを返す。一致しないなら、再度フォームのポップアップをブラウザに表示させるようなHTTPレスポンスを返す。
以下は、Basic認証の認証フローの画像です。

■フォーム認証
- HTMLのフォームに認証情報を入力する(メールアドレスとパスワード)
- フォームから送信された情報を元にサーバー側で認証をして、OKならサーバー側でセッションidとユーザー情報を紐づけてRedisサーバーに保存して、session_idという名前でvauleがセッションidであるようなクッキーを送信する。この時リダイレクトの指示も送る。
- クライアント(ブラウザ)側ではクッキーを受け取りつつ、リダクレイトの指示を受け取ったので、Locationヘッダに指定してあるパスにGETリクエストをする。この際、受け取ったクッキーも送信する(ブラウザが自動的に送信してくれる)。
- サーバー側ではクライアントから送信されたクッキーを元に、ユーザーのセッションが存在するかを確認する。もし存在するなら、サーバー側が認証後のページを送信する。存在しないなら、ログインページにリダイレクトさせる。
Basic認証の問題点
Basic認証ではフォームのポップアップから認証情報をサーバーに送る際に、username:passwordをBase64でエンコードしたものを送ります。このBase64は可逆なため、デコードしてユーザーのパスワードを取得することができます。Basic認証ではリクエストのたびにこれらの情報を送るので、盗まれるリスクも高いです。
以上の理由から、セキュリティリスクの高い場面では、Basic認証は避けた方が良いことが分かります。
Basic認証を実装してみる
Basic認証をGoで実装してみます。
実際のコードに関しましては、以下のリポジトリにまとめます。 github.com
実装した部分を一部抜粋します。
↓ ルーティング
var Routing = []*pattern.URLPattern{ pattern.NewURLPattern("/basic", middleware.CheckBasicAuthentication(controller.NewBasicAuthentication())), pattern.NewURLPattern("/basic/sample", middleware.CheckBasicAuthentication(controller.NewSample())), }
↓ ミドルウェア(ミドルウェアの中でBasic認証のメソッドを呼び出している)
package middleware import ( "github.com/yukiHaga/web_server/src/internal/app/controller" "github.com/yukiHaga/web_server/src/pkg/henagin/http" ) type CheckBasicAuthenticationController struct { nextAction func(request *http.Request) *http.Response } func (c CheckBasicAuthenticationController) Action(request *http.Request) *http.Response { if request.CheckBasicAuthentication() { // 次に渡す return c.nextAction(request) } else { // Authorizationヘッダーがないか、あるけどvalueが間違っている場合 // 再度Unauthorizedを返す response := http.NewResponse( http.VersionsFor11, http.StatusUnauthorizedCode, http.StatusReasonUnauthorized, request.TargetPath, []byte{}, ) // WWW-Authenticateヘッダーをセットする response.SetBasicAuthenticationHeader() return response } } // ミドルウェア // / ダミーコントローラとダミーアクションを作って、ダミーアクションの中で元々のコントローラのアクションを呼び出して、最終的にレスポンスを返せばOK // goではメソッドを書き換えるのはできなかった func CheckBasicAuthentication(c controller.Controller) controller.Controller { return CheckBasicAuthenticationController{nextAction: c.Action} }
↓ ミドルウェアで実行していたビジネスロジック(Basic認証に成功するかを判定するメソッド。このメソッド内でユーザー情報を保持しているけど、ユーザー情報はDBに保持する方式にしてもOK)
func (request *Request) CheckBasicAuthentication() bool { users := []*model.BasicUser{ model.NewBasicUser("yuki", "hogefuga"), } if authorizationHeader, isThere := request.Headers["Authorization"]; isThere { encodedData := strings.SplitN(authorizationHeader, " ", 2)[1] for _, user := range users { data := fmt.Sprintf("%s:%s", user.Name, user.Password) if base64.StdEncoding.EncodeToString([]byte(data)) == encodedData { return true } } } return false }
↓ Basic認証を満たさない場合に、WWW-Authenticateヘッダーをセットするためのメソッド
func (response *Response) SetBasicAuthenticationHeader() { response.SetHeader("WWW-Authenticate", "Basic realm=Secret Page") }
↓ コントローラ
package controller import ( "github.com/yukiHaga/web_server/src/pkg/henagin/http" "github.com/yukiHaga/web_server/src/pkg/henagin/view" ) type BasicAuthentication struct{} func NewBasicAuthentication() *BasicAuthentication { return &BasicAuthentication{} } func (c *BasicAuthentication) Action(request *http.Request) *http.Response { // ミドルウェアにおけるbasic認証を通過したので、認証が必要なページを見れる body := view.Render("basic_authentication.html") return http.NewResponse( http.VersionsFor11, http.StatusSuccessCode, http.StatusReasonOk, request.TargetPath, body, ) }
↓ モデル(Basic認証で使うユーザーを表すモデル)
package model type BasicUserId int64 // PasswordとConfirmationはRailsの家蔵属性として入っていたから、一応入れておいた type BasicUser struct { Name string Password string } func NewBasicUser(name, password string) *BasicUser { return &BasicUser{ Name: name, Password: password, } }
↓ 認証後に見れるページ
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8" /> <meta name="viewport" content="width=device-width, initial-scale=1.0" /> <title>Document</title> </head> <body> <h1>Basic認証を通過した人だけが見れるページ</h1> </body> </html>
動作確認
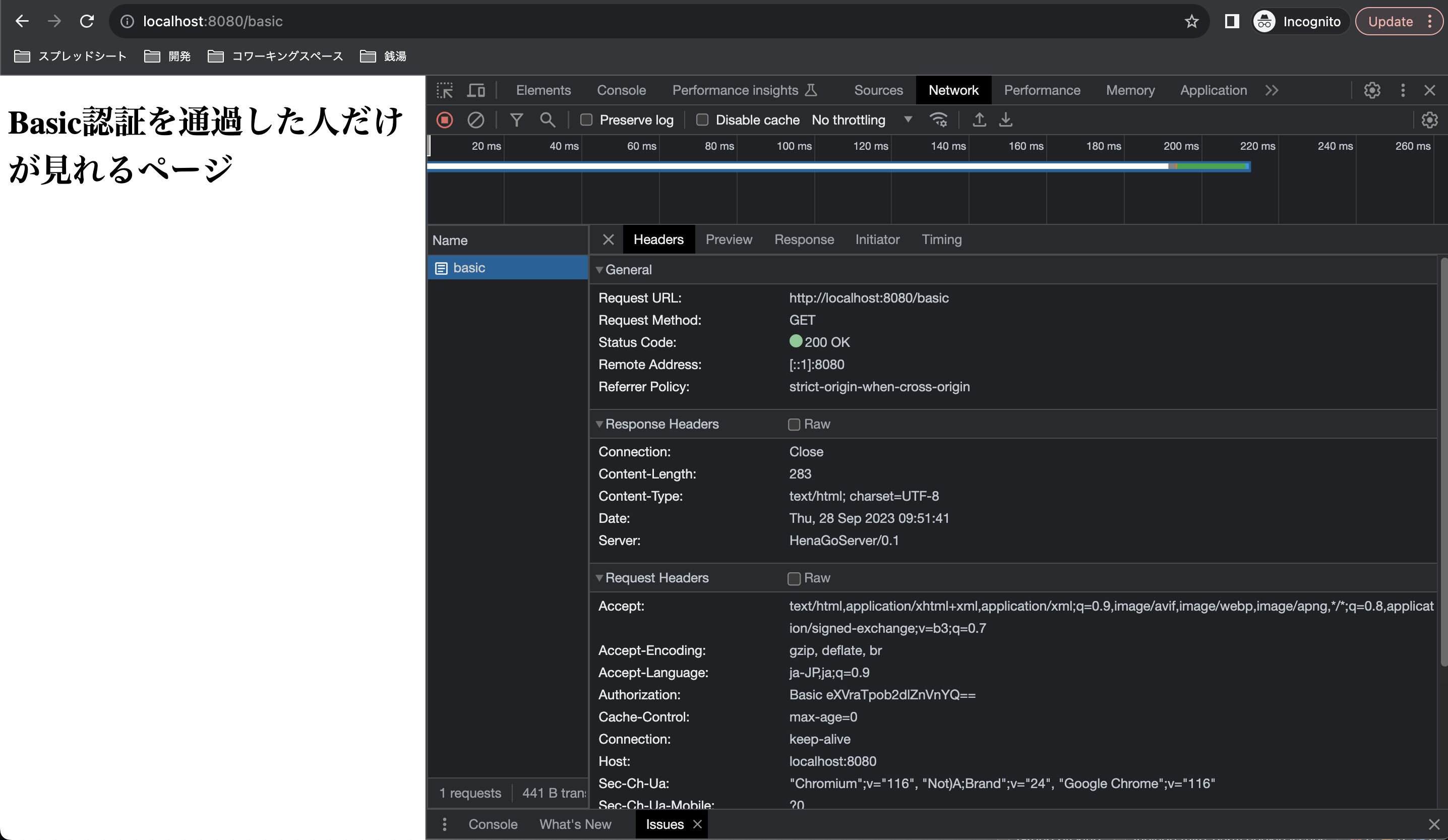
basic認証が必要なページをリクエストすると、サーバーがUnauthorizedをレスポンスして、それを受け取ったブラウザがフォームを自動で出してくれます。
