プロセス周辺の知識についてざっくり深ぼる
概要
プロセス周辺の知識が必要だなと感じる場面が何度かあったので、ざっくり深掘ります。
そもそもプログラムはどうやって実行されているのか
プロセスを学ぶ前に、そもそもプログラムはどうやって実行されるのかが見えてくると、プロセスが理解しやすくなります。 以下に、静的型付け言語で書いたプログラムがどのように実行されるかの手順をまとめます。
- まず、プログラムのファイルはハードディスクに存在しています。
- ビルドを実行して、機械語で書かれた実行ファイルを作成します。この実行ファイルもハードディスクに保存されます。(ビルドはコンパイル処理 + リンク処理)
- 実行ファイルのプログラムを実行した場合、OSは実行ファイルをメモリ上に展開します。その「メモリ上でいつでも実行できる状態のプログラム」を、OSは「プロセス」として管理します。
- プロセスは1つ以上のスレッド(プログラムの処理の流れ)を持っていて、CPUコアでそのスレッドを処理します。スレッドはCPUから見た際のプログラムの処理単位です。CPUコアでスレッドが実行されたら、プログラムの処理がちゃんと実行されています。
動的型付け言語の場合はちょっと特殊で、ソースプログラムをインタプリタが解析しながら実行するようです。インタプリタはまだまだ理解できていない部分があるので、いつか作ってみようと思います。
プロセスとは
プロセスとは、OSからプログラムを見た際のプログラムの実行単位です。 OSから見てプログラムはプロセスとして管理されています。 OSは限られたCPUで複数のプロセスを効率よく実行するために、OSは適切にプロセスを切り替えています。
プロセスの特徴を以下にまとめます。
プロセスはプロセスidを用いてOSによって管理されている
プロセスはプロセス自体を識別するためにプロセスidを用いて、OSによって管理されています。
プロセスは1つ以上のスレッド(プログラムの処理の流れ)を持つ
プロセスは1つ以上のスレッド(プログラムの処理の流れ)を持ちます。
プロセス自体はメモリ上に存在している
プロセス自体はメモリ上に存在しています。プロセスは自分が独占したメモリの中に存在していて、その中で何をしても他のプロセスには影響を与えません。メモリ上に存在しているプロセスの構成をすごくざっくり言うと、「プログラム」と「プログラムの実行に必要なデータ(変数や環境変数等々)」の2つで構成されています。
CPUコアでプロセスが持つスレッドを実行する過程で、外部データがプロセスにインプットされる場合、プロセスが確保しているメモリ領域を動的に増やして、データを受け入れられるようにしたりします。ただ、データがあまりにも大きいと、プロセスが確保しないといけないメモリ領域も多くなってしまい、サーバー自体に元々用意されているメモリ領域を大きく圧迫してしまい、結果的にサーバーの処理能力を低下させてしまいます。 Linuxカーネルの持つ機能でOOMKillerというのがあります。この機能はシステムがメモリ不足になったときに、メモリを多く消費しているプロセスを強制的に殺すという機能です。例えばアプリケーションサーバーのプロセスがあまりにもメモリを使いすぎていて、システムがメモリ不足になると、そのプロセスが強制的に殺されてしまます。その結果、ユーザーがサイトにアクセスした際に画面が表示されず、ビジネス的な損失を被る可能性があります。
プロセスのライフサイクル
通常、プロセスは、以下のようなライフサイクルです。
- プロセスが何らかの方法で生成される
- 処理中(実行中、待ち状態、ブロック中の3パターンがある)
- 終了
処理中の間、プロセスは3つの状態を持ちます。
実行中は、CPUで実行されている状態です。 待ち状態は、CPUでいつでも処理できるよという状態です。 ブロック中は、プロセスでIO待ちが発生しているから、今はCPUで処理できないよという状態です。 基本的にはプログラムの実行が終了することで、プロセスが終了します。 プロセスの生成に関しては、forkというシステムコールを用いることで生成できます。
システムコールとは
システムコールとは、アプリケーションプログラムがカーネルの機能を利用するためのインターフェースです。システムコールはアプリケーションプログラムとカーネルの間に存在します。通常システムコールは関数で表現されます。
例えば、ネットワークを利用した通信、ファイルへの入出力、新しいプロセスの生成、プロセス間通信、コンテナの生成などは、システムコールを使用することで実現されています。
forkとexec
fork
forkとは、OSに親プロセスを複製して子プロセスを生成するように命令するためのシステムコールです。 通常、プロセスは、親プロセスがforkシステムコールをOSに送ることで、生成されます。 forkを実行すると、OSは親プロセスを複製して子プロセスを生成します。つまり、この時、メモリ上のプロセスのデータが複製されていることを意味します(複製とは言いつつも、別のプロセスとしてメモリ上に存在するので、プロセスidは異なります)。 forkによってプロセスは生成されるため、基本的に全てのプロセスには「自分を生んだ親プロセス」が存在します。
注) forkした子プロセスはforkを実行した位置以降の処理を実行するので、そこは注意しましょう。
親のプロセスの親のプロセスの親のプロセスのって辿っていけるのかと疑問に思うと思います。実は全ての祖先となるinitプロセスとなるものがLinuxには存在していて、このプロセスは、コンピュータが起動したときに生成されて、そのあと全てのプロセスがここを祖先としてforkされていきます。このプロセスは一番最初のプロセスなので、プロセスidが1です。
プロセスは木構造の親子関係を持っています。この親子関係を「プロセスツリー」と呼びます。macだとlaunchdというプロセスがinitプロセスと同等のプロセスです。 pstreeというコマンドを用いることで、プロセスツリーを確認できます。
pstree -+= 00001 root /sbin/launchd |--= 00092 root /usr/libexec/logd |--= 00093 root /usr/libexec/smd |--= 00094 root /usr/libexec/UserEventAgent (System) |--= 00097 root /System/Library/PrivateFrameworks/Uninstall.framework/Resources/uninstalld |--= 00098 root /System/Library/Frameworks/CoreServices.framework/Versions/A/Frameworks/FSEvents.framework/Versions/A/Support/fseventsd |--= 00099 root /System/Library/PrivateFrameworks/MediaRemote.framework/Support/mediaremoted # 省略
exec
execとは、execを実行したプロセスの内容を、execに指定した内容で書き換えて実行するためのシステムコールです。 あるプロセスがexecというシステムコールを実行すると、execの内容でそのプロセス自体の内容を書き換えて実行することができます。
親プロセスから複製した子プロセスを異なる処理内容のプロセスとして実行するには、以下の手順で実現できます。
- forkで親プロセスを複製したプロセスを作成
- そのプロセスでexecを実行して、別の内容のプロセスとして書き換えて実行する
forkとexecを試しに実行してみます。
puts "forking..." # forkメソッドを呼び出す # 親プロセスでは子プロセスのpidが取得できる。 # 複製された子プロセスでは、pidはnilである pid = Process.fork p pid # ここに来てるということは、正常にプロセスが複製された。 # この時点で親プロセスと子プロセスが *別々の環境で* # 同時にこのプログラムを実行していることになる。 puts "forked!" if pid.nil? # 子プロセスはこっちを実行する # execメソッドで、Rubyのプロセスを無限ループでsleepするプロセスに置き換える # ここで子プロセスをexecしている exec "ruby -e 'loop { sleep }'" else # 親プロセスはこっちを実行する # 子プロセスが終了するのを待つ # 親プロセスだからpidはnilではない Process.waitpid(pid, 0) end
このコードを実行すると、以下のような結果が表示されます。
ruby /Users/yuuki_haga/repos/learning/rails/rails-n-plus-1/src/sample.rb forking... 81598 forked! nil forked!