不正な認証情報を入力してリクエストすると、サーバーは再度Unauthorizedをレスポンスして、それを受けとったブラウザがまたフォームを表示しています。
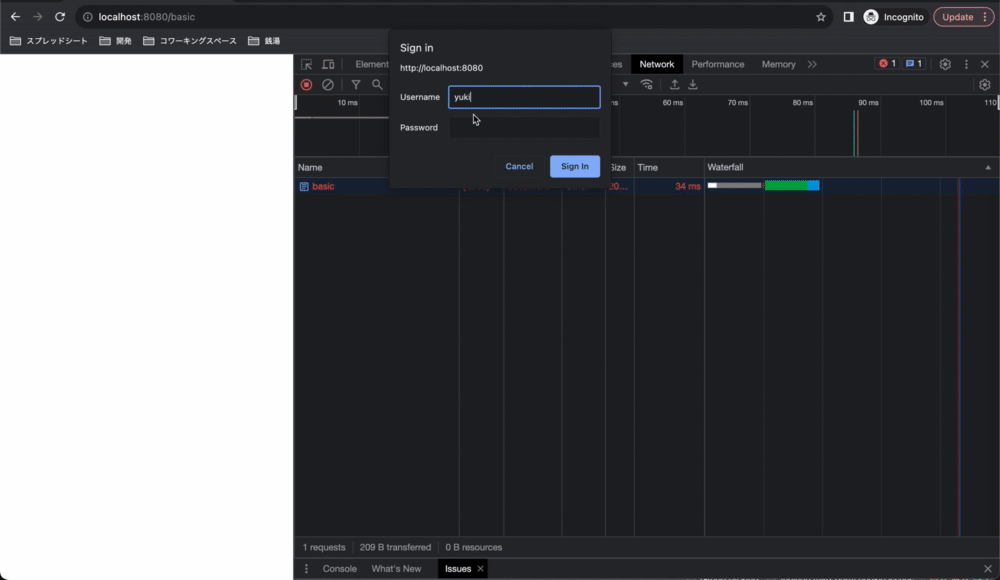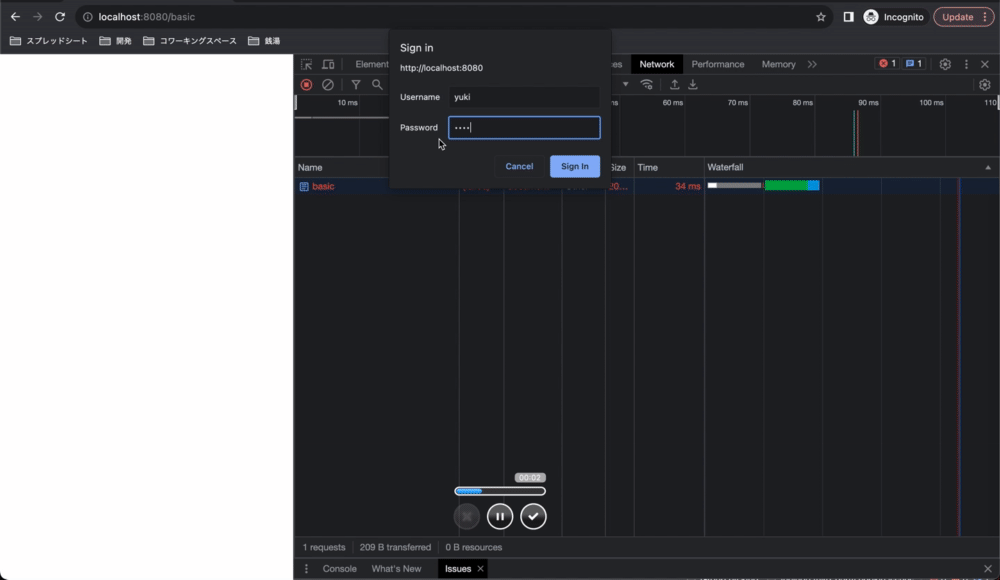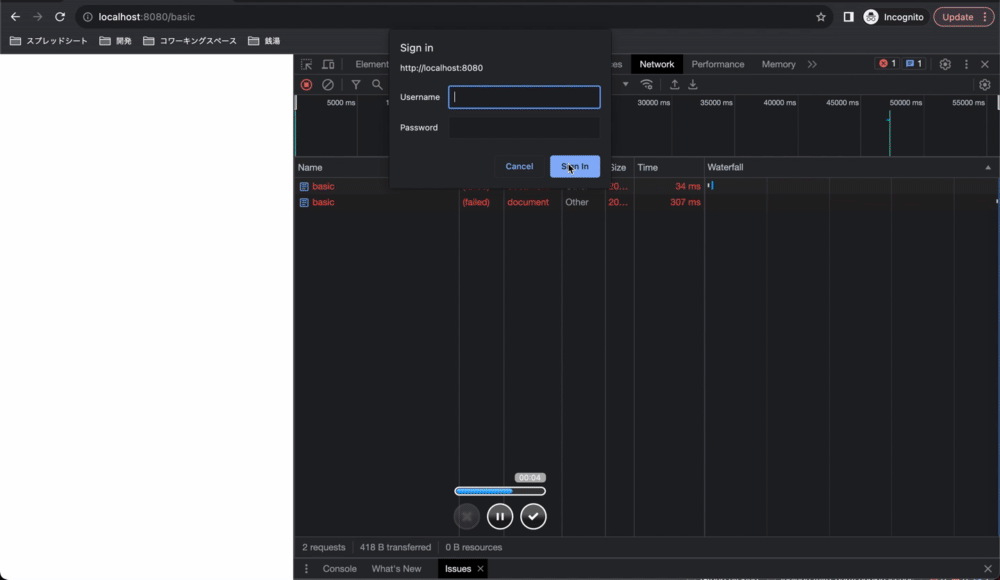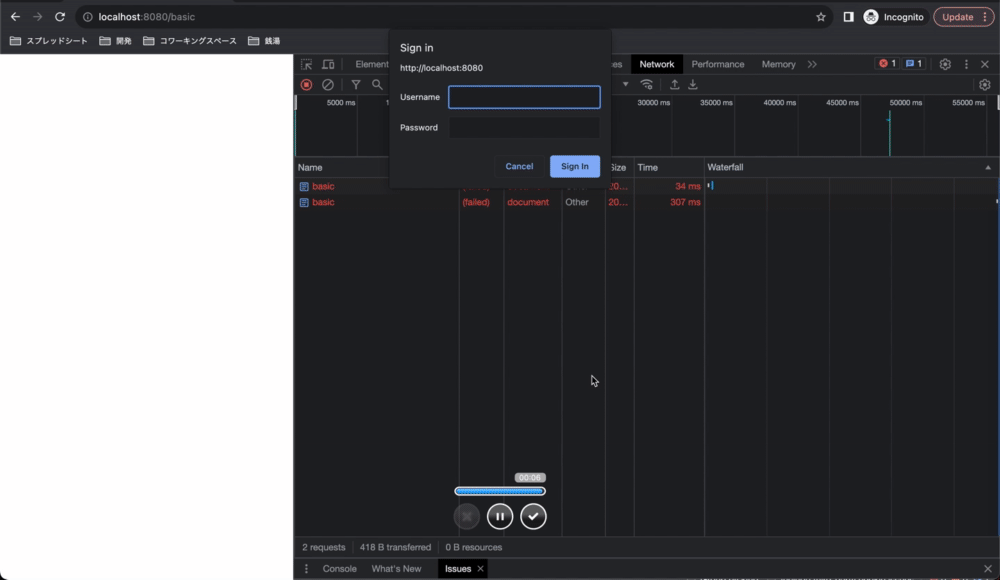
正しいusernameとpasswordを入力して送信を押すと、ブラウザがusername:passwordをBase64エンコードしたものをAuthorizationヘッダに含めてリクエストしてくれます。サーバー側で認証が成功すると、サーバーはリソースを送信します。
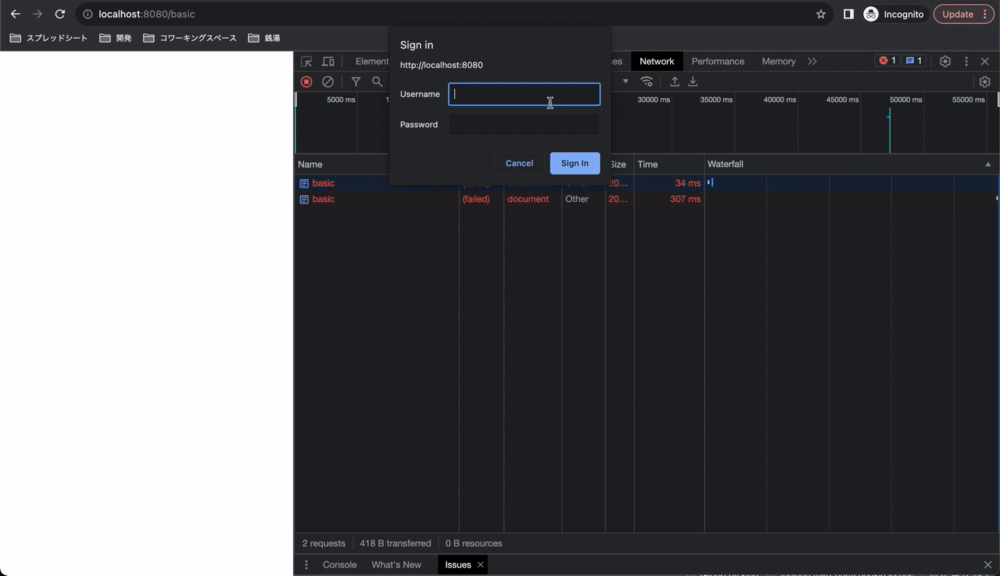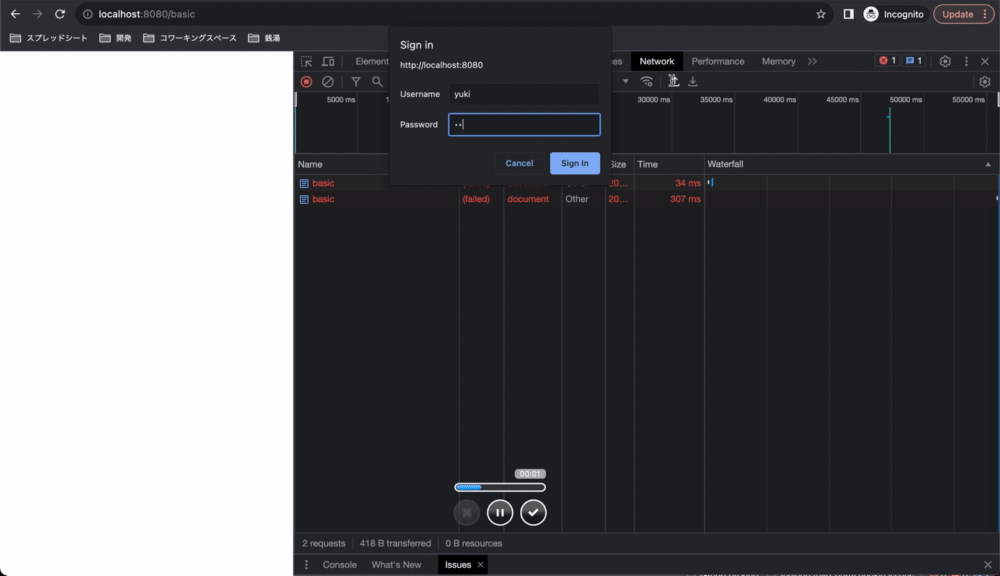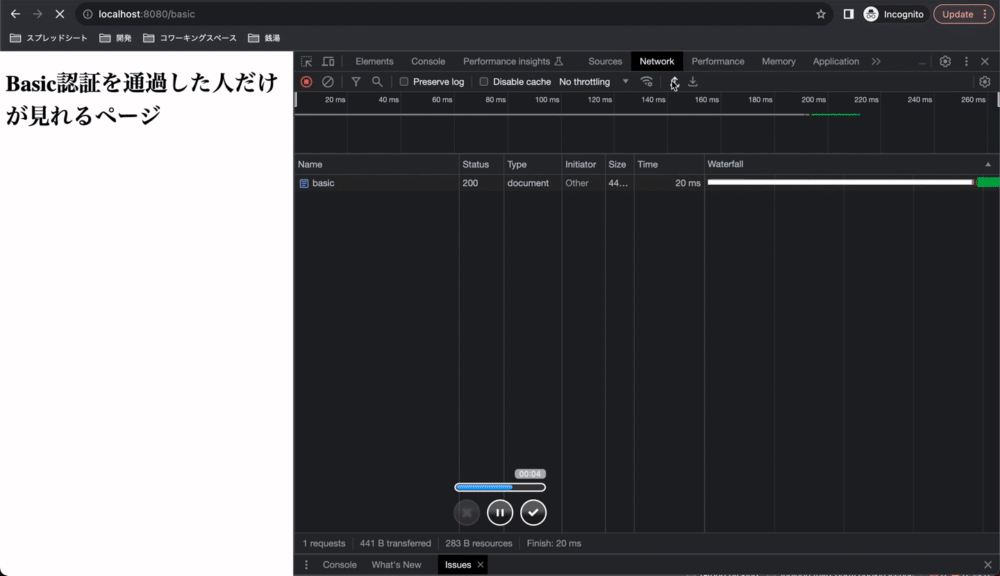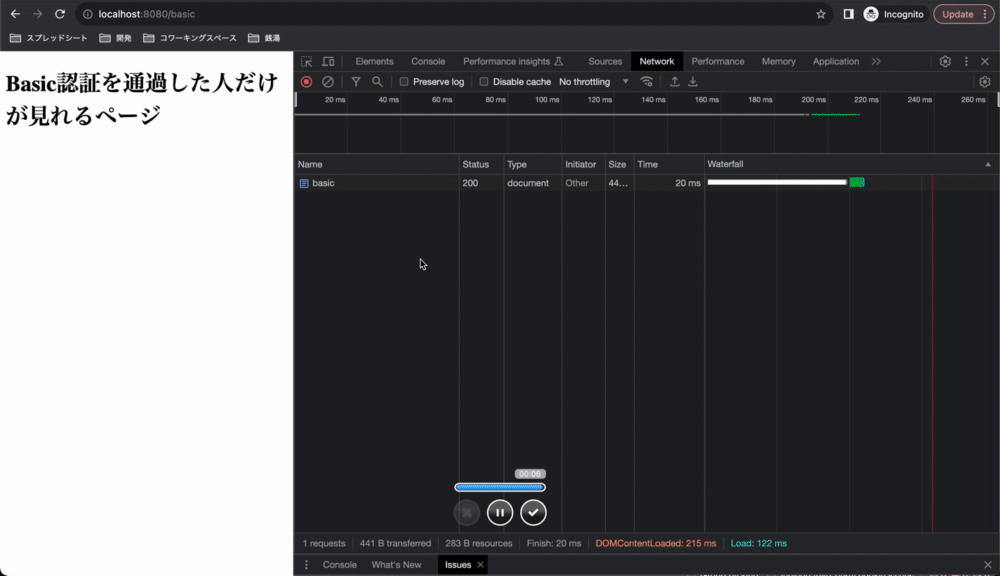
リクエストヘッダーに注目すると、一回でもBasic認証を通過した場合、ブラウザはリクエスト時に自動的にAuthorizationヘッダーを付与していることが分かります。
終わり
今回は自前でBasic認証を実装しましたが、ライブラリを使えばもっと簡単に早く実装できます。Basic認証は、社内ツールなどのセキュリティ要件が求められていないサービスだったり、ごくわずかな人にしか公開しないサービスには採用しても良いのかなと思いました。 (確かAWSのCognitoとかを使えば簡単に実装できた気がする)
次はBearer認証を実装してみます。
参考記事
Same-origin policyとCORSについてざっくりまとめる
目次
- 目次
- 概要
- Web開発における「リソース」とは
- オリジンとは
- オリジンへのネットワークアクセスについて
- Same-origin policyとは
- 別オリジンのリソースへのアクセスだけどSame-origin policyの制約がないものについて
- CORSとは
- CORSを利用する際のざっくりとした手順
- 別オリジンにHTTPリクエストをする際の2つのリクエストについて
- Same-origin policyやCORSが存在する理由
- ここまでのSame-origin policyとCORSについてのまとめ
- Same-origin policyを体験してみる
- CORSを体験してみる
- ここまでのまとめ
- 終わり
- 参考記事
概要
雰囲気でCORSを知っていたので、ちゃんと理解しようと思います。 CORSを知る前に知る必要がある概念については、事前にまとめておきます。
Web開発における「リソース」とは
RFC3986にリソースについて書いてあったので、見てみましょう。
リソース
本仕様書では、リソースとなりうるものの範囲を限定しない。 むしろ、"リソース "という用語は、URIによって識別されるかもしれないものすべて リソース "という用語は、URIによって識別されるかもしれないあらゆるものに対して一般的な意味で使用される。 よく知られている例 身近な例としては、電子文書、画像、一貫した目的を持つ情報源(例えば 例えば、電子文書、画像、一貫した目的を持つ情報源(例えば、"Today's weather report for Los Angeles の今日の天気予報 "など)、サービス(HTTP-to-SMSゲートウェイなど)、そ 他のリソースの集まりである。 リソースは必ずしも 例えば、人間、企業、図書館にある製本された本などである。 例えば、人間、企業、図書館の本もリソースになりうる。 同様に 抽象的な概念もリソースになり得ます。 同様に、抽象的な概念もリソースとなりうる。 (例えば、数学の方程式の演算子やオペランド、関係のタイプ(例えば、「親」や「従業員」)、数値(例えば、ゼロ、1、無限大)などである、 1、無限大)。
この説明を読んで、リソースとは、URLで特定できるWeb上で利用可能な情報やデータであることが分かりました。
オリジンとは
RFC6454にオリジンについて書いてあったので、見てみましょう。
3.2. 生成元( origin )
原理的には、 UA がどの URI も別々な保護ドメインとして扱って,ある URI から検索取得された内容と 別の URI とのやりとりに,明示的な同意を要するようにすることもできる。 あいにく、 web アプリケーションは,協同して動作するいくつものリソースからなることが多いので、この設計は開発者には厄介なものになる。 代案として,UA は、 URI たちを, “生成元” と呼ばれる保護ドメインにひとまとめにする。 大雑把に言えば、 2 つの URI は,それらが同じ[スキーム, ホスト, ポート]を持つならば,同じ生成元に属する(すなわち,同じ主体を表現する)。 (全部的な詳細は § 4 を見よ。)
UA(この場合だとブラウザ)がどのURIも保護すべきものとして扱ってしまうと、あるURIから取得されたリソースから別のURIでリソースをリクエストする際に、明示的な同意を要する必要があります。これは複数のリソースからなることが多いWebアプリケーションにとっては厄介なものです。
そのため、UAは、URIたちをオリジンと呼ばれる保護ドメインにまとめました (保護ドメインとは、コンピュータシステムやソフトウェアにおいて、特定のセキュリティポリシーを持ち、そのポリシーに基づいてアクセス制御やリソースの保護を行う単位である)。
2つのURIは、同じ「スキーム、ホスト、ポート」を持つならば、同じオリジンに属します。
つまり、オリジンとは、リソースの生成元を表す保護ドメインであることが分かります。 オリジンは、「スキーム(プロトコル)、ホスト(ドメイン)、ポート」によって構成されています。
あるホスト上のアプリケーションが別のホストのアプリケーションとtcp通信をする際に、ipアドレスとポート番号が必要なので、オリジンの概念もそれと近しいものだなと個人的に思いました(オリジンの場合はプロトコルも関係している)。
オリジンへのネットワークアクセスについて
RFC6454にオリジンへのネットワークアクセスについて書いているので、見てみましょう。
3.4.2. ネットワークアクセス
ネットワークリソースへのアクセスの可否は、[ そのリソースは、アクセスを試みている内容と同じ生成元に属しているかどうか ]に依存する。 一般に、別の生成元から情報を読み取ることは禁止される。 しかしながら,一部の種類のリソースを利用することは、他の生成元から検索取得する場合でも許可される。 例えば生成元には、どの生成元からの[ スクリプトを実行する/画像を描画する/スタイルシートを適用する ]ことも許可されている 【この文書が書かれた頃までは — 現在はもっと制約されている】 。 同様に生成元は、 HTML のフレーム内の HTML 文書など,別の生成元からの内容を表示できる。 ネットワークリソースには、他の生成元に自身の情報を読み取らせるオプトインを備えるものもある — 例えば Cross-Origin Resource Sharing [CORS] を利用して。 これらの事例でアクセスが是認されるかどうかは、概して生成元ごとに基づく。
これを見る限り、あるオリジンに所属するリソースが同じオリジンに所属するリソースに対してHTTPリクエストを出すのは問題ないことが分かります。そして、あるオリジンに所属するリソースが別のオリジンに所属するリソースに対してHTTPリクエストを出すのは禁止されているということが分かります。
Same-origin policyとは
先ほどの説明を読む限り、オリジンという概念が導入されたおかげで、全てのURIを保護すべきものだと考る必要がなくなり、オリジン単位でURIを保護することが可能になりました。そして、あるオリジンに所属するリソースから同じオリジンのリソースに対してリクエストを出すのはOKだけど、あるオリジンに所属するリソースから、異なるオリジンのリソースに対してリクエストを出すのはNGであること分かりました。 もし実際に異なるオリジンのリソースに対してリクエストを出した場合、ブラウザがSame-origin policyによってリクエストを自動的に禁止してくれます。
Same-origin policyとは、異なるオリジンのリソースに対してのリクエストをブラウザ側で制限することです。
別オリジンのリソースへのアクセスだけどSame-origin policyの制約がないものについて
あるオリジンのリソースから別のオリジンのリソースにアクセスする際に、Same-origin policyの制約がないものが存在します。
Same-origin policyの制約があるもの
- ブラウザ上でJavaScriptを用いて実行する非同期HTTPリクエスト
Same-origin policyの制約がないもの
- formタグ
- scriptタグ
- img タグ
- linkタグ
これらの要素(form, script, img, link)を使う際には、CSRFの対策ができているかをよく確認しましょう。 RailsのformにおけるCSRF対策では、CSRFトークンが隠しフィールドで入っています。
CORSとは
Same-origin policyはブラウザのセキュリティを向上させます。しかし、AjaxやSPA構成のアプリケーションができなくなる等、他の問題を生みます(Next.jsとRailsがそれぞれ別オリジンの場合、今のままだとNext.jsからRailsにHTTPリクエストを出せない)。そこでSame-origin policyの制約を完全に無効にするわけではなくて、Same-origin policyの制約を緩和するためにCORSが導入されました。
CORSとは、相手側オリジンの許可を得ることで、相手側オリジンのリソースに対してのHTTPリクエストを可能にするプロトコルです。
CORSプロトコルは、HTTPレスポンスをクロスオリジンで共有できるかどうかを示す一連のヘッダーで構成されます。このHTTPヘッダーのおかげで、あるオリジンで動作しているウェブアプリケーションに、異なるオリジンにある選択されたリソースへのアクセス権を与えるようブラウザーに指示できます。
CORSを利用する際のざっくりとした手順
CORSには、「シンプルリクエスト」と「プリフライトリクエストを伴うリクエスト」の2パターンがあるのですが、ここではシンプルリクエストが実行される際の手順について説明します。
ブラウザはあるオリジンのリソースから異なるオリジンのリソースに対してHTTPリクエストを出す際に、HTTPリクエストメッセージにOriginヘッダを自動で追加してくれます(同じオリジンのリソースをリクエストする際には、ブラウザはOriginヘッダをリクエストに追加しない)。このOriginヘッダにはリクエスト元のオリジンが指定されています。リクエストを受けたサーバーは、レスポンスをする際にレスポンスメッセージにCORSに関するヘッダー(Access-Control-Allow-Origin)を含めていない場合、ブラウザはオリジンをまたいだリソースの利用に失敗します。
オリジンを跨いでリソースを使用したいなら、オリジンのリソースから異なるオリジンのリソースに対してリクエストが来た際に、サーバー側でHTTPレスポンスにCORSに関するヘッダー(Access-Control-Allow-Origin)を追加すれば良いです。これでCORSに関する設定は終了です。そうすれば、異なるオリジンのリソースにアクセスできます。
フレームワークを使っていれば、CORSに関するライブラリが使えるので、CORSに関するヘッダーを自分で設定する必要はなく、おそらく設定ファイルを使ってCORSに関する設定をすれば良いだけでしょう。
別オリジンにHTTPリクエストをする際の2つのリクエストについて
あるオリジンのリソースから異なるオリジンのリソースに対してHTTPリクエストを行う場合、実はそのリクエストは、ブラウザによって「シンプルリクエスト」 または「プリフライリクエストを伴うリクエスト」として解釈されて実行されています。
シンプルリクエストとは
シンプルリクエストは、以下の条件を満たすようなリクエストです。 これらの条件は、HTMLフォームから送られるリクエストを基準としています。
メソッドは下記のうちいずれかである - GET - HEAD - POST ユーザーエージェント(Webの場合はブラウザ)によって自動的に設定されたヘッダー (たとえば Connection、 User-Agent、 または Fetch 仕様書で禁止ヘッダー名として定義されているヘッダー)を除いて、手動で設定できるヘッダーは、 Fetch 仕様書で CORS セーフリストリクエストヘッダーとして定義されている以下のヘッダーだけである - Accept - Accept-Language - Content-Language - Content-Type(以下しか指定できない) - application/x-www-form-urlencoded - multipart/form-data - text/plain - Range その他 - リクエストに ReadableStream オブジェクトが使用されていないこと。
もし、ブラウザからシンプルリクエストが送信された場合、サーバーからのレスポンスにAccess-Control-Allow-Originヘッダーが付与されていて、かつそのヘッダーのvalueでリクエスト元のオリジンが許可されていれば、レスポンスのリソースを使用することができます。
レスポンスで付与するAccess-Control-Allow-Originヘッダで Origin リクエストヘッダのリテラル値 (nullとすることもできる) または* を返すことで、レスポンスをそのオリジンと共有できることをブラウザに伝えることができます。
プリフライトリクエストとは
プリフライトリクエストとは、サーバーがCORSプロトコルを理解して準備されていることをチェックするためのリクエストです。異なるオリジンにリクエストを出す際に、そのリクエストが「シンプルリクエストの条件」を満たさない場合に、プリフライトリクエストと呼ばれるHTTPリクエスト(リクエストメソッドはOPTIONS)が事前に送信されます。プリフライトリクエストは、ブラウザが自動的に発行するものです。シンプルリクエストができる場合は、プリフライトリクエストは発生しません。
プリフライトリクエストのレスポンスヘッダーを見て、サーバーにリクエストしても良いことが分かったら、ブラウザは元々のリクエストを別オリジンに対して自動的に送信します。そして、レスポンスを利用できます。
どうでも良いですが、preflightは「飛行前に起こる」という意味の形容詞です。つまり、プリフライトリクエストとは、「実際のリクエストが起きる前に起こるリクエスト」という意味であることが分かります。
Same-origin policyやCORSが存在する理由
もし、オリジンの制約がなく非同期リクエストが可能だと、罠サイトを作ってCSRFでやりたい放題できてしまいます(ユーザーのアカウントで全く別のサイトにリクエストを出したり機密情報を盗みまくれる)。 そのため、Same-origin policyを導入することによって、別オリジンからの非同期リクエストを制限しました。 しかし、Same-origin-policyだけだと制限が厳しくAjaxやSPAなどもできなくなるので、あるオリジンからのリクエストなら特別に許すというCORSプロトコルが導入されました。
補足) CSRFとは
CSRFは、サイト自体が攻撃者です。 CSRFとは、罠サイトから、あなたがよくつかうような全く別の他のサイトへのリクエストを開始し、意図しない「退会」や「決済」や「コメント」なんかを実行させるといった類の攻撃です。 jsにおける非同期リクエストでなくても、formやaタグでCSRF攻撃はできます。
CSRFの対処策としては、CSRFトークンをリクエスト時に必ず持たせるようにして、サーバー側ではクッキーの値とCSRFトークンの値が一致するかをチェックすれば良いです(CSRFトークンはバックエンドアプリで生成しておいて、リクエスト時にカスタムヘッダーに仕込んでおく)。
別オリジンのリソースからこのオリジンに対してリクエストされる時に、そのリクエストのどれかはCSRFの可能性があるので(バックエンド側は誰からリクエストが来たのかに関心がない)、認めたオリジンからのリクエストなのかをCSRFトークンまたはCORSでチェックする必要があります。
ここまでのSame-origin policyとCORSについてのまとめ
- リソースとは、URLで特定できるWeb上で利用可能な情報やデータである。
- オリジンとは、リソースの生成元を表す保護ドメインである。
- Same-origin policyとは、異なるオリジンのリソースに対してのリクエストをブラウザ側で制限することである。
- CORSとは、相手側オリジンの許可を得ることで、相手側オリジンのリソースに対してのHTTPリクエストを可能にするプロトコルである。
Same-origin policyを体験してみる
以下のリポジトリを元に進めます。
サーバー側はhttp://localhost:3030をオリジンとします。 フロントエンド側はhttp://localhost:8080をオリジンとします。
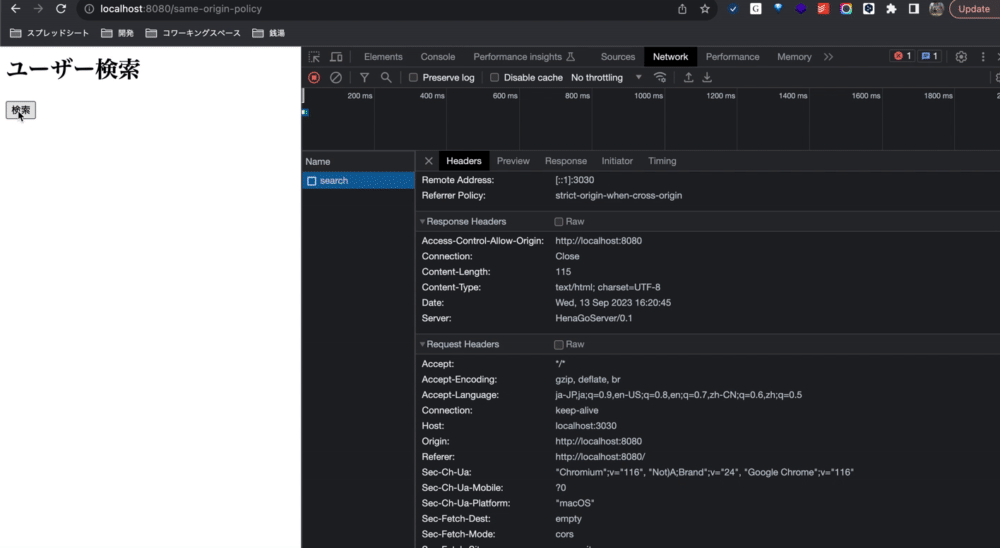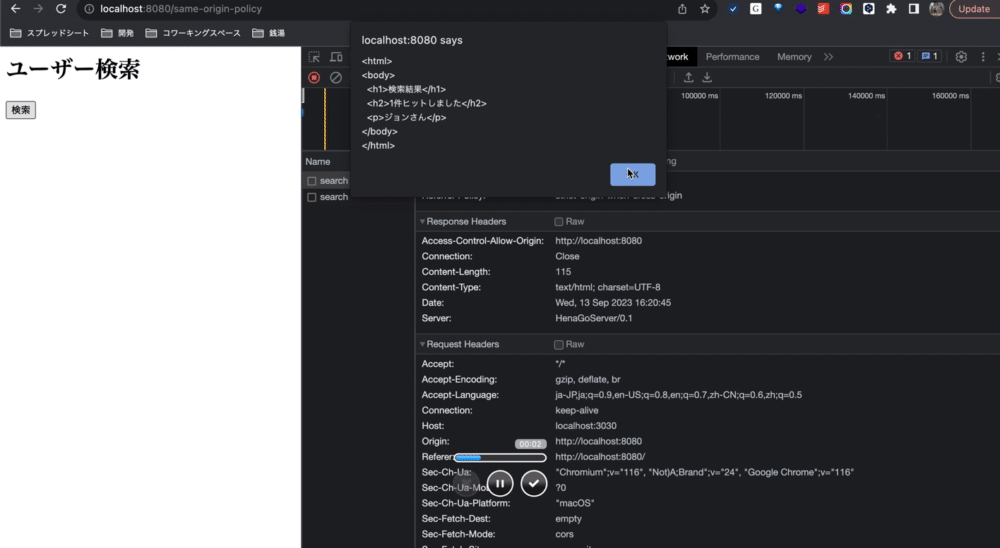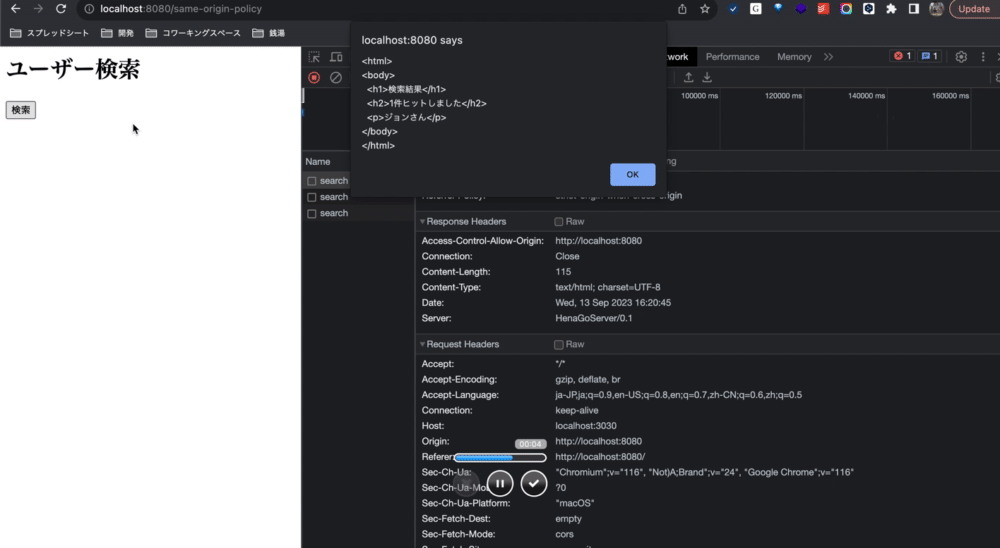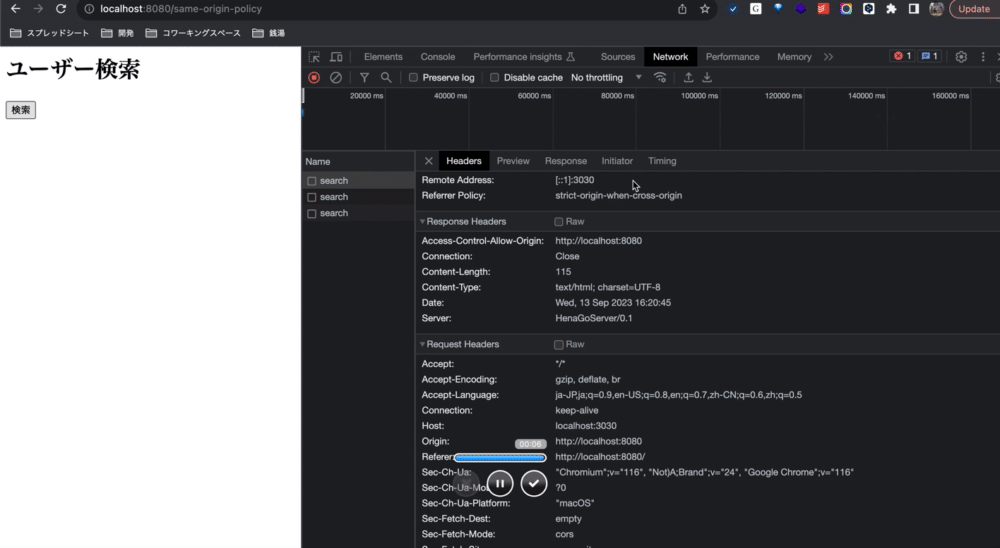
http://localhost:8080から配信された以下のようなhtmlから、jsで別オリジン(http://localhost:3030)のリソース(http://localhost:3030/api/users/search)に対してGETリクエストを出してみます。