psを実行した結果、確かに子プロセスが複製時とは異なる状態で実行されていることが確認できました。
ps
PID TTY TIME CMD
64897 ttys003 0:01.52 -zsh -g --no_rcs
81585 ttys003 0:00.12 ruby /Users/yuuki_haga/repos/learning/rails/rails-n-plus-1/src/sample.rb
81598 ttys003 0:00.10 ruby -e loop { sleep }
65703 ttys004 0:01.19 -zsh -g --no_rcs
pstreeコマンドでフォークされたプロセスも確認できるので、ちゃんとフォークされているんだなと分かります。
pstree 84073 -+= 84073 yuuki_haga ruby /Users/yuuki_haga/repos/learning/rails/rails-n-plus-1/src/sample.rb \--- 84086 yuuki_haga ruby -e loop { sleep }
&をつけると、バックグラウンドプロセスとして実行される
コマンドを実行する際に&をつけることで、バックグラウンドプロセスとして実行することができます。
ruby -e "sleep" & [1] 76342
バックグラウンドプロセスとして実行することで、ターミナルを通して入力を受け付けることができなくなります。 fgを実行すればフォアグラウンドプロセスに戻せます。
ジョブとシェルの関係性
ジョブはシェルが管理するプログラムのグループのことです。 基本は1プログラム1ジョブです。
シェルからコマンドを叩いてプロセスを生成する場合、親プロセスはシェルのプロセスである
シェルからコマンドを叩いてプロセスを生成する場合、親プロセスはシェルのプロセスです。pstreeコマンドで実際に確認できます。
ps
PID TTY TIME CMD
64897 ttys003 0:01.74 -zsh -g --no_rcs
86122 ttys003 0:00.13 ruby /Users/yuuki_haga/repos/learning/rails/rails-n-plus-1/src/sample.rb
86135 ttys003 0:00.10 ruby -e loop { sleep }
65703 ttys004 0:01.67 -zsh -g --no_rcs
pstree 64897
-+= 64897 yuuki_haga -zsh -g --no_rcs
\-+= 86122 yuuki_haga ruby /Users/yuuki_haga/repos/learning/rails/rails-n-plus-1/src/sample.rb
\--- 86135 yuuki_haga ruby -e loop { sleep }
単体のpsコマンドとps -efコマンドの違い
単体のpsコマンドは実行中のシェルとシェルの子プロセスを表示します。複数のターミナル上でシェルを実行している場合、単体のpsコマンドを実行すると複数のシェルのプロセスと、それらの子プロセスが表示されます。
ps -efは、システム全体の全てのプロセスを表示することができます。
プロセスとファイル入出力の関係性
プロセスに対してデータを入力したり、プロセスが処理したデータをファイルに出力したりできます。
以下の例では、ディスクにあったファイルのデータを変数に代入することで、プロセス内部のメモリ上に展開して、メモリ上に展開されたデータを別のファイルとしてディスクに出力しています。
file = File.open("nyan.txt", "r") # ファイルのデータはもともとディスクに存在している。プロセスがもともとメモリー内に持っているものではない # このディスクに存在しているファイルのデータを、readlinesで変数に代入することで、 # プログラム上で、ファイルをIOする際に一瞬プロセスは「ブロック中」になっている。 # プロセスの外部に存在しているディスクのデータを、プロセスの内部のメモリーに読み込んでいる lines = file.readlines # ファイルの中身を全部読み込む file.close copy_file = File.open("nyan_copy.txt", "w") copy_file.write(lines.join) file.close
Linuxでは、全てがファイルです。もっと詳細に言うと、Linuxでは、プロセスに関する全ての入出力をファイルと同じインターフェースで扱うことができます。プロセスがターミナルからの入力を受け取りたかったり、ネットワーク越しに入力をもらって、ネットワーク越しに出力したりなどをファイルと同じインターフェースで扱えます。
ファイルディスクリプタとは
ファイルディスクリプタとは、OSが開いているファイルの識別子です。
プロセスは低レイヤーの処理(ファイルを開いたり、ディスクにデータを書き込んだり、ディスクからデータを読み取ったり等)を自分自身でするわけではなくて、プロセスがシステムコールを実行することで、OSに低レイヤーの処理を実行させています。 OSはプロセスから「ファイルを開け」というシステムコールを受け取ると、実際にファイルを開いて、そのファイルを表す識別子(ファイルディスクリプタ)を作成してプロセスに返します。プロセスはファイルディスクリプを使って、「このファイルディスクリプタで表されるファイルにこれを書き込め」というシステムコールを送ります。そうするとOSはファイルディスクリプタで表された、既に開いているファイルに対して書き込みを行います。 書き込みが終了したら、プロセスは不要になったファイルディスクリプタをcloseというシステムコールでOSに返却します。OSはファイルディスクリプタが返却されたので、「もうこのファイルは使わないのか」と判断して、ファイルを閉じます。
ここからはコード例を元に解説します。
file = File.open("kuga.txt", "w") puts file.fileno # => 9 file.close
1行目では、openシステムコールをOSに対して送っています。正常にopenされるとファイルディスクリプタを内部に持ったfileオブジェクトが生成されます 2行目では、fileオブジェクトが保持しているファイルディスクリプタを取得してターミナルに出力します 3行目では、fileを閉じていますが、これはRubyが内部でfileオブジェクトが保持しているファイルディスクリプタを使って、OSにcloseシステムコールを送っています。
filenoを実行することでファイルディスクリプタを出力できます。 プロセスから標準入出力が指し示すファイルのファイルディスクリプタを見ることもできます。
puts $stdin.fileno puts $stdout.fileno puts $stderr.fileno # => ruby std_fds.rb # 0 # 1 # 2
標準入力、標準出力、標準エラー出力
標準入力、標準出力、標準エラー出力とは、生成されたプロセスがファイルから入力を得たり、ファイルにデータを出力をしたりする際に使う最初から用意されているファイルのことです。 標準入力、標準出力、標準エラー出力はデフォルトでターミナルが指定されています。 標準入出力も標準エラー出力も、ファイルと同じインターフェースでプロセスから操作できます。 標準入出力,標準エラー出力はデフォルトでターミナルが指定されているだけで、設定すると変更できます。
プロセスはファイルディスクリプタを指定してシステムコールを実行することで、ファイルからデータを読み取ったり、ファイルにデータを出力したりできます。プロセスは生成された時点で最初から3つのファイルディスクリプタを扱うことができて、その3つが、0(標準入力), 1(標準出力), 2(標準エラー出力)です。
例えば、リダイレクトを使うことで、標準入出力に別のファイルを指定できます。
↓ 標準出力のリダイレクト
# 標準出力にファイルを指定 # ファイルを生成しつつ。プロセスからの出力をファイルにアウトプットする # 1を省略することもできる ruby /Users/yuuki_haga/repos/learning/rails/rails-n-plus-1/src/print_mew.rb 1>hina.txt
↓ 標準入力のリダイレクト
file = $stdin # IOを待っているので、プロセスが「ブロック中」になっている。 lines = file.readlines file.close # rubyの組み込みグローバル変数 $stdout には、「標準出力」と言われるものが、 # すでにFile.openされた状態で入っています。この「標準出力」の出力先は、デフォルトではターミナルをさします file = $stdout file.write(lines.join) file.close
# 0を省略することもできる ruby /Users/yuuki_haga/repos/learning/rails/rails-n-plus-1/src/stdout.rb 0<hina_hina.txt mew
↓ 標準入力、標準出力どちらもリダイレクトする
stdin_file = $stdin # IOを待っているので、プロセスが「ブロック中」になっている。 lines = stdin_file.readlines stdin_file.close # rubyの組み込みグローバル変数 $stdout には、「標準出力」と言われるものが、 # すでにFile.openされた状態で入っています。この「標準出力」の出力先は、デフォルトではターミナルをさします stdout_file = $stdout stdout_file.write(lines.join) stdout_file.close
# プロセスがファイルを標準入力としていて、プロセスの標準出力を設定することで、プロセスのアウトプット先がファイルになる ruby std_in_out.rb 0<hina.txt 1>hoge.txt
↓ 標準エラー出力
# プロセスからアウトプットされたエラーは、標準エラー出力に設定されたファイルに出力される。 puts "this is stdout" warn "this is stderr" # warnは標準エラー出力に引数を出力する
ruby stdout_stderr.rb 1>out.txt 2>err.txt # こう書くこともできる # &をつけることで、この1は1っていう名前のファイルじゃなくてファイルディスクリプタと表すことができる ruby stdout_stderr.rb 1>out.txt 2>&1
プロセス間通信とは
ファイルのデータをプロセスに入力したり、プロセスの処理結果をファイルに出力したり、プロセスへの入出力は基本的にはファイルを用いると思うかも知れません。しかし、それ以外にも、プロセスは、プロセス同士で通信することができます。
プロセス間通信とは、異なるプロセス間でデータを送信したり受信したりすることです。MySQLもサーバーで実行されている時は一つのプロセスであって、Railsアプリケーションもサーバーで実行されている時は一つのプロセスです。
RailsアプリケーションからMySQLのDBに対してデータをインサートしたい場合、Railsアプリケーションのプロセスと、MySQLのプロセスの間で通信(プロセス間通信)をする必要があります。プロセス間通信をすることで、データを別のプロセスに送信できたり、別のプロセスからデータを受信できたりします。プロセス間通信は大きく分けて2種類に分類できます。
- 同一ホスト間に存在するプロセス同士でプロセス間通信する
- 異なるホスト間に存在するプロセス同士でプロセス間通信する
2種類のプロセス間通信をどのように実装するのか、見てみましょう。
同一ホスト間に存在するプロセス同士でプロセス間通信する
メジャーな実装方法は以下の2種類です。
各実装方法について以下にまとめます。
パイプ
パイプに関しては、以下のような使い方を想定しています。
command_a | command_b
command_aのプロセスの出力結果が、commnad_bのプロセスの入力になります。 この際に、comnnad_aのプロセスの処理が完全に終わらなくても、出力があるなら、comnnad_bのプロセスに入力されます。commnad_bのプロセスは、commnad_aからの入力が来るまで、プロセスの状態が「ブロック中」になります。
以下に実行した結果を提示します。
# hoge.txt mew hinana
# command_a.rb puts "start command_a" stdin_file = File.open("hoge.txt", "r") lines = stdin_file.readlines stdin_file.close stdout_file = $stdout stdout_file.write(lines.join) stdout_file.close
# command_b.rb puts "start command_b" stdin_file = $stdin lines = stdin_file.readlines stdin_file.close stdout_file = $stdout stdout_file.write([*lines, "command_b"].join) stdout_file.close
# 実行結果 ruby command_a.rb | ruby command_b.rb # => start command_b start command_a mew hinana command_b%
UNIXドメインソケット
UNIXドメインソケットとは、ホストのファイルシステム上に存在する特殊な名前付きのソケットファイルのことです。同一ホストに存在するプロセス同士がUNIXドメインソケットを用いることで、プロセス間通信することができます。 UNIXドメインソケットを用いたプロセス間通信は、TCP/IPを使わないので非常に高速に通信できますが、プロセスが同一ホスト上に存在する必要があります。
# server.rb require 'socket' # hena_hoge.sockがunixドメインソケットの名前になる socket_path = '/tmp/hena_hoge.sock' # UNIXServer.newを実行することで、hena_hoge.sockというUNIXドメインソケット(ファイル)が生成される server = UNIXServer.new(socket_path) puts "サーバーが起動しました" loop do # プロセスはこのUNIXドメインソケットを利用して、外部からの入力を受け付けられるようにしている # acceptはクライントにデータを流すためのソケットを戻り値として返す client = server.accept puts "クライアントが接続しました" # クライアントからのデータを読み取り、加工して返す例 data = client.gets.chomp processed_data = data.upcase client.puts "サーバーからの応答: #{processed_data}" client.close end
# client.rb require 'socket' socket_path = '/tmp/hena_hoge.sock' # サーバーと同じunixドメインソケットのパスを使用 client = UNIXSocket.new(socket_path) client.puts "Hello, server!" response = client.gets.chomp puts response client.close
# サーバー側のシェル # 起動した後に、クライアントのプログラムを呼び出してサーバーのプロセスに接続している ruby server.rb サーバーが起動しました クライアントが接続しました
ruby client.rb サーバーからの応答: HELLO, SERVER!