<html> <body> <h1>ユーザー検索</h1> <!-- methodをgetにしちゃうと、ボディがクエリパラメータになっちゃうね。サーチくらいならまだ良いか。--> <!-- 自作サーバーにクエリストリングの処理を入れてないから、postにした。サーチは本来ならgetが良い。--> <button id="button">検索</button> <script> document.getElementById("button").addEventListener("click",() => { const request = new XMLHttpRequest(); // onreadystatechangeプロパティは、XMLHttpRequestオブジェクトの状態が変化するたびに実行される関数を指定します: request.onreadystatechange = () => { // readyStateプロパティが4で、statusプロパティが200のとき、応答はreadyである: if (request.readyState == 4 && request.status == 200) { alert(request.responseText); } } request.open("GET", "http://localhost:3030/api/users/search", true); request.send(); }) </script> </body> </html>
検索ボタンを押して、jsからHTTPリクエストを発火させようとしたら、Same-Origin-Policyによるエラーが出ました。
オリジン 'http://localhost:8080' から 'http://localhost:3030/api/users/search' の XMLHttpRequest へのアクセスは、CORS ポリシーによってブロックされました: 要求されたリソースに 'Access-Control-Allow-Origin' ヘッダーがありません。
要は、http://localhost:8080のオリジンのリソースから、http://localhost:3030のオリジンのリソースにアクセスしようとしたから、オリジン違くねとブラウザがこのエラーを出しただけです。
jsリクエストのリクエストヘッダーを見ると、ちゃんとOriginヘッダーを送っているのが確認できます。Originヘッダは異なるオリジンにリクエストを出す際に自動でブラウザがつけてくれるヘッダです。 Originヘッダには、リクエスト元のオリジンが指定されていることが分かります。

これらの検証から、Same-origin policyが実際に機能していることが確認できました。
CORSを体験してみる
先ほどSame-Origin-Policyの制約が実際に機能していることを確認できました。 今度はCORSを利用して、Same-Origin-Policyの制約を緩和しようと思います (上でも書きましたが、CORSはSame-Origin-Policyを完全に無効にするわけではなくて、Same-Origin-Policyの制約を緩和するだけです)。
シンプルリクエスト
上のSame-origin policyの制約に引っかかったリクエストは、よく見てみるとシンプルリクエストの条件を満たすので、シンプルリクエストであることが分かります。
そしてブラウザが出したエラー文を見てみます。
オリジン 'http://localhost:8080' から 'http://localhost:3030/api/users/search' の XMLHttpRequest へのアクセスは、CORS ポリシーによってブロックされました: 要求されたリソースに 'Access-Control-Allow-Origin' ヘッダーがありません。
このエラー文を読んでみると、このシンプルリクエストが失敗している原因は、シンプルリクエストをした際のサーバーからのレスポンスメッセージのヘッダーに、Access-Control-Allow-Originヘッダーがないためです。
つまり、Access-Control-Allow-Originヘッダーをレスポンスに付与して、異なるオリジンがこのリソースを利用することを許可すれば良いということです(Same-origin policyの制約を緩和している)。
http:localhost:3030のサーバー側で、レスポンスに以下のヘッダーを付与しました。
// コルスの設定 response.SetHeader("Access-Control-Allow-Origin", "http://localhost:8080")
このヘッダーをつけることで、Same-origin policyの制約があるけど、このオリジン(http://localhost:8080)からのHTTPリクエストは許すよということをブラウザに伝えることができます。
変更後、検索ボタンを押すと、リクエストヘッダーにOrigin。レスポンスヘッダにAccess-Control-Allow-Originヘッダがあることが確認できました。

jsからのリクエストで取得した別オリジンのリソースもちゃんと利用できました。 (alertで利用できている)
プリフライトリクエスト
プリフライトリクエストのリクエストメソッドはOPTIONSです。 OPTIONSはHTTPメソッドの一つです。指定されたURLまたはサーバーの許可されている通信オプションをリクエストする際に使うメソッドです。
プリフライトリクエストを発生させるには、シンプルリクエストの条件を満たさないリクエストを送信すれば良いです。シンプルなやり方だと、Content-Type: application/jsonでリクエストすれば良いです。そうすると、シンプルリクエストの条件を満たさないので、リクエストの前にプリフライトリクエストをブラウザが送信してくれます。先ほどのhtmlを変更します。
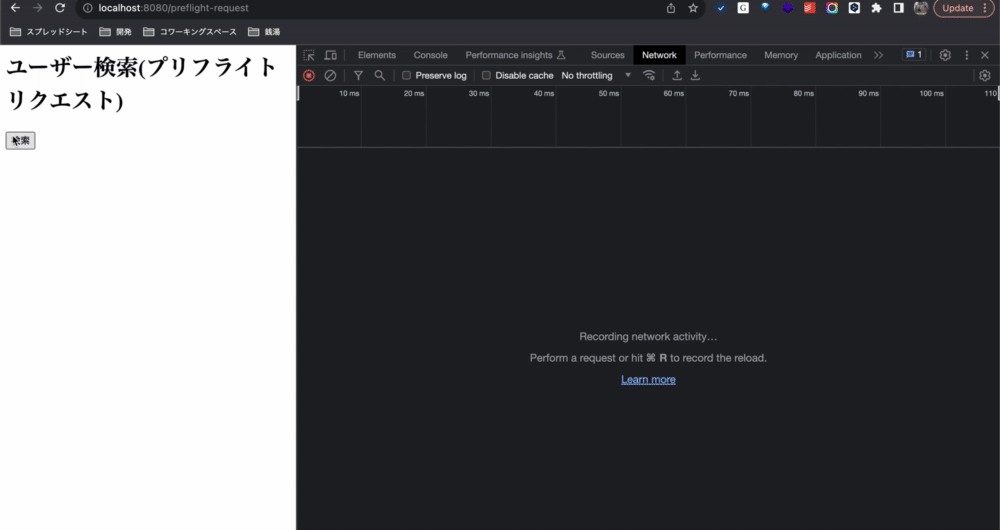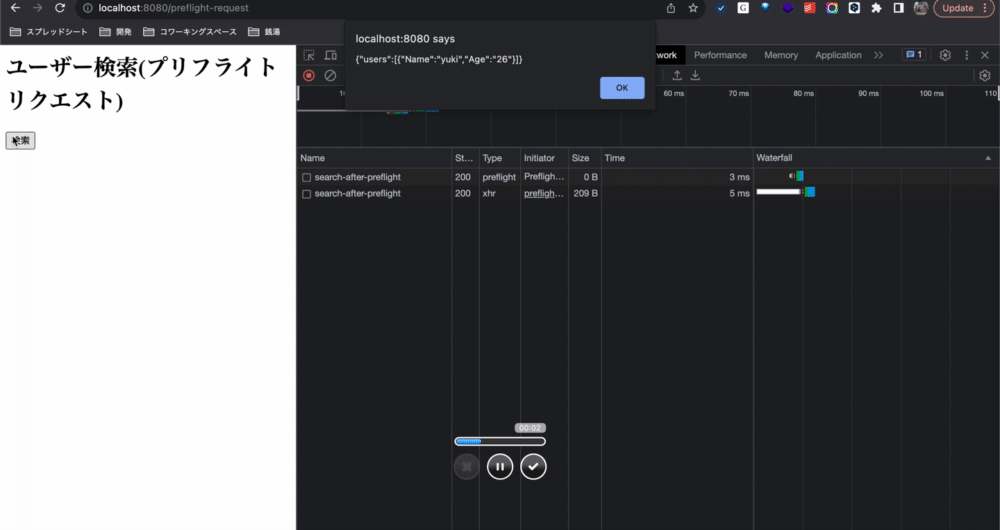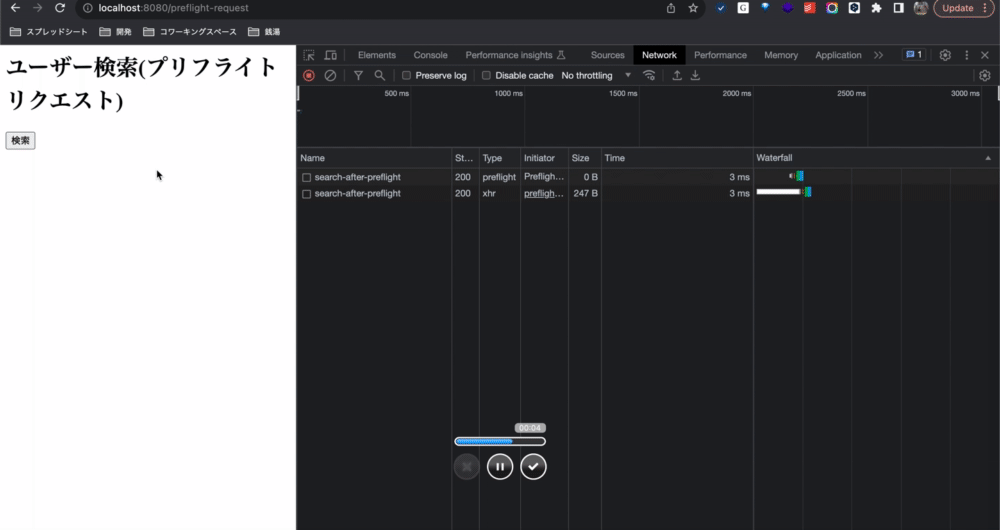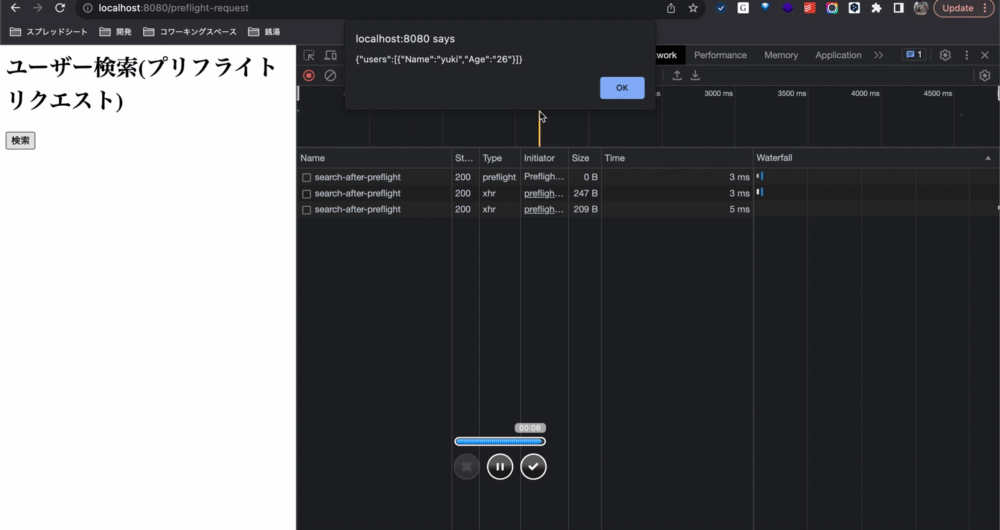
<html> <body> <h1>ユーザー検索(プリフライトリクエスト)</h1> <!-- methodをgetにしちゃうと、ボディがクエリパラメータになっちゃうね。サーチくらいならまだ良いか。--> <!-- 自作サーバーにクエリストリングの処理を入れてないから、postにした。サーチは本来ならgetが良い。--> <button id="button">検索</button> <script> document.getElementById("button").addEventListener("click",() => { const request = new XMLHttpRequest(); // onreadystatechangeプロパティは、XMLHttpRequestオブジェクトの状態が変化するたびに実行される関数を指定します: request.onreadystatechange = () => { // readyStateプロパティが4で、statusプロパティが200のとき、応答はreadyである: if (request.readyState == 4 && request.status == 200) { alert(request.responseText); } } request.open("GET", "http://localhost:3030/api/users/search-after-preflight", true); request.setRequestHeader("Content-Type", "application/json") request.send(); }) </script> </body> </html>

プリフライトリクエストの詳細を見てみると、jsでリクエストしようとしているリソースに対して、OPTIONSメソッドでリクエストが実行されていることが分かりました。このプリフライトリクエストの実行結果でCORSに関するヘッダーを返していないと、プリフライトリクエストは成功しても、jsのリクエストが失敗します。

コンソールに出ているエラーの内容を見てみます。
Access to XMLHttpRequest at 'http://localhost:3030/api/users/search-after-preflight' from origin 'http://localhost:8080' has been blocked by CORS policy: Request header field content-type is not allowed by Access-Control-Allow-Headers in preflight response.
日本語に訳してみます。
オリジン 'http://localhost:8080' から 'http://localhost:3030/api/users/search-after-preflight' の XMLHttpRequest へのアクセスは、CORS ポリシーによってブロックされました: リクエストヘッダーフィールド content-type は、プリフライト応答の Access-Control-Allow-Headers によって許可されていません
プリフライトリクエストとは、サーバーがCORSプロトコルを理解して準備されていることをチェックするためのリクエストです。
つまり、「jsでリクエストする際のリクエストメッセージに含まれているcontent-Type: application/jsonをサーバーが許可しているかどうか」を、プリフライトリクエストのレスポンスメッセージのヘッダーに含めていないので、このエラーが出ています。
プリフライトリクエストをした際にどんなHTTPメッセージがサーバーに送信されているのか見てみましょう。
OPTIONS /api/users/search-after-preflight HTTP/1.1 # Host リクエストヘッダーは、リクエストが送信される先のサーバーのホスト名とポート番号を指定します。 Host: localhost:3030 Connection: keep-alive # HTTP の Accept リクエストヘッダーは、クライアントが理解できるコンテンツタイプを MIME タイプで伝えます。 Accept: */* Access-Control-Request-Method: GET Access-Control-Request-Headers: content-type Origin: http://localhost:8080 User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/116.0.0.0 Safari/537.36 Sec-Fetch-Mode: cors Sec-Fetch-Site: same-site Sec-Fetch-Dest: empty Referer: http://localhost:8080/ Accept-Encoding: gzip, deflate, br Accept-Language: ja-JP,ja;q=0.9,en-US;q=0.8,en;q=0.7,zh-CN;q=0.6,zh;q=0.5
プリフライトリクエストのhttpリクエストメッセージではこの3つのヘッダが特徴的です。
# 同じリソースに対する今後の CORSリクエストに利用され得る 【リクエスト側が希望する】 メソッドを指示する。 Access-Control-Request-Method: GET # 同じリソースに対する今後の CORS リクエストに利用され得る 【リクエスト側が希望する】 ヘッダを指示する。 Access-Control-Request-Headers: content-type Origin: http://localhost:8080
このヘッダのプリフライトリクエストに対してレスポンスでは以下のヘッダを応答する必要があります。
Access-Control-Allow-Methods Access-Control-Allow-Headers Access-Control-Allow-Origin
プリフライトリクエストのレスポンスを生成する際に以下のヘッダーを追加したら、プリフライトリクエスト後のリクエストが成功しました。 (下でAccess-Control-Allow-Originも追加している)
response.SetHeader("Access-Control-Allow-Methods", "GET") response.SetHeader("Access-Control-Allow-Headers", "Content-Type")
以下の画像はプリフライトリクエストのレスポンスです。レスポンスヘッダーを見ると、サーバーはこのリソース(http://localhost:3030/api/users/search-after-preflight)に対してGETメソッドとContent-Typeの使用を許可していることが分かります。その情報をブラウザに伝えることができたので、ブラウザはjsによるhttpリクエストをちゃんと送信できました。


jsからのリクエストで取得した別オリジンのリソースもちゃんと利用できました。 (alertで利用できている)
認証情報を含めてリクエストしてみる
デフォルトでは、クロスオリジンに対するリクエストには、HTTP認証やクッキーなどの認証に用いられるリクエストヘッダ(Cookieヘッダ)は自動的に送信されません。これが送信されたら、CSRFでログイン権限のあるリクエストをやりたい放題できてしまいます。
今回は、js側とサーバー側に設定をして、異なるオリジンに対してクッキーを送信できるようにします(CookieはhttpリクエストメッセージのCookieヘッダによって送れます)。
まずはセッションカウンタのページを作ってみます。 count upボタンを押すとサーバーにリクエストをします。サーバー側では受け取ったクッキーの値からカウントを増やして、その値をjsonでフロントエンドに送信します。フロントエンドではそのjsonをパースして画面に反映します。
↓ localhost:8080のhtml
<html> <body> <h1>セッションカウンタ</h1> <span id="counter"></span> <!-- methodをgetにしちゃうと、ボディがクエリパラメータになっちゃうね。サーチくらいならまだ良いか。--> <!-- 自作サーバーにクエリストリングの処理を入れてないから、postにした。サーチは本来ならgetが良い。--> <button id="button">count up</button> <script> document.getElementById("button").addEventListener("click",() => { const request = new XMLHttpRequest(); // onreadystatechangeプロパティは、XMLHttpRequestオブジェクトの状態が変化するたびに実行される関数を指定します: request.onreadystatechange = () => { // readyStateプロパティが4で、statusプロパティが200のとき、応答はreadyである: if (request.readyState == 4 && request.status == 200) { const span = document.getElementById("counter") span.textContent = request.responseText } } request.open("GET", "http://localhost:3030/api/authentication-included-request", true); request.send(); }) </script> </body> </html>
↓ localhost:3030のサーバーサイド(goで実装してます)
func (c *AuthenticationIncludedRequest) Action(request *http.Request) *http.Response { cookieHeaders := map[string]string{} cookie, isThere := request.Cookies["counter"] var response *http.Response if isThere { currentCount, _ := strconv.Atoi(cookie.Value) currentCount += 1 cookieHeaders["counter"] = fmt.Sprintf("%v", currentCount) response = http.NewResponse( http.VersionsFor11, http.StatusSuccessCode, http.StatusReasonOk, request.TargetPath, []byte{byte(currentCount)}, ) } else { currentCount := 1 cookieHeaders["counter"] = fmt.Sprintf("%v", currentCount) response = http.NewResponse( http.VersionsFor11, http.StatusSuccessCode, http.StatusReasonOk, request.TargetPath, []byte{byte(currentCount)}, ) } // クッキーの設定 for key, value := range cookieHeaders { response.SetCookieHeader(fmt.Sprintf("%s=%s", key, value)) } // コルスの設定 response.SetHeader("Access-Control-Allow-Origin", "http://localhost:8080") return response }
count up ボタンを押して、シンプルリクエストが送信されたことは確認できました(別オリジンへのリクエストに成功している)。 CORSリクエストのレスポンスでSet-Cookieヘッダが入っているのは確認できました。しかし、別オリジンにはデフォルトでクッキーが送信されないので、そのせいで2回目にボタンを押した時のリクエストで、ブラウザはクッキーを勝手に送信してくれません(つまり、リクエスト時にCookieヘッダがない)。カウンターはずっと1のままです。

これを解決するには、XMLHttpRequestのwithCredentialsプロパティにtrueをセットする必要があります。このプロパティをセットすることで、リクエストでクッキーが送信されるようになります(リクエストにCookieヘッダが付与されるようになる)。
request.open("GET", "http://localhost:3030/api/authentication-included-request", true);
request.withCredentials = true;
request.send();
しかし、実際にリクエストをすると、リクエストが失敗していることが確認できます。


エラー文を読んでみます。
authentication-included-request:1 Access to XMLHttpRequest at 'http://localhost:3030/api/authentication-included-request' from origin 'http://localhost:8080' has been blocked by CORS policy: The value of the 'Access-Control-Allow-Credentials' header in the response is '' which must be 'true' when the request's credentials mode is 'include'. The credentials mode of requests initiated by the XMLHttpRequest is controlled by the withCredentials attribute.