クライアントのプロセスとサーバー側のプロセスがunixドメインソケットを用いて通信できることは分かりました。
次にUNIXドメインソケットのファイルは、ちゃんと存在しているのかを確認してみます。/tmp/hena_hoge.sockというUNIXドメインソケットのファイルは、UNIXServer.new(socket_path)を実行したタイミングで生成されます。
ll /tmp/hena_hoge.sock srwxr-xr-x 1 yuuki_haga wheel 0 12 3 00:35 /tmp/hena_hoge.sock
このファイルがどんな形式のファイルかをfileコマンドで確認してみます。
file /tmp/hena_hoge.sock /tmp/hena_hoge.sock: socket
つまり、このファイルはただのファイルではなくて、UNIXドメインソケットを表すファイルであることが分かります。
このUNIXドメインソケットをどのプロセスが利用しているのかを確認してみます。指定したファイルを開いているプロセスを確認するにはlsofコマンド(list open files)を実行します。
lsof /tmp/hena_hoge.sock COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME ruby 85483 yuuki_haga 9u unix 0xdb10307bb54e6e21 0t0 /tmp/hena_hoge.sock
/tmp/hena_hoge.sockはプロセスidが85483のプロセスによって開かれていることが分かります。
このプロセスidが85483のプロセスが、実は先ほど実行したサーバー側のプロセスです。
ps PID TTY TIME CMD 71698 ttys000 0:01.31 -zsh -g --no_rcs 81408 ttys002 0:01.03 -zsh -g --no_rcs 64897 ttys003 0:05.33 -zsh -g --no_rcs 85483 ttys003 0:00.13 ruby server.rb
サーバー側のプロセスがどんなファイルディスクリプを持っているかはlsofコマンドにpオプションを指定することで確認できます。
lsof -p 85483 COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME ruby 85483 yuuki_haga 0u CHR 16,3 0t444978 22899 /dev/ttys003 ruby 85483 yuuki_haga 1u CHR 16,3 0t444978 22899 /dev/ttys003 ruby 85483 yuuki_haga 2u CHR 16,3 0t444978 22899 /dev/ttys003 ruby 85483 yuuki_haga 3 PIPE 0xc0913dfbb36ea347 16384 ->0xd549b208306283b8 ruby 85483 yuuki_haga 4 PIPE 0xd549b208306283b8 16384 ->0xc0913dfbb36ea347 ruby 85483 yuuki_haga 5 PIPE 0x69ccf80e48859be3 16384 ->0x36bc210bd8e109a9 ruby 85483 yuuki_haga 6 PIPE 0x36bc210bd8e109a9 16384 ->0x69ccf80e48859be3 ruby 85483 yuuki_haga 7 PIPE 0xe5b65924fbab5eff 16384 ->0x20dd7b52143b272c ruby 85483 yuuki_haga 8 PIPE 0x20dd7b52143b272c 16384 ->0xe5b65924fbab5eff ruby 85483 yuuki_haga 9u unix 0xdb10307bb54e6e21 0t0 /tmp/hena_hoge.sock
よって、サーバー側のプロセスはファイルディスクリプタ9を指定することで、UNIXドメインソケットのファイルにアクセスできて、それを用いて、クライアントのプロセスと通信しているんだなとざっくり理解することができました。
異なるホスト間に存在するプロセス同士でプロセス間通信する
メジャーな実装方法は以下の1種類です。
- ソケット
各実装方法について以下にまとめます。
ソケット
ソケットを用いると、同一ホストや異なるホスト間でプロセス間通信することができます。しかし、同一ホストならUNIXドメインソケットで通信した方がパフォーマンスが良いので、ソケットは、異なるホストでのプロセス間通信をする際に使うのが良さそうです。
ソケットはネットワーク経由でプロセス間通信するなら必須の知識なので、詳しくは以下の記事を見ると良いでしょう。
ソケットもファイルと同じインターフェースで操作することができる。
Linuxでは全てがファイルなので、ソケットもファイルと同じインターフェースで操作することができます。プロセスからソケットに対して書き込んだり、ソケットからプロセスに入力したい場合、ソケットを表すfdと、read, writeのシステムコールをプロセスから実行すれば良いです。
require "socket" # 12345 portで待ち受けるソケットを開く listening_socket = TCPServer.open(12345) # ソケットもファイルなので、fdがある puts listening_socket.fileno # => 10 # とりあえず閉じる listening_socket.close
プロセスが死ぬ(プロセスが終了する)とは
プロセスが死ぬ(プロセスが終了する)とは、そのプロセスの実行が終了することを指します。プロセスは、プログラムが実行された際に作成され、そのプログラムの実行が完了したり、エラーが発生して強制的に終了したりすると、そのプロセスは終了します(プロセスが死ぬ)
もし、プログラムの最中に親プロセスが死んだら、残された子プロセスはinitプロセス(macだとlaunchdプロセス)を親として、紐付けられます。
# kill_parent.rb pid = Process.fork if pid.nil? # exec 'ruby -e p "hello"' # 子プロセス # 親プロセスのidを取得する puts "親プロセスid: #{Process.ppid}" # 親が死ぬまで2秒まつ sleep 2 # 親プロセスが死んだ後のppid puts "親プロセスid: #{Process.ppid}" sleep else # 親プロセス sleep 1 # rubyプログラムを終了させる # つまり、実行中のプロセスがなくなるので、プロセスが死ぬ exit end
pstree 1 -+= 00001 root /sbin/launchd \--- 11837 yuuki_haga ruby kill_parent.rb
ps PID TTY TIME CMD 11837 ttys003 0:00.00 ruby kill_parent.rb 64897 ttys003 0:04.37 -zsh -g --no_rcs
親プロセスにプロンプトが対応しているので、親プロセスが終了したら、子プロセスの終了に関わらずプロンプトが入力可能状態になります。
ゾンビプロセス
子プロセスが実行終了しているにもかかわらず、親プロセスに wait されないとプロセスが回収されず、ゾンビプロセスとして残ってしまいます。 以下のコード例を見てみましょう
pid = Process.fork if pid.nil? # 子プロセス # 子プロセスは即死する exit else # 親プロセス # 子プロセスのpidを出力 puts pid loop do sleep end end
子プロセスが即死しているのに、親プロセスがそれに気づかないでずっと動いていると、子プロセスが成仏できずにゾンビ化します。STATがZだと、ゾンビプロセスを意味します。
ps 13232 PID TT STAT TIME COMMAND 13232 s003 Z+ 0:00.00 <defunct>
ゾンビプロセスの問題点は、ゾンビプロセス自体の処理は完了しているのに、ゾンビプロセスがずっと存在し続けるせいでメモリなどのコンピュータリソースを無駄に消費してしまうことです。
親プロセスと子プロセスの処理が終了したパターンについてまとめると、
- 親プロセスの処理が完了、子プロセスの処理が完了すると、どちらのプロセスも終了する。
- 親プロセスの処理が続いている、子プロセスの処理が完了している、しかし親プロセスで子プロセスの終了を検知しないと、子プロセスがゾンビプロセスになる。
- 親プロセスの処理が終了、子プロセスの処理が続いている場合、子プロセスはinitプロセス(launchdプロセス)の養子になる。
pstree -p pidで、pidの親プロセスを特定できます。
pstree -p 27938 -+= 00001 root /sbin/launchd \--- 27938 yuuki_haga ruby parent.rb
シグナルとは
シグナルとは、プロセスに送る信号のようなものです。 シグナルもプロセス間通信の一つのようです。
プロセスはプロセス間通信やファイルディスクリプタを通じて外界と入出力のやり取りをする以外に、シグナルを利用して外界とやりとりします。
プロセスにシグナルを送るためには、killコマンドを使います。killはプロセスに対してシグナルを送るためのコマンドです。
ruby -e "loop { sleep }" &
kill -INT 15663
Traceback (most recent call last):
3: from -e:1:in `<main>'
2: from -e:1:in `loop'
1: from -e:1:in `block in <main>'
-e:1:in `sleep': Interrupt
[1] + 15663 interrupt ruby -e "loop { sleep }"
killコマンドでSIGINTというシグナルをrubyプロセスに送ったことで、rubyのプロセスが死んだことが確認できます(killでSIGINTシグナルを指定するときは、SIGを書かなくて良い)。 SIGINTシグナルをプロセスが受け取ると、デフォルト値では、そのプロセスは実行を停止します。
SIGINTシグナルをプロセスが受け取った時に、挙動を変更したいなら、Signalモジュールのtrapメソッドを使います。
trap("INT") do
warn "ぬわーーーーっっ!!";
end
loop do
sleep;
end
上のコードを実行した場合、psで以下のように表示されます。
ps PID TTY TIME CMD 30463 ttys000 0:00.11 ruby papas.rb 71698 ttys000 0:02.61 -zsh -g --no_rcs 81408 ttys002 0:01.41 -zsh -g --no_rcs 64897 ttys003 0:05.34 -zsh -g --no_rcs
killコマンドで、プロセスid 30463のプロセスにSIGINTシグナルを送ってみます。
kill -INT 30463
そうするとプロセスを実行してたシェルで以下のように表示されます。
ruby papas.rb ぬわーーーーっっ!!
SIGINTシグナルではこのプロセスは終了させられないので、SIGTERMシグナルを送ってみます。そうすると、プロセスを終了させることができました。
kill -TERM 30463
最後に、主要なシグナルについてまとめておきます。
- SIGINTシグナルは、プロセスの実行に対して割り込みをかけるシグナル。
- SIGTERMシグナルは、プロセスの実行を終了するシグナル
- SIGKILLシグナルは、プロセスを強制終了するシグナル
プロセスグループ
プロセスは、必ず一つのプロセスグループというものに所属しています。
ps -o pid,pgid,command PID PGID COMMAND 13247 13247 -zsh -g --no_rcs 19375 19375 ruby -e sleep 64897 64897 -zsh -g --no_rcs
子プロセスは、親プロセスと同じプロセスグループに所属します。
# fork.rb Process.fork sleep
ps -o pid,pgid,command -f PID PGID COMMAND UID PPID C STIME TTY TIME 13247 13247 -zsh -g --no_rcs 501 572 0 11:01PM ttys000 0:02.24 20540 20540 ruby fork.rb 501 64897 0 11:42PM ttys003 0:00.14 20553 20540 ruby fork.rb 501 20540 0 11:42PM ttys003 0:00.00 64897 64897 -zsh -g --no_rcs 501 572 0 3:11PM ttys003 0:04.86
プロセスグループには、リーダーが存在していて、そのリーダーは、PIDとPGIDが同じプロセスです。
プロセスグループのメリットは、killコマンドでプロセスグループを指定することで、プロセスグループに所属しているプロセスを一気に全て消すことができることです。kill で pid を指定する部分に、"-" を付けてあげると、pid ではなくて pgid を指定したことになります。
ps -o pid,pgid,command -f PID PGID COMMAND UID PPID C STIME TTY TIME 13247 13247 -zsh -g --no_rcs 501 572 0 11:01PM ttys000 0:02.31 20540 20540 ruby fork.rb 501 64897 0 11:42PM ttys003 0:00.14 20553 20540 ruby fork.rb 501 20540 0 11:42PM ttys003 0:00.00 64897 64897 -zsh -g --no_rcs 501 572 0 3:11PM ttys003 0:04.86
kill -INT -20540
ps -o pid,pgid,command -f PID PGID COMMAND UID PPID C STIME TTY TIME 13247 13247 -zsh -g --no_rcs 501 572 0 11:01PM ttys000 0:02.39 64897 64897 -zsh -g --no_rcs 501 572 0 3:11PM ttys003 0:04.87
並列処理について
並列処理を行うには以下の2つの方法があります。
- 子プロセスを複製する
- プロセス内のスレッドを複製する
ここは後々深ぼろうと思います。
参考記事
なるほどUNIXプロセスを読んでいく #Ruby - Qiita
【Linux カーネル: OS 基礎入門2】CPU、プロセス管理 | ほげほげテクノロジー
「UNIX ドメインソケット」と「ソケット」について比較する #UNIX - Qiita
Goメモ-103 (Go で Unix domain socket (AF_UNIX) のメモ) - いろいろ備忘録日記
UnicornとNginxの接続方法は、UNIXドメインソケットとリバースプロキシの2つの方法がある - kasei_sanのブログ
UNIXドメインソケットとは - 意味をわかりやすく - IT用語辞典 e-Words
ソケット通信の仕組みをスライド図解と Go 実装でまとめてみる
イケてるエンジニアになろうシリーズ 〜メモリとプロセスとスレッド編〜 - もろず blog
https://www.info.kindai.ac.jp/OS/lecture/OS03note.pdf
【メモ】AWS EC2上に立てたRailsアプリでサイズの大きいファイルをアップロードすると 502 Bad Gateway となった話|石灰
Linux メモリ不足で発生するOOM Killerによるプロセスの突然死の確認&回避方法|ITの魔力
自分が得意なこと、苦手なことをまとめる
目次
- 目次
- 価値観
- 自分が得意なこと
- 自分が苦手なこと
- スピードを求められることが苦手。自分のペースで落ち着いてやりたい
- 予測できないものにすごい不安感を覚える。予想できない急な対応に弱い
- 頭の中で考えていることなどの、目には見えない抽象的な概念を言語化して伝えるのは苦手
- 文章も具体的に書いてないと分からん。意図する意味を理解できない
- 相手に声だけで曖昧に指示されるのが苦手。何もわからん。
- 基準が具体的に決まっていないものが苦手
- キーボードとかの周囲の騒音が気になって集中できない。
- r - kとか105 * 105とかの計算が苦手。
- 瞬時の記憶力が微妙。急に言葉でワーっと言われても覚えられない。脳の処理速度が追いつかない。
- 人が無理だともう無理ってなりがち
- やらないといけないことが急に4個くらい一気に出現すると、ちょっとパニックになって、どれも中途半端に終わる気がする。
- 一つのでかいタスクを渡されると、ちょっとどこから手をつければ良いのか、若干焦る。
- とにかく面接が苦手
- 自分の強みを伸ばそう
- 今後やりたいこと
- 参考記事
価値観
自分の価値観については、以下の記事を見るとわかるかも知れません。 ただ、現在は多少変わってたりするのかなと思っています。
自分が得意なこと
自分のペースで自分で考えてやるのは得意
自分が好きな蓄積されたスキルを使って、仕事ができるものは得意
変化のないものであればあるほど、好きです。 フロントエンドというよりかは、バックエンド系のスキルの方が面白いなと思います。
目には見える事実を人に伝えること、その事実を元に自分で解決策を考えることは得意。
図を元に理解することは得意
これは課題だな、解決せんとなって思えば思うほど、自分の能力を使えばより本質的なことに集中できると思えば思うほど、やる気が出て主体的に行動できるタイプだと思う。
自分が通ってきた道であればあるほど、よりそのように感じるかもしれません。 エンジニアのやることはモダンな技術を触ることではなくて、課題を解決することです。そうなると自分はやっぱりRailsとReactを使うべきだな、もっと極めるべきだなと思っています。
自分が苦手なこと
スピードを求められることが苦手。自分のペースで落ち着いてやりたい
特に飲食とかで6件くらい同時に注文が来るとすごく焦って何をしていいかわからなくなるので、そこは向いていないなと感じています。
予測できないものにすごい不安感を覚える。予想できない急な対応に弱い
先の見通しが立たないもの、いつもと違うことをするってなると、人一倍不安に感じると思います。そのため、仕事のやり方に自分なりのこだわりの強さがあるかも知れないです。
急になんかやれって言われると、不安感が勝ちます。 先が見えなすぎて安心感が持てないとダメです。
頭の中で考えていることなどの、目には見えない抽象的な概念を言語化して伝えるのは苦手
文章も具体的に書いてないと分からん。意図する意味を理解できない
言葉のまま受け取ってしまいます。言葉から意味することを簡単に理解できないです。言葉を急になんか裏の意味を込めて言われると意味分からんです。
相手に声だけで曖昧に指示されるのが苦手。何もわからん。
声だけで指示するなら、具体的に指示してくれないと分からんです。図があると一瞬で分かります。基準が人によって違うので、何かやってほしいなら、何をやるかを具体的に言ってほしいです。急にやれって言われても分からんです。
基準が具体的に決まっていないものが苦手
曖昧なものが苦手かも
キーボードとかの周囲の騒音が気になって集中できない。
r - kとか105 * 105とかの計算が苦手。
苦手ではないけど、人から突然急にやれって言われると意味分からなくなります。方針を具体的に言ってほしいです。やっぱそこの計算スキルは人より遅いなと感じます。なのでその能力は無理に伸ばそうとするのは今後はやめときます。
瞬時の記憶力が微妙。急に言葉でワーっと言われても覚えられない。脳の処理速度が追いつかない。
これは知っているものなら、多分この現象にはならないと思います。
人が無理だともう無理ってなりがち
結構最初のオーラを見て、この人無理だなと感じがちかもしれません。 個人的には、顔とか言動に結構出る気がします。
やらないといけないことが急に4個くらい一気に出現すると、ちょっとパニックになって、どれも中途半端に終わる気がする。
最近、ホワイトボードに優先度の高い順でタスク化することで、これは防げているのかなと思っています。
一つのでかいタスクを渡されると、ちょっとどこから手をつければ良いのか、若干焦る。
これも同様に、ホワイトボードにやることをまとめているので、多少は防げているのかなと思っています。
とにかく面接が苦手
見定められている場で急にこれ答えろと言われて、自分の頭で考えたことを言語化して相手に伝えるのが苦手です。最近はカンペを作って入るのですが、やっぱ苦手です。
自分の強みを伸ばそう
弱みを伸ばすのは、限界があります。できるだけ自分の得意なことを伸ばしましょう。自分は計算系が苦手で人より考えるスピードが遅いと感じるので、そこを伸ばすのは一旦ストップして、以下のことを伸ばしていこうと思います。
パフォーマンスチューニング
課題解決が好きなので、ここら辺にも手を出してみようと思います。 計算系のスキルが微妙なので、そこを補うためにも、ここは結構重点的にやろうと思います。事実を元に仮説を立てて、実行する。そこのスキルはある程度あるのかなと感じています。データベースやアプリケーション、インフラなどそこら辺の知識が必要だと思います。
システムアーキテクチャ
インフラ周りやアプリケーションサーバーどうするかとか、そこら辺の設計が結構好きな気がします。
ソフトウェアアーキテクチャ
DDDとか割と関心がある気がするので、ここも手を出してみたいです。 やっぱビジネス要件を落とし込むときに、どうしてもテーブル設計とかモデルの設計が関わってくる気がするので、ここら辺の知識を積極的に取り入れていきたいと思います。
テスト
テストは割と好きなので、ここは爆速できるようにします。 いろんな種類のタイプのテストをかけるようにしておきます。
今後やりたいこと
バックエンドの領域でサービスの成長に貢献したい
バックエンドとかデータベースとかRailsが好きだから、そこの経験値をもっと増やしたいと思っています。
とはいえ、お金をもらっている以上、Reactをもしやるってなったら全然やります。
今その状況で何を求められているのか、自分の持っている能力をどのように使えばそれを達成できるか、そこが見えていないと、自分が自分がってなりがちです。お金をもらっている以上は、プロとして、貢献しようと思います。 理想とする完璧を状態を目指しすぎないで、徐々により良くしていきましょう。
参考記事
高校2年で芸人の道を決意! 小籔 千豊さんに聞く! 「誰かのために頑張る生き方」とは【高校生なう】|【スタディサプリ進路】高校生に関するニュースを配信
“やりたいこと”を考えすぎるな。4年で新喜劇座長になった小籔千豊の「伸びる若手論」|新R25 - シゴトも人生も、もっと楽しもう。
仕事をする際に、自分が何に対してモチベーションが上がるのかを理解する
目次
- 目次
- 概要
- 自分が何に対してモチベーションが上がるのかを理解する
- 16personaritiesの結果を元に、自分の性格を分析してみる
- 大勢で集まるより、一人の時間が好き。常に一人の時間を必要としている。
- 自分がどうありたいかを常に模索している気がする。そのためには、どんな行動を取れば良いのかもなんとなくわかっている気がする。そのありたい姿に向けて常に決断して、行動したり学習したりしている気がする。
- 近しい人に貢献したいって欲求は自分にありそうだが実は存在しない。根底の欲求は「自分が楽しいなって思う時間を最大化したい」または、「これは解決した方が良いな、本来こうあるべきだよね、そしたら本質的なことにより集中できるよねと思えるペインを抱えているユーザーに対して、自分ごととして捉えて行動する」という欲求なのかもしれない。
- 言語化が苦手で、論理より割と直感で物事を決めている気がする。その意思決定によって影響が出る人の感情も含めて、良い意思決定をしたいと思っている。今まで仕事を決めてきた時も、利益などを比較検討した上で最終的には楽しそうだからって理由が多かった。ただ、自分の中でこう働きたいなって思うものは一貫してあって(専門性を武器に、自分が介在することで、他者に影響を出す)、最近はそこに従って働いた方がうまく働けるのかなと思っている。
- 論理的すぎて感情が伴ってない人は苦手
- 計画性はあるようでそこまでない。いつもやれるだけやるってスタンスでいた。ただ、締め切りなどはちゃんと守ると思う。
- 誰にも縛られたくない。自由でいたい。常に自分の意思で行動している状態が良い
- その場その場の瞬時の判断がめちゃくちゃ大事なアドリブが求められる仕事よりかは、決められた期間で、決められた領域内のスキルを使って自分のペースで結果を出すってスタイルが好き。
- 作るのが好きというか、課題解決した時の周りへの影響度の高さ(ちゃんと周りの人のためになっているか)だったり、理想へのこだわりが強いだけな気がする。あと技術への関心。
- 考えてから行動する
- 集団行動がめちゃくちゃ苦手。相手がどう思うかが直感でわかるから、それを元に相手に合わせないといけないのがめんどくさい
- 大勢を一度に相手するのは苦手
- 概念的なことを考えるのが好き。複数の具体から共通事項を取ってきて、どう抽象化できるかを考えるのが好き。
- 相手が話している際にある物事について考え出すと、相手の話を聞いていない時がある。
- 複数の物事を同時並行でやるのが苦手。一度に一つのことしかできない
- 自分がどう働きていきたいかが明確だったり、過去の成功体験からの一貫性を求めているので、キャリアにすごく関心があると思う。チームプレーとか事業のためになんでもやれとかは無理だと思う。逆にいうと融通がきかない
- 流行に興味を示さない
- 割と主観的(客観的に物事を捉えたい..)