日本語に訳してみます。
authentication-included-request:1 オリジン「http://localhost:8080」から「http://localhost:3030/api/authentication-included-request」のXMLHttpRequestへのアクセスは、CORSポリシーによってブロックされた: レスポンスの 'Access-Control-Allow-Credentials' ヘッダーの値は '' です。リクエストの資格情報モードが 'include' の場合は 'true' でなければなりません。XMLHttpRequest によって開始されるリクエストのクレデンシャルモードは withCredentials 属性によって制御される。
つまり、withCredentials = trueにしたリクエストに対しては、レスポンスでAccess-Control-Allow-Credentials: trueというレスポンスヘッダを返す必要があるということが分かります。
実際にレスポンスヘッダを追加してみます。
response.SetHeader("Access-Control-Allow-Credentials", "true")
レスポンスにちゃんとAccess-Control-Allow-Credentialsヘッダが含まれていることが確認できます。

これで異なるオリジンでもCookieを送信することができるようになりました。

ここまでのまとめ
- あるオリジンのリソースから別のオリジンのリソースに対してシンプルリクエストを送信したい場合、別のオリジンのレスポンスに
Access-Control-Allow-Originヘッダを追加する必要がある。 - あるオリジンのリソースから別のオリジンのリソースに対してプリフライトリクエストを送信する場合、プリフライトリクエストのレスポンスでは、
Access-Control-Allow-Methodsヘッダ、Access-Control-Allow-Headersヘッダ、Access-Control-Allow-Originヘッダの3つを追加する必要がある(この3つのヘッダをプリフライトリクエストのレスポンスに追加すると、プリフライトリクエスト後のリクエストが失敗しなくなる) - あるオリジンのリソースから別のオリジンのリソースに対してクッキーを伴うリクエストを送信したい場合、js側ではwithCredentialsの設定、サーバー側ではレスポンスに
Access-Control-Allow-Credentialsヘッダを追加する必要がある。 - フレームワークを使っている場合、上の設定を手動でやらずに、CORSの設定ファイルを書けばうまくいくかも。
終わり
CORSってなんかよく分かんないなと思っていたのですが、実際に手を動かしてみることで、よりCORSについて理解することができました。近年のSPAアプリケーションにおいてCORSの理解はあった方が良いので、今のうちに理解を深めることができて良かったなと思いました。
参考記事
電子メールとSMTPについてざっくりまとめる
目次
- 目次
- 概要
- 電子メール(Email)とは
- 電子メール送信の仕組み
- メールアドレスの構造とMXレコードについて
- メーラ(メールクライアント)とは
- SMTPプロトコルとHTTPプロトコルの関係性
- SMTP(Simple Transfer Protocol)とは
- SMTPが転送するもの
- メールサーバの内部について
- SMTPクライアントとSMTPサーバについて
- SMTPで通信する際の手順
- メールの送信は非同期でやった方が良い
- telnetコマンドで実際にSMTPに接続してみた
- goでSMTPクライアントを作ってみた
- 開発環境でのメールの送信について
- 独自ドメインでメールを出したい
- 終わり
- 参考記事
概要
メールの仕組みついて雰囲気で理解していたので、ちゃんと理解しようと思い、まとめました。
電子メール(Email)とは
電子メールとはインターネット上で送る郵便のようなものです。文章や画像データなど、コンピュータで扱えるさまざまな情報を送ることができます。
電子メール送信の仕組み
初期の電子メールでは、電子メールの送信者が利用しているコンピュータと宛先のコンピュータ間で、直接TCPコネクションが貼られて電子メールが配送されていました。この時メールの送信にはSMTPプロトコルが使用されています。
しかし、この方法では両方のホストの電源が入っていて、常にインターネットに接続されていなければメールを配信できません。仮に相手のコンピュータの電源が入っていなくて通信できない場合、しばらく時間を置いてから再度メールの配信を試みていました。 メールを送信するコンピュータの電源を落とした場合、電源が入るまでメールを送信することはできません。 また、メールを受信するコンピュータは電源が落ちているとメールを受信できません。そしてメールを受信するコンピュータのホストがインターネットに接続していないときにはメールを受信できません。
この直接TCPコネクションを貼る方法は電子メールの信頼性を高める上では非常に良い方法でした。しかし、時差の影響だったり両方のホストが稼働しててインターネットに接続していないといけないなどのデメリットもありました。そのため、電子メールの送信者のコンピュータと受信者のコンピュータの間で直接TCP接続をするのではなく、電源を切らないメールサーバーを経由してメールを送信するようになりました。この仕組みを採用したことで、送信者はメールサーバーにsmtpプロトコルでメールを送るだけで良くなり、受信者はメールサーバーからPOP3プロコトルでメールを受信するだけで良くなりました。この仕組みを採用するにあたって、受信者がメールサーバーから電子メールを受け取るPOPというプロトコルが標準化されました。
メールアドレスの構造とMXレコードについて
- メールアドレスは、「ユーザー名@ドメイン名」という構造になっています。
- メールアドレス中のどこにもメールサーバを示す情報がないです。そのため、まずはDNSサーバーにアクセスして、DNSサーバが管理しているMXレコードを参照して、メールアドレスのドメイン名からメールサーバーのドメイン名を特定します。その後、またDNSサーバーにアクセスして、取得したメールサーバのドメイン名に対応するAレコードを参照して、メールサーバーのドメイン名に紐づくIPアドレスを取得します。
- DNSサーバーは、Aレコード(ドメインに紐づくIPアドレスの対応関係)を管理しています。ホスト名の問い合わせに対してはこのAレコードが参照されます。DNSサーバーが管理しているMX(Mail eXchanger)レコードは、メールアドレスのドメインに紐づくメールサーバーのドメインの対応関係を管理しています。
- DNSサーバには名前とアドレスを対応づけた“Aレコード”という情報が登録されており、ホスト名の問い合わせに対してこのAレコードが参照される。しかし「メールサーバはどちら?」とコンピュータの役割で問い合わせられても、Aレコードのどれが対応しているのか判断はできない。そのためDNSサーバには、そのドメインのメールサーバ名を定義する「MX(Mail eXchanger)レコード」が別に登録されています。
メーラ(メールクライアント)とは
メーラとは、電子メールを送受信するためのソフトウェアやアプリケーションのことです。メーラはメールクライアントとも呼ばれます。 メールクライアントの代表的な例は、gmailやoutlookです。
SMTPプロトコルとHTTPプロトコルの関係性
SMTPプロトコルもHTTPプロトコルと一緒で、「何を伝えるか」に関するプロトコルです。「何を」伝えるか に関するプロトコルは、提供したいサービスによって変わってきます(メールを送るサービスならSMTP。WebサービスであればHTTP)。これらのプロトコルでは、送る側も受け取る側も、メッセージは「漏れなく順序よく」届くことは大前提として作られています。つまり、HTTPもSMTPもPOPも、 TCP通信を行うことを前提としたプロトコル ということになります。 (TCP以下のプロトコルではどうやって送るかを定めていて、TCPより上のプロコル(HTTPやSMTP)では、何を伝えるかを定めている)
SMTP(Simple Transfer Protocol)とは
SMTPは、メールサーバーにメールを送信するためのプロトコルです。 具体的にいうと、SMTPクライアントとSMTPサーバー間で TCP プロトコルを使用してメッセージをやり取りしながら、メールを送信するプロトコルです。 SMTPには2つの使い方があります。
ユーザーがメールクライアント(メーラ)を利用して、メールサーバにメールを送信するという使い方
メールを送信する際には、差出人のメールアドレスのドメインから、そのドメインに紐づくメールサーバーを特定して、SMTPに従ってメールを送信します。その後、もし、送信者と受信者が同じメールサーバーを使っていた場合、メール受信者はPOP3プロトコルを利用して、同じメールサーバからメールを取得できます。この場合、送信者と受信者のメールアドレスのドメイン名が同じである必要があります(MXレコードでドメイン名にメールサーバが紐づいているから)。
メールサーバから別のメールサーバに対してメールデータを送信するという使い方
これは、送信者と受信者が別々のメールサーバを使うときに行われます。 何故これでメールが相手に届くかというと、SMTPサーバがメールを転送してくれるためである。 SMTPによるメールの転送はバケツリレーに例えられます。SMTPサーバは、とりえあず受け取ったメールを最適と思われる次のSMTPサーバに送ります。 メールを受け取ったSMTPサーバは自分宛でなければさらに次のSMTPサーバに送ります。 このような処理が繰り返されてメールは、相手が利用しているメールアドレスのドメインに紐づくメールサーバに到達します。 これがメールサーバ間で利用されるSMTPです。
SMTPが転送するもの
SMTPでは、メールオブジェクトを転送します。メールオブジェクトはエンベロープとコンテンツで構成されています。
エンベロープ
エンベロープは一連のSMTPセッションの中で送信されます。 エンベロープは、発信者アドレス、一つまたは複数の受信者アドレス、オプションのプロトコル拡張の要素の3つで構成されています。 (オプションのプロコル拡張がイマイチわかっていないので、いずれ調べます)
コンテンツ
コンテンツは、SMTPセッション内のDATAコマンドの中で送信されます コンテンツは、ヘッダ部とボディの2つの部分で構成されます。 (ヘッダとボディは空行によって仕切られます) ヘッダ部はヘッダフィールドの集合から構成されています。ボディはMIMEに従って定義する必要があります。
ボディにテキスト以外にHTMLを書くことができます(これが俗にいうHTMLメール)。
その場合は、content-typeにmultipart/alternativeというMIMEタイプを指定する必要があります。
メールの世界ではテキストメールが基本の形式です。HTMLはあくまで表現力を増すだけのものなので、テキストメールも必ず一緒に送りましょう。そうすることで、テキストメールしか対応していないクライアントでもメールを表示することができます。
contet-typeがmultipartのメールを受信したメーラは、設定や機能に応じてテキストパートもしくはHTMLパートを選択的に表示してくれます。
(注意)エンベロープとコンテンツのどちらにも発信者のメールアドレスと受信者のメールアドレスを設定する必要がある
エンベロープとコンテンツのどちらにも発信者のメールアドレスと受信者のメールアドレスを設定する必要があります。 エンベロープの方のアドレスは、メールの配送で使われます。配送が完了すると破棄されます。コンテンツの方のアドレスは、メールクライアント上でメールのアドレスを確認する際に使います。
メールサーバの内部について
この画像を見ることで、メールサーバーとは特別なサーバーというわけではなくて、SMTPサーバーソフトウェアとPOPサーバーソフトウェアがインストールされたホストなんだなということが分かります。

SMTPクライアントとSMTPサーバについて
SMTPサーバはSMTPクライアントは、SMTPに従って通信のやりとりをします。 SMTPクライアントは、電子メールを送信するために使用されるSMTPプロトコルを実装したソフトウェアやアプリケーションのことです。Gmailなどのソフトウェアが代表的です。つまり、メールクライアント(メーラ)はSMTPプロトコルを実装している実装しているソフトウェアでもあることが分かります。
SMTP クライアントを経由して、SMTPサーバーに対してメールを転送します。HTTPサーバと通信するクライアントのことをHTTPクライアントというのと同じようなものです。
+----------+ +----------+
+------+ | | | |
| User |<-->| | SMTP | |
+------+ | Client- |Commands/Replies| Server- |
+------+ | SMTP |<-------------->| SMTP | +------+
| File |<-->| | and Mail | |<-->| File |
|System| | | | | |System|
+------+ +----------+ +----------+ +------+
SMTP client SMTP server
SMTPで通信する際の手順
以下にSMTPクライアントとSMTPサーバーがどのように通信しているかの図を示します。

SMTPクライアントは、サーバーにテキストベースのコマンドを送信します。SMTPサーバーはクライアントから送信されたコマンドへの応答としてコマンドが「成功」か「失敗」かを表すコードをリプライします。 SMTPクライアントはSMTPサーバからリプライが返ってくるまでは、次のコマンドを実行しません。つまり、SMTPプロトコルはシーケンシャルな(連続的な)プロトコルであることが分かります。
図の手順を文字でまとめます。
smtpクライアントとsmtpサーバーがtcpコネクションを確立すると、smtpサーバーから220 Greetingが返される
- EHLOコマンドを受け取ったsmtpサーバは、特に問題がなければ250 OKを返す。
- smtpクライアントは、MAILコマンドを送信する。このMAILコマンドを実行することで、発信者のメールアドレスをエンベロープに設定できる。
- MAILコマンドを受け取ったsmtpサーバは、特に問題がなければ250 OKを返す。
- smtpクライアントは、RCPTコマンドを送信する。このRCPTコマンドを実行することで、受信者のメールアドレスをエンベロープに設定できる。
- RCPTコマンドを受け取ったsmtpサーバは、特に問題がなければ250 OKを返す。
- smtpクライアントは、DATAコマンドを送信する。このDATAコマンドを実行することで、コンテンツを設定できる。
- DATAコマンドを受け取ったsmtpサーバは、特に問題がなければ354 Readyを返す。 10 354 Readyを受け取ったsmtpクライアントは、コンテンツを入力していって、.でコンテンツの終了をsmtpサーバに知らせる。
- コンテンツを受け取ったsmtpサーバーは、特に問題がなければ250 OKを返す。
- smtpクライアントはQUITを送信する。このQUITを送信することで、SMTPセッションを終了できる。
- smtpサーバーから221 Closingが返されて、tcpの接続が切られる。
メールの送信は非同期でやった方が良い
SMTPはシーケンシャルなプロトコルです。クライアントとサーバーが何回もやり取りしてやっとクライアントが用意したメールをメールサーバーに送信できます。Webサービスでは新規会員登録後にメールを送信すると思いますが、そのメール送信をもし同期的にやってしまうと、smtpのシーケンシャルなやり取りが完了するまで新規会員登録完了のHTTPレスポンスを返せません。HTTPレスポンスを待っている間、ブラウザの画面が一時的に真っ白になってしまいユーザーが離脱する原因になってしまうでしょう。そのため、メールの送信は非同期でやった方が良いです。
telnetコマンドで実際にSMTPに接続してみた
まず、メールサーバーを用意します。MailHogを使って、簡易的なsmtpサーバーを構築します。
MailHogはGo製のツールです。smtpサーバ(ポート1025)をインストールしているサーバーを立ててくれます。 このサーバに対してポート1025でhttpリクエストすれば、レスポンスで管理画面が返されて、smtpサーバーに送信されたメールを確認できます。
MailHogのDockerイメージが提供されているので、そのイメージから、Dockerコンテナを構築します。
version: "3" services: #メールサーバのコンテナ # 本来の SMTPでは、port:25が一般的 mail: image: mailhog/mailhog container_name: mailhog ports: # HTTPサーバーのポートをバインド - "8025:8025" # SMTPサーバーのポートをバインド - "1025:1025" environment: MH_STORAGE: maildir MH_MAILDIR_PATH: /tmp volumes: - mail-volumes:/tmp volumes: # mailhog はメールをメモリ上に保存するため、Docker のコンテナを停止するとメールが消えてしまう。 # そのため、メールのデータをボリュームに保存しておく mail-volumes:
その後、telnetコマンドを使って、このコンテナのポート1025とTCPコネクションを確立します。Telnetとは、遠隔地にあるサーバーやルータを端末から操作するための通信プロトコル(このプロトコルはアプリケーション層のプロトコル)です。または、そのプロトコルを利用するソフトウェアのことです。
その後、以下のようにやりとりをするとメールを送信できます。
telnet localhost 1025 Trying ::1... Connected to localhost. Escape character is '^]'. 220 mailhog.example ESMTP MailHog EHLO 250-Hello 250-PIPELINING 250 AUTH PLAIN MAIL FROM: <sender@sample.com> 250 Sender sender@sample.com ok RCPT TO: <receiver@sample.com> 250 Recipient receiver@sample.com ok DATA 354 End data with <CR><LF>.<CR><LF> To: receiver@sample.com From: hoge@sample.com Subject: hello test test test 12345 . 250 Ok: queued as R4G48Dv2B9HYsqHz64sKBci2ZByne4Vc1gM___KoCg0=@mailhog.example QUIT 221 Bye Connection closed by foreign host.