- 争い事とかは好きじゃないが、自分の中での大切にしたい価値観はちゃんと主張している気がする。
- 「これは解決した方が良いな、本来こうあるべきだよね、そしたら本質的なことにより集中できるよねと思えるペイン」を抱えているユーザーに対して、自分ごととして捉えて行動できるのかもしれない
- どんな仕事が向いているか
- つまり、どんなふうに働けば良いのか
- 参考記事
概要
10月ごろから転職活動をしていたのですが、転職活動を通して、自分が何に対してモチベーションが上がるのか、今一度振り返ってみます。
自分が何に対してモチベーションが上がるのかを理解する
- 求められる成果は何か
- その成果は自分のモチベーションを上げてくれるものなのか
- モチベーションが上がるから、より仕事で成果を出そうってなる気がする。だから成果がモチベーションを上げてくれるかはすごく大事
- その成果を出す際に取り組む業務は自分にとって楽しいのか、やりたいことなのか
ここがはっきり分かることで、楽しいと思える時間を最大化することができ、逆につまらない時間を最小化できます。ゆえに、QOLを上げることができます。
上に挙げたことが分かるようになるためには、自分自身の価値観や過去の経験を徹底的に深掘りしなければなりません。その際に以下のような「性格診断ツール」が役に立ちます。
自分自身はINFJ-A型だったのですが、
- 自分自身の内側に目を向ける、少人数で関わることを好む
- 常に未来に目を向け、可能性を重視する。変化を恐れず、自身の直感を信じて行動できる
- その時々で得ることができる利益などを比較検討して、自身が共感できるかどうかという「感情」に基づいて判断する
- 几帳面で計画的な一面があり、タスクや締め切りなどは必ず守る
というタイプだそうです。
この結果を見て、確かになあと思う部分もありましたが、ちょっと違うかなという部分もありました。なので、自分の性格を可能な限り以下に言語化してみようかなと思います。
16personaritiesの結果を元に、自分の性格を分析してみる
16personaritiesの結果を元に、自分の性格を分析してみます。
大勢で集まるより、一人の時間が好き。常に一人の時間を必要としている。
- 仲良い人と5人くらいで集まるなら、全然OK。どうでもいい人と大勢で集まるとかはあまり好きではない。どうでもいい人とどうでもいい話をするより、仲の良い人と深い話をするのが好き
自分がどうありたいかを常に模索している気がする。そのためには、どんな行動を取れば良いのかもなんとなくわかっている気がする。そのありたい姿に向けて常に決断して、行動したり学習したりしている気がする。
- 以前は「バックエンドの専門性を最大化して、ビジネスを成長させたい」とよく言っていたが、よくよく深ぼると、「自分のバックエンドの専門性を最大化して、自社のソリューションを成長させて、これは解決した方が良いな、本来こうあるべきだよね、そしたら本質的なことにより集中できるよねと思えるペインを抱えているユーザーの課題を解決したい。よりユーザーが本質的なやりたいことに時間を使うことができるような未来を実現したい」である。多分これが現時点での自分の中での理想な気がする。その際には以下の観点が重要になる。
- ソリューションに共感できる(ソリューションが本質的か)
- 課題に共感できる(ユーザーが抱えている課題は解くべきなのか、本当に解くべき課題を持ったユーザーなのか?)
- ここで自分の経験が出てくる
- バックエンドの専門性が伸ばせる環境か
- 1日の中でどのくらいそのソリューションを、どんなユーザーが使うのか。できればこの頻度が多いほど、課題を抱えているレベルが高いから、より解決したいって思うかも
- どんなクライアントなのか具体的に想像できればできるほど、良い。物流は純粋にイメージできなかった。
近しい人に貢献したいって欲求は自分にありそうだが実は存在しない。根底の欲求は「自分が楽しいなって思う時間を最大化したい」または、「これは解決した方が良いな、本来こうあるべきだよね、そしたら本質的なことにより集中できるよねと思えるペインを抱えているユーザーに対して、自分ごととして捉えて行動する」という欲求なのかもしれない。
- 何でもいいけど周りに貢献できたら嬉しいとか、ものを作れたら嬉しいとか、それが自分の根底の欲求にはならないなと感じた。
言語化が苦手で、論理より割と直感で物事を決めている気がする。その意思決定によって影響が出る人の感情も含めて、良い意思決定をしたいと思っている。今まで仕事を決めてきた時も、利益などを比較検討した上で最終的には楽しそうだからって理由が多かった。ただ、自分の中でこう働きたいなって思うものは一貫してあって(専門性を武器に、自分が介在することで、他者に影響を出す)、最近はそこに従って働いた方がうまく働けるのかなと思っている。
論理的すぎて感情が伴ってない人は苦手
計画性はあるようでそこまでない。いつもやれるだけやるってスタンスでいた。ただ、締め切りなどはちゃんと守ると思う。
- 焦りたくない、常にマイペースでいたい
誰にも縛られたくない。自由でいたい。常に自分の意思で行動している状態が良い
その場その場の瞬時の判断がめちゃくちゃ大事なアドリブが求められる仕事よりかは、決められた期間で、決められた領域内のスキルを使って自分のペースで結果を出すってスタイルが好き。
- 飲食, 小売, 派遣, 塾講のようなサービス業, SIerの運用/保守, Webエンジニアで今まで働いてきたが、飲食, 小売は割とアドリブ力が求められるのと多くの人と接するので結構きつかった。派遣, 運用/保守は業務がつまらなすぎるのと、つまらない業務に何もモチベーションが上がらないので、そこがきつかった。
- Webエンジニアは面白いっちゃ面白いんだけど、仕事の結果が自分のモチベーションを上げてくれる感じがしなかったな。純粋に能力が足りてないってのもあるんだけど、作ったとて、「あ、できた」くらいの感情しかなくて、出した結果に対してモチベーションが上がらなかったな。唯一モチベーションが上がったのは、自分ができないようなことができるようになった時。ただそれは周りに価値を出しているって感じがしないから、モチベーションが上がっているのかは微妙。多分めちゃくちゃできるようになって、周りの人にいろんな価値を出せるようになれば、すごい能動的に動けるようになってモチベーションも上がっていくのかなと思う。 機能を作るというよりかは、ボトルネックを解消してパフォーマンスを向上させたり、チームメンバー全体の開発の生産性を上げたり、デプロイのスピードを上げたり、そういう方が好きなのかなという気もしている。作ることより、どういう理想に向かうかを考えて、現状ある選択肢からこの課題をどうやって解決するかを考えるのが好きな気がする。周りへの影響度も高いし、そこにモチベーションが湧いている気がする。感謝されるとよりモチベーションが上がる。作るのすごい好きかって言われると微妙な気がしてきた。設計能力が高いこともすごいっちゃすごいんだが、「設計の良さに気づく時って、新しいビジネス要件を追加する際に変更一切加えなくてええのか、すご!」ってなる時だと個人的には思っている。
作るのが好きというか、課題解決した時の周りへの影響度の高さ(ちゃんと周りの人のためになっているか)だったり、理想へのこだわりが強いだけな気がする。あと技術への関心。
- 技術への関心が強いから、OS, プロセス, LInux, ネットワーク, AWS, Docker, Terraformなどの突き詰めていかないと分からないような低いレイヤーなどは割と好きかもしれない。SREへの方向性にも伸ばせると良い気がする。その低いレイヤーに付随してRailsなどのバックエンドも好き。逆にフロントエンドなどの高レイヤーはデザインとユーザーの使い心地に関わっているから、割と作ることに関心がある人が好きな領域だと思う。フロントエンドやってても自分は問題解決って感じがしないのもあって、そこまで好きではないのかもしれない。
- テーブルやクラスの設計ができて、果たして自分のモチベーションがどんどん上がっていくのかが謎。周りの人への影響力の方が大事な気もする。そこを伸ばすと結果に対してモチベーションが上がって、より能力を伸ばそう、仕事をやろうってなって、正のループに入る気がする
- 自分が楽しいなって思う時間がバックエンド周りに多いなと感じる(設計や実装しかり、パフォーマンスチューニングしかり)。それらの共通点は課題解決だと感じる。理想を定義して、どのように設計・実装したら、ビジネスの仕様変更や仕様追加に対して拡張性のあるソフトウェアになるか、そこを考える作業が面白い気がする。チューニングに関してもどのような課題があって、その課題に対してファクト(事実)から仮説を考えてそれを元にまた試行錯誤してエラーを解決するって作業が面白い気がする。
- 技術選定とかも、どんな選定をすれば採用が強くなるか、周りのエンジニアがいかに楽できるかとか考えるの好きだから、それも一種の課題解決なのかなとも感じる
- ものづくりが好きってよりかは課題解決の方が好きな気がする。自分の中でものづくりが好きな人って技術を手段と捉えていて、技術を使って、動くものを作って価値を提供することに喜びを感じるタイプだと個人的には思っている。自分はそこよりかは長期的に動くもの、信頼性のあるものを作りたいなって気持ちが強いから、設計とか他のエンジニアにとってわかりやすいコードになっているか、そこら辺のクオリティは妥協したくない気がするなあ。前々職は動けば良しでデグレしまくってたし、コンポーネントの設計もめちゃくちゃで、長期的にサービス拡張し続けるのむずいでしょって思ってたから、その人たちとの志向性は全く合わなかったな...
考えてから行動する
集団行動がめちゃくちゃ苦手。相手がどう思うかが直感でわかるから、それを元に相手に合わせないといけないのがめんどくさい
- 人混みとかも割と苦手
大勢を一度に相手するのは苦手
概念的なことを考えるのが好き。複数の具体から共通事項を取ってきて、どう抽象化できるかを考えるのが好き。
相手が話している際にある物事について考え出すと、相手の話を聞いていない時がある。
複数の物事を同時並行でやるのが苦手。一度に一つのことしかできない
自分がどう働きていきたいかが明確だったり、過去の成功体験からの一貫性を求めているので、キャリアにすごく関心があると思う。チームプレーとか事業のためになんでもやれとかは無理だと思う。逆にいうと融通がきかない
流行に興味を示さない
割と主観的(客観的に物事を捉えたい..)
争い事とかは好きじゃないが、自分の中での大切にしたい価値観はちゃんと主張している気がする。
- ユーザーにとってどうあるべきか。(ユーザーは周りで働いている人や実際にそれを使う人)。理想を描く
- それが持つ思想を大事にする
- 感情に寄り添う
- 人を信じる、自分を信じる
- 学ぶために失敗はつきもの。ただ同じ失敗を繰り返さないように失敗から必ず教訓を学ぶ。成功確率を上げていく意識を常に持つ。
- エクセルで管理している。
- 本質的なことに集中できている状態が好き
- 己の立場を明確にできない奴は、いざという時に一番頼りにならない
- 強くて優しくて丁寧である人であれ
- 塾講時代の先生にそんな感じの人がいて、めっちゃ尊敬していた。こうありたいって思っていた。
- 人生は願望だ、意味じゃない。
- いかに短くいかに伝わるか。いかに本質的な伝えたいことだけを残して、無駄を削ぎ落とすか。
- やっぱ書くことで無駄がわかる。無駄を削ぎ落とせる。無駄を言うと結局何を言いたいのか分からなくなる。何を主張したいのかわかりづらくなる。
- 自分の物差しで対象や状況を見過ぎない。その状況で求められていて、かつ自分ができそうなことをやる
- くらいつく。そうするとチャンスが回ってくる可能性がある。みてくれている人はちゃんと見ている。
- あの時こうすれば良かったとダサいことを言わない。そう思うなら、その時ちゃんと主張する。それが通っても通らなくてそう自分で決めたんだから、決めたことにぐちぐち言わない。過去を振り返るんじゃなくて、今どうするのかを考える。
「これは解決した方が良いな、本来こうあるべきだよね、そしたら本質的なことにより集中できるよねと思えるペイン」を抱えているユーザーに対して、自分ごととして捉えて行動できるのかもしれない
- 明らかにこれ課題を抱えているなって、これは解くべき課題だな、本来こうあるべきだよねって思えるペインを抱えているユーザーであればあるほど、自分ごととして捉えて行動できる気がする。
- 自分たちが提供するソリューションが本質的ではなかったり、本当にこの人たち課題を抱えているのか?と定義したペインに対して自分が疑問を思っちゃったら、自分ごととして動けない気がする。
- どのようなものに対してそういう感情を抱くのかというと、自分が実際に似たような経験をして苦痛を感じたものである。もしくは、明らかにこの人頑張っているけど、報われていないなって思うものである。
- 本質的ではないルール(紙の業務や年功序列)、頑張っているけど本質がわからなくて報われない人など、そこら辺が自分が経験した中で、一番自分ごととして捉えられてた。
どんな仕事が向いているか
この記事によると、以下のような傾向のある仕事が向いているそうです。
- 創造的でクリエイティブ、ユーザーの心理と向き合う共感力が生かせる 職種で強みを発揮できる
- 戦略など抽象度の高い仕事が遂行できる
- 直感的で大胆な決断をすることができる
- やりたいこと、心から好きなことで頭角を現すことができる
これらのことを考慮して、以下のような環境や仕事内容、キャリアの方向性が理想なのかなと思いました。
- できればリモートで集中できると良い。ただ、わからんこともあるから対面でもやりたい。(週3リモートくらいが理想)。相手に合わせると疲れるからできるだけ一人のペースで働けると嬉しい
- 論理的すぎず、感情を尊重するような環境が良い
- 専門性を武器に、自分が介在することで、他者に影響を出せる状態であると良い
- 焦りたくない、常にマイペースでいたい。アドリブより、決められた期間で決められた領域内のスキルを使って自分のペースで結果を出すのが好き。できるだけ準備して挑める方が、自分のvalueを発揮しやすい
- 自分の理想的なキャリアを汲み取ってタスクをアサインしてもらえるような環境はすごく良いと思う。
- 共感性を伴う戦略を立てる仕事は意外と向いてそう。
- 自分の強みをいかせて、かつ、ストレスがかからない仕事だと良い
- 自分が仕事で主体的に動いて価値を出して、クライアントやチームメンバーに感謝される、良い結果や良い影響を与えられているとよりやる気が出そう。てなるとやっぱ能力は必要か。
- 自分が働くことによって、自分が介在することによって、自分と関わってくれた人に良い影響や価値を与えたいなと思っている。
- どういう理想に描きたいのかを考えて、現状ある選択肢からこの課題をどうやって解決するかを考えて、結果を最大化するのが好きな気がする。
逆に以下のような仕事は向いていないのかなと思います。
- ストレスが多い仕事
- 多くの人と接する仕事(人の気持ちを汲み取って気を使いすぎてしまう点がある、チームで動く仕事もできるだけ避けた方が良いそう)
- 瞬時の判断が求められる仕事(臨機応変な予測不可能な対応が苦手だから)
- 自分の専門外の領域の仕事
つまり、どんなふうに働けば良いのか
つまり、現状だと
求められる成果
- 「どういう理想を描きたいのかをクライアントや周りのエンジニアやビジネスサイドの人と相談して考えて、現状存在する選択肢からこの課題をどうやって解決するかを考えて、自分のバックエンドの専門性を最大化して、長期的に運用できて、かつユーザーにちゃんと価値を提供できて、使いやすいサービスを作っていくこと。そうすることで、よりユーザーが本質的なことに自分の時間を費やせるようにできたら嬉しい」が自分の中での理想な気がする。拡張性のある設計やバックエンドの実装。ボトルネックを解消してパフォーマンスを向上、チームメンバー全体の開発の生産性の向上、CIやデプロイのスピードを上げたり、いかにチームメンバーが楽できるように仕組みで解決できるかとか、プロジェクトのあるべき姿を作るとか、そういうのが好きなのかも。
その成果は自分のモチベーションを上げてくれるものなのか
- 自分が仕事で主体的に動いて価値を出して、クライアントやチームメンバー、ユーザーに良い影響を与えられたら嬉しい。よりやろうって思う。あと、自分の介在価値をちゃんと感じれたらより嬉しい。
その成果を出す際に取り組む業務は自分にとって楽しいのか、やりたいことなのか
- バックエンドの業務(拡張性のある設計、バックエンドの実装、ボトルネックを解消してパフォーマンスを向上、チームメンバー全体の開発の生産性の向上、CIやデプロイのスピードを上げたり、いかにチームメンバーが楽できるように仕組みで解決できるかとか、プロジェクトのあるべき姿を作るとか)はわりかし楽しいと思う。ただ、SREも向いてそうな気がするから、バックエンド ~ SREまで経験できると良いよね。
参考記事
【お悩み相談企画】これでいいのか?「決めたはずの就活の軸にモヤモヤ」への回答|諸戸友@CROOZ執行役員
メモリの無駄遣い #838|もりしたけん/メンタルトレーニング
アルゴリズムとデータ構造関連で知ったことをまとめる part 1
目次
概要
アルゴリズムに関する基本的な用語
全探索
全探索とは、考えられるすべての可能性を調べ上げることです
線形探索
線形探索とは、一つ一つのデータを順に調べていくことです。
アルゴリズム
アルゴリズムとは、解が定まっている「計算可能」な問題に対して、解を正しく求めるための手続きのことです。 ja.wikipedia.org
設計技法
設計技法とは、アルゴリズムを設計するのに役にたつ考え方のことです。設計技法の一つに貪欲法や動的計画法などがあります。
貪欲法
貪欲法とは、ある問題を部分問題に分割して、その部分問題の最適解をそれぞれ独立に求めて、評価値の高い順に取り込んでいくことで、問題の解を出す考え方のこと
余談ですが、部分問題を解く際には、再帰的な考え方をするとうまく行きやすいです。
貪欲法では、必ずしも最適解を求められるわけではないです。ただし、解に近い値を得ることができます。その点を注意しましょう。
区間スケジューリング問題
区間スケジューリング問題とは、それぞれの区間が重複せず、それぞれの区間の数を最大化するためにはどうすればよいかを考える問題である。
この記事がわかりやすかったです。
二分探索
二分探索とは、ソート済みの解の候補を半分にしながら、解を探索していくアルゴリズムです。二分探索はバイナリサーチとも呼びます。
二分探索を使いたいときに重要なのは「質問」です.次のような質問を見つけることが出来たら,二分探索が使えます.
- Yes / No で答えられる質問である.
- あるところを境界として,そこより小さいところではずっと Yes だし,そこより大きいところではずっと No である.
- または,あるところを境界として,そこより小さいところではずっと No だし,そこより大きいところではずっと Yes である.