管理画面で送られてきたメールを見ることで、メールがちゃんと送信されていることと、メールの中身が正しく表示されていることを確認できます。

goでSMTPクライアントを作ってみた
goではsmtpパッケージを使うことで、簡単にSMTPクライアントを作れます。 以下にテキストメールを送信した場合と、HTMLメールを送信した場合の実装コードのURLを貼ります。
テキストメールを送るsmtpクライアント github.com
htmpメールを送るsmtpクライアント
開発環境でのメールの送信について
開発環境でのテストはsmtpで送ったメールがちゃんと表示されているかがわかれば良いです。そのため、smtpサーバーに送られた内容が確認できれば良いです。メールはメールサーバーに格納されます。結局ユーザーはメールクライアントを使えば、メールクライアントが勝手にメールサーバーから、POP3プロトコルを使って、メールを取得することができるので、そこの手順まで開発環境でテストする必要はないです。そのため、SMTPの方が重要だなと思い、POP3についてはあまり深ぼっていないです。
独自ドメインでメールを出したい
gmailのドメインとかではなくて、独自ドメインのメールアドレスを差出人としてメールを送信させたいなら、SendGridやAWS SESを使った方が良さそうです。
終わり
今までRailsのメーラの挙動はいまいちわかりませんでしたが、実際に使われているsmtpプロトコルをふかぼったり、Goでsmtpクライアントを実装したことで、だいぶSMTPを理解できたなと思いました。
参考記事
「エンベロープFrom」と「ヘッダFrom」の違いとは? - ベアメールブログ
HTMLメールとテキストメールを同時に送信するマルチパートメールとは | SendGridブログ
クッキーとセッション、セッション管理についてまとめる
目次
- 目次
- 概要
- クッキーとは
- クッキーがどのようにサーバーから送られるのかを見てみる
- ここまでのクッキーについてのまとめ
- その他のクッキーについて
- セッションとは
- セッション管理とは
- セッションとセッション管理の関係性
- クッキーとセッションの関係性
- セッション管理の流れ
- サインアップ機能, サインイン機能, ログアウト機能が満たす必要がある機能要件
- 認証とセッション管理の関係性をまとめる
- 終わり
- 参考記事
概要
クッキーとセッション、セッション管理を雰囲気で使っていたので、ちゃんと理解したいなと思い、記事にまとめました。
クッキーとは
まずはRFCにおけるクッキーの定義を見てみましょう。
RFCはインターネット技術における法律をまとめたドキュメントのようなものです。
- 序論
この文書は、 HTTP の Cookie と Set-Cookie ヘッダを定義する。 HTTP サーバは、 Set-Cookie ヘッダを利用して,クッキーと呼ばれる[ ( 名前, 値 ) が成すペアと, それに結び付けられたメタデータ ]を UA に渡すことができる。 UA は、サーバへ後続の要請を為す際に,そのメタデータと他の情報を利用して ( 名前, 値 ) が成すペアを Cookie ヘッダ内に返すかどうか決定する。
Set-Cookieヘッダについての項目も見てみましょう。
4.1.1. 構文
略式的には、 Set-Cookie 応答ヘッダは,次の並びで与えられる :
ヘッダ名 "Set-Cookie",
文字 %x3A( ":" ),
1 個のクッキー
ここで、クッキーは,次の並びで与えられる: ( クッキーの名前( cookie-name ), クッキーの値( cookie-value ) ) が成すペア( cookie-pair ) 0 個以上の属性( cookie-av ) — 各 属性は、 ( 属性名, 属性値 ) が成すペアを与える サーバは、次の文法に適合しない Set-Cookie ヘッダを送信するべきでない:
Set-Cookieヘッダにおけるもう一つの項目も見てみましょう。
4.1.2. 意味論(規範的でない)
この節では、 Set-Cookie ヘッダの意味論を単純化して述べる。 これらの意味論は、サーバにおけるクッキーの最もよくある利用を理解するには十分詳細なものである。 全部的な意味論は § UA 要件 にて述べる。 Set-Cookie ヘッダを受信した UA は、そのクッキーを,その属性もひっくるめて格納する。 UA は、後続して HTTP 要請を為す際には,適用可能, かつ まだ失効していないクッキーを Cookie ヘッダに内包する。 UA は、すでに格納されたクッキーと同じ[ cookie-name, domain-value, path-value ]を伴う新たなクッキーを受信した場合、既存のクッキーは抹消され,新たなクッキーに置換される。 サーバは、新たなクッキーを — その Expires 属性の値を過去に設定した上で — UA に送信することにより,クッキーを削除できることに注意。 クッキーの属性により指示されない限り、クッキーは、(例えば,下位ドメインではなく)生成元サーバに対してのみ返され,現在のセッションの終了時に失効する( “セッションの終了” は、 UA により定義される)。 UA は、認識できないクッキー属性は,無視する(クッキーまるごと,ではなく)。
次はCookieヘッダについてみていきましょう
UA は、自身が格納したクッキーたちを Cookie ヘッダに伴わせて,生成元サーバへ送信する。 サーバが § Set-Cookie ヘッダ の要件に適合する(かつ UA が § UA 要件 に適合する)場合、 UA は,次の文法に適合する Cookie ヘッダを送信することになる:
Cookieヘッダの意味論についても見てみましょう。
4.2.2. 意味論
各 cookie-pair が,UA に格納されているクッキーを表現する。 cookie-pair は、 UA が Set-Cookie ヘッダ内に受信した[ cookie-name と cookie-value ]を包含する。 クッキーの属性は、 UA からサーバへは返されないことに注意。 特に,サーバは、 Cookie ヘッダ単独からは,クッキーが[ いつ失効するのか?/ どのホストに有効なのか?/ どのパスに有効なのか?/ Secure や HttpOnly 属性を伴って設定されたものかどうか? ]を決定できない。 Cookie ヘッダ内の個々のクッキーの意味論については、この文書では定義されない。 これらのクッキーに対する応用に特有な意味論は、サーバごとに指定されることが期待されている。 クッキーは Cookie ヘッダにて直列化されるが、サーバは,その直列化の順序に依拠するべきでない。 特に, Cookie ヘッダが同じ名前の 2 個のクッキーを包含している場合(例えば、異なる[ Path / Domain ]属性を伴って設定されたもの)、サーバは,これらのクッキーがヘッダ内に現れる順序に依拠するべきでない。
この引用文を見る限り、クッキーとは、(クッキーの名前, クッキーの値)が成すペアと、それに結び付けられた0個以上のメタデータであることがわかります。
クッキーがどのようにサーバーから送られるのかを見てみる
クッキーは、サーバーがクライアント(ブラウザ)に送るHTTPレスポンスメッセージを通して、クライアント(ブラウザ)に送られ保存されます。
例えばログインフォームでユーザー認証をした場合を考えます。 サーバーサイドでは以下のプログラムを使用します。
クライアント(ブラウザ)にはChromeを使用します。
ログインフォームで名前とemailを入力してログインボタンを押すと、以下のようなHTTPリクエストメッセージがサーバーに送られます。
POST /login HTTP/1.1 Host: localhost:8080 Connection: keep-alive Content-Length: 75 Cache-Control: max-age=0 sec-ch-ua: "Chromium";v="116", "Not)A;Brand";v="24", "Google Chrome";v="116" sec-ch-ua-mobile: ?0 sec-ch-ua-platform: "macOS" Upgrade-Insecure-Requests: 1 Origin: http://localhost:8080 Content-Type: application/x-www-form-urlencoded User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/116.0.0.0 Safari/537.36 Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7 Sec-Fetch-Site: same-origin Sec-Fetch-Mode: navigate Sec-Fetch-User: ?1 Sec-Fetch-Dest: document Referer: http://localhost:8080/login Accept-Encoding: gzip, deflate, br Accept-Language: ja-JP,ja;q=0.9,en-US;q=0.8,en;q=0.7,zh-CN;q=0.6,zh;q=0.5 email=yukihoge%40gmail.com&password=yukihoge&submit_name=%E9%80%81%E4%BF%A1
そして、サーバーはこのHTTPリクエストメッセージを解釈して処理をして、以下のようなHTTPレスポンスメッセージを返します。 このHTTPレスポンスメッセージにSet-Cookieというヘッダがあります。このヘッダにはsession_idという名前のクッキーが、Set-Cookieヘッダのvalueとして指定されています。このSet-CookieヘッダをHTTPレスポンスメッセージに含めることで、このHTTPレスポンスメッセージを受け取ったクライアント(ブラウザ)はSet-Cookieヘッダに指定してあるクッキーを保存します。
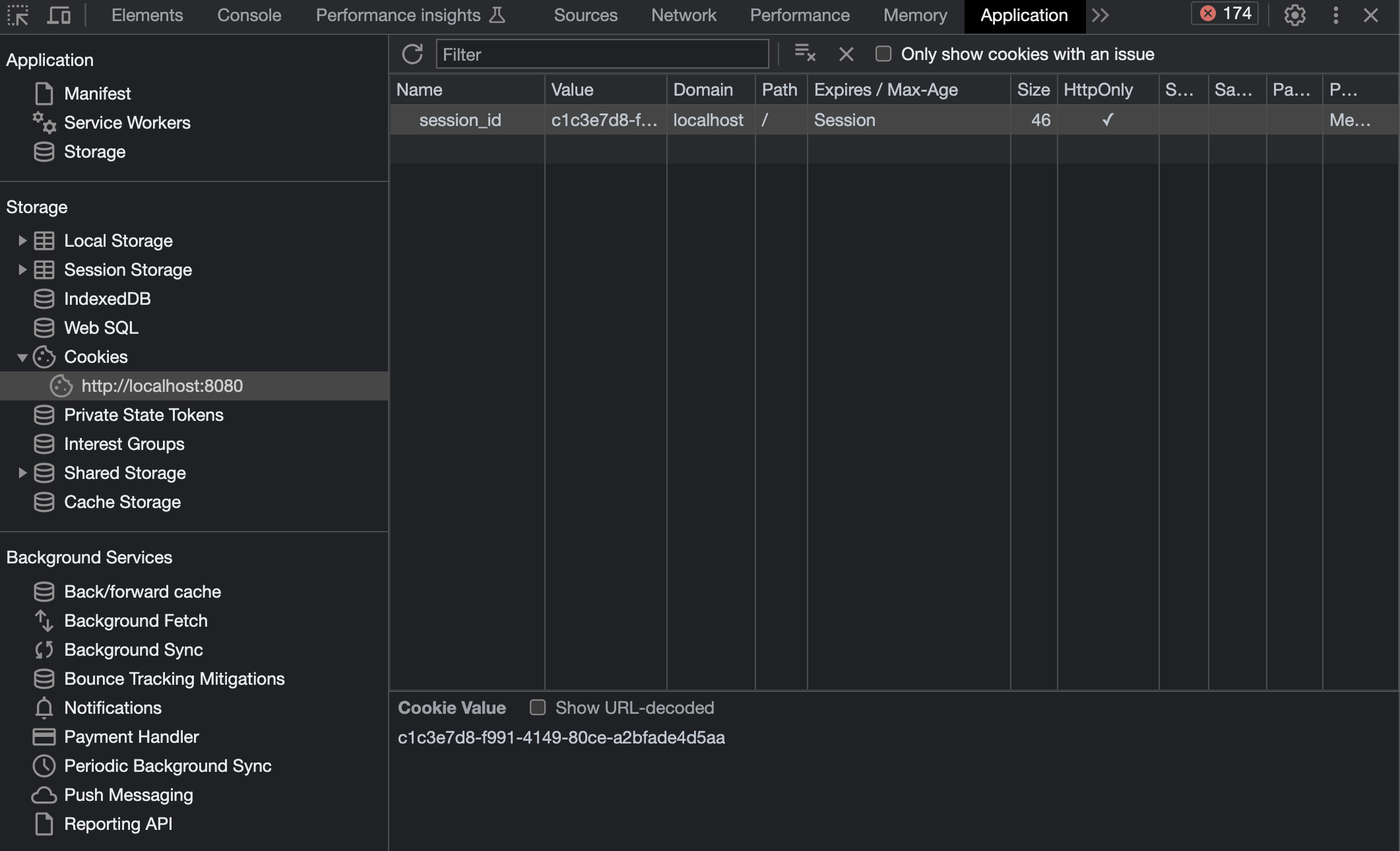
HTTP/1.1 302 Found Date: Fri, 08 Sep 2023 06:30:46 Server: HenaGoServer/0.1 Content-Length: 0 Content-Type: text/html; charset=UTF-8 Connection: Close Set-Cookie: session_id=c1c3e7d8-f991-4149-80ce-a2bfade4d5aa; HttpOnly Location: /mypage
ブラウザのCookiesタブを見ると、ちゃんと送信したクッキーが保存されていることが分かります。
そして上のHTTPレスポンスメッセージではリダイレクトを指示しているので、クライアント(ブラウザ)はLocationに指定してあるパスに対してHTTPリクエストを出します。以下がそのリクエストの際にサーバーに送られたHTTPリクエストメッセージです。
GET /mypage HTTP/1.1 Host: localhost:8080 Connection: keep-alive Cache-Control: max-age=0 Upgrade-Insecure-Requests: 1 User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/116.0.0.0 Safari/537.36 Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7 Sec-Fetch-Site: same-origin Sec-Fetch-Mode: navigate Sec-Fetch-User: ?1 Sec-Fetch-Dest: document sec-ch-ua: "Chromium";v="116", "Not)A;Brand";v="24", "Google Chrome";v="116" sec-ch-ua-mobile: ?0 sec-ch-ua-platform: "macOS" Referer: http://localhost:8080/login Accept-Encoding: gzip, deflate, br Accept-Language: ja-JP,ja;q=0.9,en-US;q=0.8,en;q=0.7,zh-CN;q=0.6,zh;q=0.5 Cookie: session_id=c1c3e7d8-f991-4149-80ce-a2bfade4d5aa
Cookieヘッダを使って、ブラウザに保存したクッキーをサーバーに送信していることが分かります。クッキー自体に特に制限がかけられていなければ、ブラウザはクッキーを生成したサーバーに対してリクエストする際には、必ずCookieヘッダを使ってクッキーも一緒に送信します。
その後以下のHTTPレスポンスメッセージがサーバーから返されます。
HTTP/1.1 200 OK Date: Fri, 08 Sep 2023 06:48:01 Server: HenaGoServer/0.1 Content-Length: 1212 Content-Type: text/html; charset=UTF-8 Connection: Close // レスポンスボディは省略
この際にはSet-Cookieヘッダは使ったりはしていません。Set-Cookieヘッダを使うのはクッキーを初めてサーバーから送信したい時だけです。
ここまでのクッキーについてのまとめ
- クッキーとは、(クッキーの名前, クッキーの値)が成すペアと、それに結び付けられた0個以上のメタデータである
- Set-Cookieヘッダを使うと、サーバーからクライアント(ブラウザ)に対してクッキーを送信できる。クッキーの数だけSet-Cookieヘッダを用意する必要がある。
- クライアントはサーバーからクッキーが送られてきたら、そのクッキーをおそらくクライアント独自の保存領域に保存する。
- クッキーに対して特に制限がかけられていなければ、クライアントはクッキー生成元サーバーにリクエストをするたびに、そのサーバーが生成したクッキーをCookieヘッダを使って送信する。(Cookieヘッダにはクッキー名とクッキーのvalueしか指定せず、クッキーのメタデータは指定しないので注意)
- Cookieヘッダー自体はHTTPリクエストメッセージに1つだけ含めることができる。そのため、複数のクッキーを送る場合は;で区切る
その他のクッキーについて
セッションクッキーとかサードパーティークッキーとか他にもいろんな種類のクッキーはありますが、この記事で説明しているクッキーが理解できれば理解できる内容なので、あえて説明を省きます。詳細な説明については以下のスクラップにまとめています。
セッションとは
セッションとは、Webサイトを訪れたユーザーがサイト内で行う一連の行動のことです。一連の行動をまとめて1セッションとしてカウントされます。実際のWebアプリ開発ではログインからログアウトまでを1つのセッションとして扱うことが多いです。