データ構造に関する基本的な用語
データ構造とは
データ構造とは、効率的に管理されたデータの集合体です。
データ構造に対しての操作をクエリ(データの取得、データの更新、データのインサート等々)と呼びますが、どんなクエリが要求されても、迅速にデータを返せるようにデータ構造を設計する必要があります。
グラフ
グラフとは、対象物の関係性を表すものである。 対象物は頂点と呼び、対象物の関係性を表す線を「辺」と呼びます。 友人関係、鉄道路線、タスクの依存関係など、さまざまな関係性をグラフで表現できます。
有向グラフ、無向グラフ
グラフの各辺には向きが考慮されている時があり、その時のグラフを有向グラフと呼びます。グラフの各辺に向きが考慮されていない時は、無向グラフと呼びます。
サイクル
元のグラフの一部であるグラフのことを、部分グラフと呼びます。 サイクルとは、隣接する頂点を辿っていくことで、元の頂点に戻って来れるような部分グラフのことです。ただし多くの場合、パスは「同じ頂点を二度以上通ってはいけない」ものとします。
木
木とは、連結であり(頂点間に辺が存在する)、かつサイクルを持たない無向グラフのことです。
根付き木
根とは、木において、特別扱いする1つの頂点のことです。 根をもつ木のことを、根付き木と呼びます。根をもたない木に対して、そのことを強調するときは根なし木とよびます。 根付き木を描画するときは、下図のように、根を最も上に描くことが一般的となっています。
葉
葉とは、根を除く頂点のうち、その頂点に接続している辺が 1 本しかない頂点のことです。
親、子
根以外の頂点 v について、v に隣接している頂点のうち、根側にある頂点 p を v の親とよびます。 このとき v は p の子であるといいます。
二分木
二分木とは、すべての頂点に対して子の個数が 2 以下であるような根付き木のことです。
ヒープ
ヒープとは、すべての頂点に対して(親の値) >= (子の値)が成立しているような根付き木のことです。
部分木
根付き木の根以外の各頂点 v の親子関係のことを、部分木と呼びます。
木のデータ構造から値を探索したいなら、再帰処理を使えば良い
部分問題などもそうですが、再帰処理を使うとうまく行きます。
木の高さ
木の高さとは、根付き木の各頂点の深さの最大値のことです。
フィボナッチ数
フィボナッチ数とは、フィボナッチ数列を構成する数のことです。一般にFnと表記されます。
メモ化
メモ化とは、一度計算した再帰関数の結果を配列などに保存しておき、再度同じ関数の計算が必要になった際はそこから参照するテクニックのことです。
これにより、同じ関数の計算結果を何度も再帰呼び出しを用いて計算してしまうことを避けることができます。
主要なソートについてまとめる
目次
概要
ソートについて学んだので、まとめます。
今回は以下の基本的な3つのソート
- バブルソート
- 選択ソート
- 挿入ソート
と応用的な3つのソート
をまとめます。 あと、基本的には、ソートするので、ソート済みではない数値を要素とした配列(a)をinputとします。
バブルソート
バブルソートとは
バブルソートとは、隣り合う2項の大小関係を比較してソートしていくよなソート方法です。
具体的な手順
- a[0]とa[1]の大小関係を比較する。
- a[0] > a[1]の場合、a[0]とa[1]の値を入れ替える。1ループごとに入れ替えていく。
- それをどんどん繰り返していって、一番でかい数を一番右端に配置する。
- 一番でかい右端の数を除いて、1 ~ 4の手順を繰り返す
- 最後までループが完了したら、ソートが完了している。
サンプルコード
# @param [Array<Integer>] numbers # return [Array<Integer>] def bubble_sort(numbers) (0..(numbers.length - 1)).each do |i| (1..(numbers.length - (i + 1))).each do |j| if numbers[j - 1] > numbers[j] numbers[j - 1], numbers[j] = numbers[j], numbers[j - 1] end end end numbers end numbers = [6, 1, 2, 9, 0] puts "整列前: ", numbers.join(" ") sorted_numbers = bubble_sort(numbers) puts "整列後: ", sorted_numbers.join(" ") # => # 整列前: # 6 1 2 9 0 # 整列後: # 0 1 2 6 9
選択ソート
選択ソートとは
選択ソートとは、ソート順序が確定していないデータから、最小値を見つけて、その最小値を左に置くことを繰り返すことで、ソートをしていくようなソート方法です。
具体的な手順
- 配列aの最小値を取得する
- その最小値を一番左に配置する。
- 1 ~ 3を繰り返す
- 最後までループが完了したら、ソートが完了している。
サンプルコード
# @param [Array<Integer>] numbers # return [Array<Integer>] def selection_sort(numbers) (0..numbers.length - 1).each do |i| minimum_numbers = numbers[i..].min min_index = numbers.find_index(minimum_numbers) numbers[i], numbers[min_index] = numbers[min_index], numbers[i] end numbers end numbers = [6, 1, 2, 9, 0] puts "整列前: ", numbers.join(" ") sorted_numbers = selection_sort(numbers) puts "整列後: ", sorted_numbers.join(" ") # => # 整列前: # 6 1 2 9 0 # 整列後: # 0 1 2 6 9
挿入ソート
挿入ソートとは
挿入ソートとは、データを整列済と未整列の2つに分類し、未整列データの先頭の要素を、整列済みデータの正しい場所に挿入していくことで、ソートしていく方法のことです。
具体的な手順
- 未整列データの一番先頭の要素を、整列済みデータとする
- 2番目以降の未整列データの一番先頭の要素を、1番目と比較して、適切な位置に挿入する。
- 1 ~ 3を繰り返す。
- 最後までループが完了したら、ソートが完了している。
サンプルコード
# @param [Array<Integer>] numbers # return [Array<Integer>] def insertion_sort(numbers) # 0番目を整列済みとする (1..numbers.length - 1).each do |i| position = i # 指定したインデックス以降で隣り合う2項の大小関係をチェックしている # ここで条件式を満たさないってことは、positionが0か、 # numbers[position]がちゃんとnumbers[position - 1]よりでかい(インデックスに従ってちゃんと昇順になっている) while position.positive? && numbers[position - 1] > numbers[position] numbers[position - 1], numbers[position] = numbers[position], numbers[position - 1] # 一個ずらして、その前の数と大小関係を比較する position -= 1 end end numbers end numbers = [6, 1, 2, 9, 0] puts "整列前: ", numbers.join(" ") sorted_numbers = insertion_sort(numbers) puts "整列後: ", sorted_numbers.join(" ") # => # 整列前: # 6 1 2 9 0 # 整列後: # 0 1 2 6 9
クイックソート
クイックソートとは
クイックソートは、真ん中の要素(インデックスが a.length / 2のような要素)を基準値として、その基準値より大きい要素を集めた配列と、その基準値より小さい配列を集めた配列を作って、作成した配列に対してもクイックソートを繰り返すことで、ソートしていくようなソート方法です。
クイックソートでは1つの大きな問題を複数の部分問題に分けて、それらを再起的に解くことによって、結果的に大きな問題を解いています。つまり、クイックソートでは、分割統治法の考え方を用いていることが分かります。
今までの基本的なソートの計算量はO(N2)ですが、クイックソートの計算量はO(NlogN)であり、早いです。
具体的な手順
- 整列されていない要素の真ん中の値(index = a.length / 2)を求める。この値を基準値とする
- 基準値より小さい配列を作成する。同様に基準値より大きい配列を作成する
- それらの配列に対して、クイックソートを実施する。クイックソートの関数に渡された配列の要素数が1の場合、そのまま配列を返す
- ソートされた左側の配列 + 基準値 + ソートされた右側の配列を実行して、それを戻り値とする。
- ソートされている
サンプルコード
# @param [Array<Integer>] numbers # return [Array<Integer>] def quick_sort(numbers) # 空の配列に対してquick_sortが呼ばれる可能性がある return numbers if numbers.length == 1 || numbers.empty? standard_index = numbers.length / 2 standard_number = numbers[standard_index] left_numbers = numbers.filter.with_index { |number, i| i != standard_index && number < standard_number } right_numbers = numbers.filter.with_index { |number, i| i != standard_index && number >= standard_number } sorted_left_numbers = quick_sort(left_numbers) sorted_right_numbers = quick_sort(right_numbers) sorted_left_numbers.push(standard_number).concat(right_numbers) end numbers = [6, 1, 2, 9, 0] puts "整列前: ", numbers.join(" ") sorted_numbers = quick_sort(numbers) puts "整列後: ", sorted_numbers.join(" ") # => # 整列前: # 6 1 2 9 0 # 整列後: # 0 1 2 6 9
マージソート
マージソートとは
マージソートとは、真ん中のインデックスをさかえめにして2つのグループを作って、そのグループに対して要素が1になるまでマージソートを繰り返して、最終的にソートをしてくようなソート方法です。
具体的な手順
- 真ん中のインデックスをさかえめにして、そのさかえめのインデックス以上のインデックスを持つ配列と、そのさかえめのインデックス未満のインデックスを持つ配列に分ける
- そしてグループに対して、マージソートを再起的に繰り返して、そのグループの要素数が1になるまで繰り返す。
- ソートされたグループを、右側のグループをリバースさせて合体させる(小 ~ 大 ~ 小のレイヤーに配列がなっている)。その後、その合体させた配列の最も左の要素と最も右の要素を比較していって、小さい方を先に別の配列に入れる。その後、合体させた配列から小さい方を削除する。それを繰り返すと、ソートされた配列が完成する。
iをa.length / 2とすると、 クイックソートは、a[0.. i - 1] + a[i] + a[i + 1 ..]でソートしていくが、マージソートは、a[0..i - 1] + a[i..]でソートしていくので、そこを間違えないようにしましょう。
サンプルコード
# Your code here! # @param [Array<Integer>] numbers # return [Array<Integer>] def merge_sort(numbers) # 空の配列に対してquick_sortが呼ばれる可能性がある return numbers if numbers.length == 1 || numbers.empty? middle_index = numbers.length / 2 left_numbers = numbers[0...middle_index] right_numbers = numbers[middle_index..] sorted_left_numbers = merge_sort(left_numbers) sorted_right_numbers = merge_sort(right_numbers) merge_numbers = sorted_left_numbers.concat(sorted_right_numbers.reverse) sorted_merge_numbers = [] until merge_numbers.empty? # 要素が1個しかに場合、 = になるだけ if merge_numbers.first <= merge_numbers.last sorted_merge_numbers.push(merge_numbers.shift) else sorted_merge_numbers.push(merge_numbers.pop) end end sorted_merge_numbers end numbers = [6, 1, 2, 9, 0] puts "整列前: ", numbers.join(" ") sorted_numbers = merge_sort(numbers) puts "整列後: ", sorted_numbers.join(" ") # => # 整列前: # 6 1 2 9 0 # 整列後: # 0 1 2 6 9
ヒープソート
ヒープソートとは
まず、どの頂点に対しても、必ず親の値 >= 子の値が成立する木構造のことを、ヒープだったり、ヒープ木と呼びます。ヒープを作ることで、根の値が一番大きく、一番深い葉の値が一番小さくなります。
ヒープソートでは、ヒープを作った後に、根と葉の値を交換します。その後、元々の根を除いた木に対して、ヒープを作ります。そして同じことを繰り返すことで、最終的にソートされます。
具体的な手順
- 与えられた配列を木構造として捉える(頂点iの値がa[i]、頂点iの子がa[2i + 1]とa[2i + 2])
- 与えられた配列から、ヒープを作る
- ヒープの根と一番深い葉の値(つまり、配列の一番最初と一番最後の値)を交換します。
- その後、元々の根を除いた頂点で、1 ~ 3を繰り返す。
- ソートされている。
サンプルコード
# @param [Array<Integer>] numbers # return [Array<Integer>] def create_heap(numbers) # 調べる対象 # ヒープは親の値 >= 子の値になっていれば良いので、子供は調べなくて良い parent_count = numbers.length / 2 - 1 while parent_count >= 0 k = parent_count loop do # 深い親から先に見ていく parent = numbers[k] left_child = numbers[2 * k + 1] right_child = numbers[2 * k + 2] # left_childがいないってことは、子供が存在しないノード(つまり、子供) break unless left_child maximum_number = if right_child [parent, left_child, right_child].max else [parent, left_child].max end case maximum_number when parent break when left_child numbers[k], numbers[2 * k + 1] = left_child, parent # 交換先で 親が親の値 >= 子の値をチェックする k = 2 * k + 1 when right_child numbers[k], numbers[2 * k + 2] = right_child, parent # 交換先で 親が親の値 >= 子の値をチェックする k = 2 * k + 2 end end # 上の親でチェックする parent_count -= 1 end numbers end # @param [Array<Integer>] numbers # return [Array<Integer>] def heap_sort(numbers) heap = create_heap(numbers) (1..numbers.length - 1).reverse_each do |i| heap[0], heap[i] = heap[i], heap.first heap[0..(i - 1)] = create_heap(heap[0..(i - 1)]) end heap end
終わり
計算量とかの証明がまだ深掘りできていないので、いずれ深掘りしようと思います。
参考記事
leet codeのSQL問題を1日1題解く【1581. Customer Who Visited but Did Not Make Any Transactions】
目次
初めに
今日もSQLの問題を解いて行きます。
問題
セットアップ
以下のSQL文をローカル環境で実行します。
Create table If Not Exists Visits(visit_id int, customer_id int); Create table If Not Exists Transactions(transaction_id int, visit_id int, amount int); Truncate table Visits; insert into Visits (visit_id, customer_id) values ('1', '23'); insert into Visits (visit_id, customer_id) values ('2', '9'); insert into Visits (visit_id, customer_id) values ('4', '30'); insert into Visits (visit_id, customer_id) values ('5', '54'); insert into Visits (visit_id, customer_id) values ('6', '96'); insert into Visits (visit_id, customer_id) values ('7', '54'); insert into Visits (visit_id, customer_id) values ('8', '54'); Truncate table Transactions; insert into Transactions (transaction_id, visit_id, amount) values ('2', '5', '310'); insert into Transactions (transaction_id, visit_id, amount) values ('3', '5', '300'); insert into Transactions (transaction_id, visit_id, amount) values ('9', '5', '200'); insert into Transactions (transaction_id, visit_id, amount) values ('12', '1', '910'); insert into Transactions (transaction_id, visit_id, amount) values ('13', '2', '970');
知らなかった or 理解があやふやな知識
COUNTとGROUP BYの併用
COUNTとGROUP BYを併用することで、グループごとのレコード数をカウントすることができます。
FROM > ON > JOIN > WHERE > GROUP BYの順番で評価される
WHEREがGROUP BYより上にあるのも、グループ化させるよりも前にWHEREの条件を適用させた方が、考慮すべき行数が減るので、WHEREの後にGROUP BYが実行されるのもなんとなく理解できます。
パフォーマンスや得られる結果を考慮すると、この順序になるのは自然なのかなと感覚で理解できます。
解答
こちらのSQLを実行したら、以下のような結果が取得できました。 LEFT OUTER JOINすることで、トランザクションを持っていない顧客も結合後のテーブルに表示させることができました。
SELECT * FROM Visits AS V LEFT OUTER JOIN Transactions AS T ON V.visit_id = T.visit_id
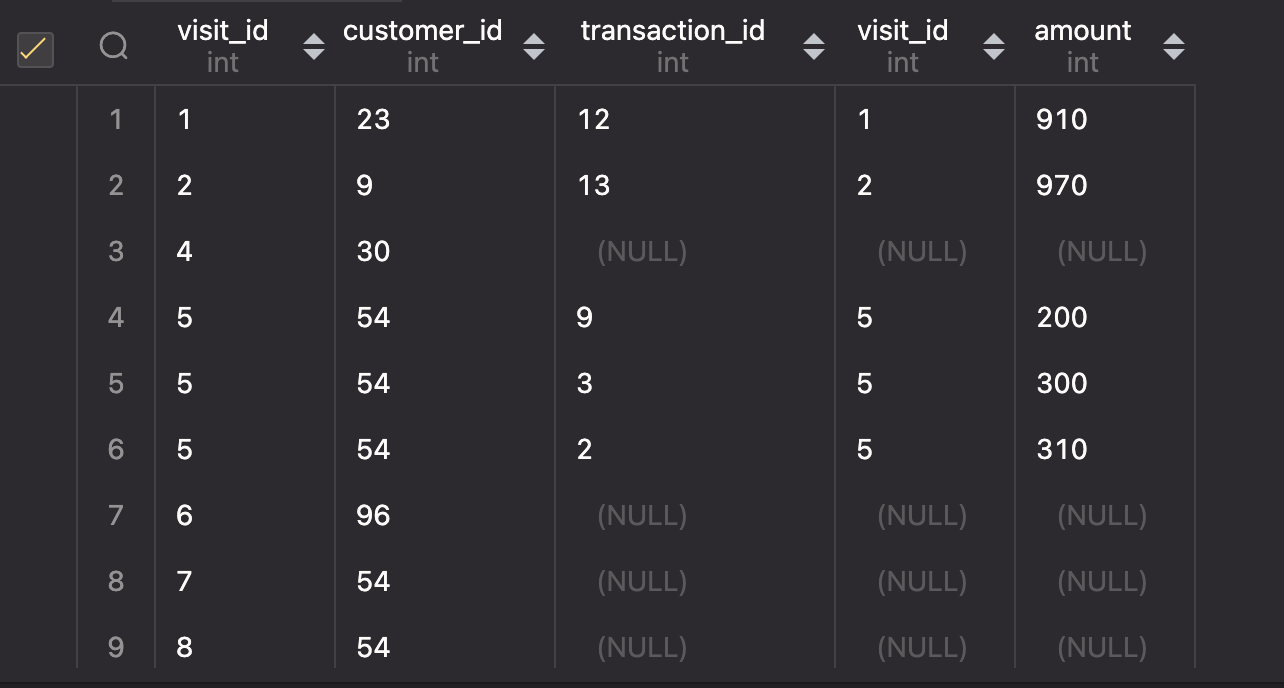
以下のSQL文を実行したら、無事クリアできました。
SELECT V.customer_id, COUNT(*) AS count_no_trans FROM Visits AS V LEFT OUTER JOIN Transactions AS T ON V.visit_id = T.visit_id WHERE T.transaction_id IS NULL GROUP BY V.customer_id
終わり
明日もやります!
参考記事
leet codeのSQL問題を1日1題解く【1068. Product Sales Analysis I】
目次
初めに
今日もSQLの問題を解いて行きます。
問題
セットアップ
以下のSQL文をローカル環境で実行します。
Create table If Not Exists Sales (sale_id int, product_id int, year int, quantity int, price int); Create table If Not Exists Product (product_id int, product_name varchar(10)); Truncate table Sales; insert into Sales (sale_id, product_id, year, quantity, price) values ('1', '100', '2008', '10', '5000'); insert into Sales (sale_id, product_id, year, quantity, price) values ('2', '100', '2009', '12', '5000'); insert into Sales (sale_id, product_id, year, quantity, price) values ('7', '200', '2011', '15', '9000'); Truncate table Product; insert into Product (product_id, product_name) values ('100', 'Nokia'); insert into Product (product_id, product_name) values ('200', 'Apple'); insert into Product (product_id, product_name) values ('300', 'Samsung');
知らなかった or 理解があやふやな知識
内部結合の省略について
JOINのディフォルトが内部結合なのでINNERが省略可能で、左外部結合・右外部結合・完全外部結合のときにOUTERが省略可能なんだよな。
SELECT a,b FROM AAA INNER JOIN BBB ON b = a ----- 省略可能 SELECT a,b FROM AAA LEFT OUTER JOIN BBB ON b = a ----- 省略可能 SELECT a,b FROM AAA RIGHT OUTER JOIN BBB ON b = a ----- 省略可能 SELECT a,b FROM AAA FULL OUTER JOIN BBB ON b = a ----- 省略可能
INNER JOINをJOINと書いた場合、同じように内部結合が実行されるので、覚えておきましょう。 (LEFT OUTER JOINなどの外部結合でも、OUTERの部分は省略できる)
また、内部結合についてはこちらの記事で深ぼっています。
解答
以下のSQL文を実行したら、無事クリアできました。
SELECT P.product_name, S.year, S.price FROM Sales AS S INNER JOIN Product AS P ON S.product_id = P.product_id
終わり
明日もやります!