セッションを確立することで、前のリクエストの結果を考慮した上で、次のリクエストが出せることです。
例えばログイン後にセッションがちゃんと確立されていれば、別のページをリクエストしてもリロードしてページをリクエストしても、ログイン状態が保持されます。ログイン後にセッションが確立されていない場合、別のページをリクエストしたりリロードした際にログイン状態が保持されません。
セッション管理とは
セッション管理とは、なんらかの仕組みでクライアントのセッションを管理することです。
セッション管理をどのような仕組みで実現するかをざっくりいうと、クッキー + セッションストレージ(セッション情報を保存する場所)によって実現されます。
クッキーはセッションを識別するためのid(セッションid)を保存するのに使います。 セッションストレージには、セッションidとセッションidに紐づくユーザidを保存します。
セッションストレージにはクッキー or Redisを選択することが多いのかなと個人的には思います。それぞれのセッションストレージを選んだ場合の、セッション管理についてまとめます。
| セッション管理の方法 | セッションストレージ | メリット | デメリット |
|---|---|---|---|
| クッキーのみ | クッキー | ストレージを用意する必要がない | クッキー自体に容量制限がある。サーバー側でセッションクリアできない(ログアウトする前にクッキーをコピーしておいて、ログアウトした後にそのクッキーをコピーしてリクエストしたらセッションが確立できちゃう。これはセッションリプライ攻撃という) |
| クッキー + Redis | Redis | 容量制限がない, サーバー側でセッションをクリアできる | ストレージを用意する必要があり、ゆえにコストがかかる。RedisへのI/Oコストが発生する(メモリを圧迫するので、あまり多くの情報を保存しすぎない)。Redisサーバが落ちると認証周りの機能が全て動かなくなるので、可用性のあるインフラ設計をする必要がある。 |
Railsのデフォルトの設定だと、クッキーのみでセッションを管理しています。
セッションとセッション管理の関係性
セッションはwebサイトを訪れたユーザーがサイト内で行う一連の行動のことなので、セッションとは、概念的なものなのかなと個人的には思います。
セッション管理は、なんらかの仕組みを使ってクライアントのセッションを管理すること(つまり、どのようにセッションを実現するか)を意味する言葉なのかなと個人的には思います。
クッキーとセッションの関係性
クッキーはユーザーの設定を登録したり、ユーザーの行動を記録するマーケティングのために使ったりしますが、セッションを実現するためにも使います(厳密にいうとセッション管理を実現するために使います)。
セッション管理の流れ
以下で、どのような流れでセッション管理がされているかをまとめます。セッション管理の方式は、クッキー + Redisとします。
- クライアントがサーバーに対してログインフォームを要求する
- サーバーがログインフォームを返す
- ログイン情報を入力して、サーバーに送信する
- ログイン情報を元にユーザー認証をする(クライアントが誰なのかを特定する)。ユーザーが特定できたら、セッションストレージ(Redis)に生成したセッションidとユーザーidを格納する。そして、session_idを表すクッキーとマイページをクライアントに送信する。
- クライアントにマイページが表示される
- クライアントはリロードしたり別のページをリクエストすると、クッキーも一緒にサーバーに送信される。サーバー側ではクッキーからsession_idを取得して、そのsession_idでRedisにアクセスしてユーザーidを取得する。そうすることで、サーバーはユーザーの状態を保持したままレスポンスを返せる。
ログアウト時は、クッキーとセッションストレージの情報を消します。ログアウトのリクエストが来た時に、サーバー側では同名のクッキーのExpiresに過去日を指定してクライアントに送信します。そうすれば、クライアントは勝手にクッキーを消してくれます。また、Redisに登録してあるセッション情報も削除しておきます。このセッション情報を削除しないと、セッションidをコピーしてリクエストしたらログイン状態を維持できてしまいます。
終わり
サインアップ機能, サインイン機能, ログアウト機能が満たす必要がある機能要件
事前にDBにpassword_digestというカラムを作る必要があります。
サインアップ機能
- クッキーが存在しないことをミドルウェアで確認する
- クッキーが存在するならマイページへリダイレクト
- ミドルウェアでは、session_idというクッキーが存在するのかと、そのsession_idでユーザーが実際に存在するかを確認する。もしユーザーが実際に存在するかを確認しないと、デタラメなsession_idでもOKになっちゃう。
GET /sign_upでは、サインインページをレスポンスするPOST /sign_upでは、emailがユニークであるか(そのemailを持ったユーザーが既に存在するか)、パスワードとパスワードカンファが一致しているかを確認する。OKなら、パスワードダイジェストを生成してユーザーデータをインサートする。その後、セッションストレージにuser_idを格納して、そのuser_idに紐づくsession_idをクッキーに入れる(セッション管理)。その後マイページへリダイレクトさせる(リダイレクトしないと、POST /sign_upのレスポンスとしてページをレスポンスすることになる。パスが /sign_upなのでユーザーからしたらすごい違和感がある)- session_idクッキーのvalueにはユニークかつパターンを推測できないものが良いので、uuidとかが良い。
- もし
POST /sign_upに失敗したら、サインアップフォームをもう一度返す
サインイン機能
- クッキーが存在しないことをミドルウェアで確認する
- クッキーが存在するならマイページへリダイレクトさせる
GET /loginでは、ログインページをレスポンスするPOST /loginでは、emailでユーザーを特定する。emailでユーザーを特定できないなら、ログインフォームを返す。その後、passwordをハッシュ化したものとユーザーが持つpassword_digestを比較して同じなら、セッションストレージにuser_idを格納して、そのuser_idに紐づくsession_idをクッキに入れる(セッション管理)。その後、マイページへリダイレクトさせる。同じじゃないなら、ログインページをレスポンスする- もしユーザーがログインしていないのに/mypageをリクエストしてきたら、ミドルウェアを使ってログインページにリダイレクトさせる。
- ミドルウェアでは、session_idというクッキーが存在するのかと、そのsession_idでユーザーが実際に存在するかを確認する。
ログアウト機能
- ブラウザはDELETEリクエストできるけど、フォームがGETとPOSTしかできなくて、aタグもGETしかできないので、JavaScriptのfetchを使ってログアウト機能にDELETEリクエストする。
- もしユーザーがログインしていないのにログアウト機能をリクエストしてきたら、ミドルウェアを使ってログインページにリダイレクトさせる。 (ログインしていないのにログアウト機能を使ってくるユーザーは意味不明)
DELETE /logoutでは、クッキーからsession_idを取得して、そのsession_idをもとにRedisのセッション情報をを削除する。もしOKなら、session_idというクッキーのExpiresを過去日にしてボディなしでOKを返す。もし、DELETEリクエストじゃないなら、ボディなしのInternal Sever Errorコードを返す。- JavaScriptはレスポンスを受け取ったら、location.hrefで、
GET /loginを実行する。
認証とセッション管理の関係性をまとめる
Webアプリケーションにおける認証とは、「クライアント(ブラウザ)が誰なのかを特定すること」です。 (補足ですが、認可は「クライアントに権限があるかを特定すること」です)
ユーザー認証しただけだと、ログイン状態を保持できないです。例えばログイン後にセッションがちゃんと確立されていれば、別のページをリクエストしてもリロードしてページをリクエストしても、ログイン状態が保持されます。ログイン後にセッションが確立されていない場合、別のページをリクエストしたりリロードした際にログイン状態が保持されません。
そのため、ユーザー認証した後は必ずセッション管理もしましょう。そうすると、ログイン状態を保持できます。
終わり
実際にセッション管理を作ったり、クッキーのヘッダを使ってみてようやくクッキー、セッション、セッション管理が理解できたなと思いました。 今回はGoとRailsでユーザー認証とセッション管理の仕組みを作りました。
Railsが色々抽象化しているので、初心者がRailsでセッション管理や認証機能を作ると、腑に落ちないことが多いのかなと思いました(自分もそうだった)。Goで作ることで、色々考慮しないといけないので、セッション管理や認証周りの理解力は上がったなと思いました。しかし、Railsの方がサクッとできたので、やっぱRailsってすごいなと思いました。
参考記事
Cookieを扱う|伸び悩んでいる3年目Webエンジニアのための、Python Webアプリケーション自作入門
セッションとは|「分かりそう」で「分からない」でも「分かった」気になれるIT用語辞典
Rails7 × MySQLの環境をdocker-composeで立ち上げる(ついでにRailsで認証とセッション管理の仕組みも作る)
安全なウェブサイトの作り方 - 1.4 セッション管理の不備 | 情報セキュリティ | IPA 独立行政法人 情報処理推進機構
セッション管理とは|「分かりそう」で「分からない」でも「分かった」気になれるIT用語辞典
railsのsessionの値の保存先 - mikami's blog
Railsのセッション管理には何が最適か #Rails - Qiita
RailsでセッションとCookieを操作する方法 | Enjoy IT Life
https://fintan.jp/wp-content/uploads/2021/12/eafb1d61d2382a450ded5d97a4a2c464.pdf
Linuxコマンドの最近知った機能をまとめる
目次
echoコマンド
echoコマンドは、指定した引数の文字列を表示するコマンドです。
echo "Hello" => Hello
シェルに設定されている環境変数を確認したりもできます。
echo $HOME => /Users/yuuki_haga
シェルのリダイレクト機能
シェルのリダイレクトという機能を使うと、コマンド実行時の標準入出力を変更することができます。
# /tmpディレクトリに移動して、/tmpディレクトリ配下にsample.txtを作成する touch sample.txt # catでsample.txtに何も書かれていないことを確認する cat sample.txt # echoコマンドの標準出力をファイルに変更 echo $HOME > ./sample.txt # ファイルに書き込まれていることを確認できた cat sample.txt => /Users/yuuki_haga # catコマンドの標準入力をファイルに変更 cat < ./sample.txt /Users/yuuki_haga # 再度、コマンド実行結果をファイルに出力する echo $HOME > ./sample.txt # ファイルの内容が上書きされる cat < ./sample.txt => /Users/yuuki_haga # 新しい行として追加したいなら、>>を使う echo $HOME >> ./sample.txt # 確かに追加されていた cat sample.txt => /Users/yuuki_haga /Users/yuuki_haga # <<を使うと、標準入力をヒアドキュメントで渡すことができる # ヒアドキュメントとは、特定の文字列が入力されるまでをまとめて入力として扱う機能である # <<の後に任意のワードを書くと、次にそのワードが入力されるまでに書かれた行を標準入力の行として解釈される cat << "EOF" heredoc> aueo heredoc> kakikukeko heredoc> EOF => aueo kakikukeko # ヒアドキュメントを使いつつ、標準出力をファイルに変えたりもできる cat ./sample.txt => /Users/yuuki_haga /Users/yuuki_haga cat << "EOF" > ./sample.txt heredoc> aiueo heredoc> kakikukeo heredoc> sasisuseso heredoc> EOF cat ./sample.txt => aiueo kakikukeo sasisuseso
パイプ
パイプは、前のコマンドが出力した内容を、次のコマンドの入力につなげるための機能です。 grepコマンド使う時に、パイプをよく使います。
ps aux | grep zsh
長いコマンドを読みやすくする
バックスラッシュ("\")を使うことでコマンドを複数の行で分割できます。
echo aiueo \ akkikeo \ sasiseso => aiueo akkikeo sasiseso
ユーザーとsudoコマンド
Linuxにはシステムにログインするためのアカウントとして、ユーザーという概念があリマス。ユーザーのアカウントにはユーザー名や認証情報が含まれます。
whoamiコマンドを使えば、ログインしているユーザー名を確認できます。
whoami
=> yuuki_haga
また、Linuxのユーザーにはスーパーユーザーという考え方があります。スーパーユーザーはシステムの管理人です。スーパーユーザーはその他のユーザーでは実行できないような、システムを改変するような操作も実行できます。例えば、sudoコマンドを使うと、一時的にスーパーユーザーとしてコマンドを実行できます。
topコマンド
topコマンドは、CPUやメモリの利用状況を表示するためのコマンドです。 このコマンドは定期的に表示をリフレッシュしながら実行を続けます。
コマンド置換
コマンド置換では、ドル記号と丸括弧の中にコマンドを入力します(シェル変数や環境変数を参照する場合は$だけで良くて、丸括弧は必要ないので勘違いしないように注意)。そうすると先に丸括弧の中のコマンドが実行されて、$(コマンド)自体が「丸括弧内のコマンドの実行結果」に置換されます。
コマンド置換をすることで、ファイルの場所をwhichで特定して、そのパスをコピーして別のコマンドの引数としてペーストして実行する必要がなくなくなります。
which go => /usr/local/go/bin/go # goのファイルが開ける vim $(which go)