【AWS:ゼロから実践するAmazon Web Services。手を動かしながらインフラの基礎を習得】セクション11: 【CloudWatch】システムを監視しようで知らなかったことをざっくりまとめてみた
目次
- 目次
- 概要
- システム監視とは
- CloudWatchとは
- Amazon SNS(Simple Notification Service)とは
- EC2で立てたWebサーバーのCPU使用率が60%を超えたら、アラームを出すようなシステムを構築する
- CloudWatchのアラートを確認する
- インフラ構成図
- 参考記事
概要
EC2をCloudWatchで監視して、EC2のCPU使用率が60%を超えたら、アラームを発生させます。CloudWatchがアラームを発生させたら、Amazon SNSというサービスと連携して、運用者の方にメールで通知するという監視体制を構築していきます。
システム監視とは
システム監視とは、 システムを正常な状態に保てるように、稼働状況やリソースを監視することです。 サーバーが正常に稼働しているかを監視したり、サーバーのCPUやメモリなどのリソースが枯渇していないかを監視します。
システム監視の2つの目的
- すぐに障害発生を確認できるようにする
何か障害や問題が起きたときに、すぐにそれが察知できるようにします。 - 復旧にすぐに取り掛かれるようになる
障害が発生したら復旧にすぐに取り掛かれるようにします。復旧にすぐに取り掛かることで、できる限り障害が発生している時間を短くします。
システム監視で具体的に行う4つの作業
- 「正常な状態」を監視項目 + 正常な結果の形で定義する
正常な状態とはどういう状態かをまずは定義します。 - 「正常な状態」ではなくなった際の対処方法を監視項目ごとに定義する
「CPUの使用率が80%以上になったら、もう一台増やす」など対処方法を定義します。 - 「正常な状態」であることを継続的に確認する
モニタリングツールなどを導入して継続的に確認するようにします。 - 「正常な状態」でなくなった場合には通知が来るようにし、すぐ「正常な状態」に復旧させる
復旧ができたら、必要に応じて再発防止策を検討します。
以上の4つの作業をセットにしてシステム監視と呼びます。
監視の種類
監視には大きく分けて2種類あります。
| 監視 | 内容 |
|---|---|
| 死活監視 | 正常にシステムが動作しているかを確認します。サービスやサーバーが落ちていないかを確認します。 |
| メトリクス監視 | パフォーマンスを定量的に確認します。各サーバー等のリソースの状況(メトリクス)がどのようになっているか確認します。こちらは指標を決めて、その指標が閾値以上以下になっているかを確認します。 |
監視する際の2つのポイント
- システムや利用状況は変わるので、足りない項目を都度足していく
監視項目が多すぎると、監視疲れをします。システムも利用状況も変化するので、都度監視項目を調整すればOKです。 - 最初は基本的な要素でOK
CPU、Memory、Disk、Networkの使用率や枯渇をまずは監視します。これらの情報を確認できれば、障害発生時にいつどこで起きたのかが把握できます。
(注)CloudWatchで監視を行いますが、CloudWatchのデフォルトの設定ではメモリの監視が対応していないので、CloudWatchをカスタマイズする必要があります。項目によってはそのような項目もあります。市販の監視ツールを入れていない場合は、CloudWatchで監視します。
CloudWatchとは
CloudWatchとは、 AWSサービスの監視やモニタリングができる運用監視のマネージドサービスです。 EC2やRDSのCPUやメモリのリソース状況(メトリクス)を監視します。メトリクスには閾値を設定でき、その条件を満たすとアラームを発生させることができます。アラームが発生するとAmazon SNSという通知サービスと連携して、Amazon SNSからEメールで通知してくれます。
Amazon SNS(Simple Notification Service)とは
Amazon SNSとは、 通知をしてくれるサービスです。 Amazon SNSでは「PublisherとSubscriber」という考え方を用いています。CloudWatchやEC2がAmazon SNSに対してメッセージを発行(Publish)します。すると、Amazon SNSを通じて、EメールやSNSやEC2が通知を受信します。このPublisherからSubscriberへの通知を管理するために、Amazon SNSではトピックというものを作成します。トピックに誰から誰への通知を記載して管理しています。PublisherとSubscriberを疎結合にするためにAmazon SNSが存在しています。
EC2で立てたWebサーバーのCPU使用率が60%を超えたら、アラームを出すようなシステムを構築する
手順1:
CloudWatchのアラームを作成します。CloudWatchのダッシュボードを開いて「アラーム」→「アラームの作成」をクリックします。次に、「メトリクスの作成」→「EC2」→「インスタンス別メトリクス」をクリックします。いろんな観点からアラームを作成できますが、今回はCPUUtilization(CPUの使用率)をチェックします。監視したいサーバーのCPUUtilizationをチェックします。その後。「メトリクスの選択」をクリックします。期間を1分にしておきます。
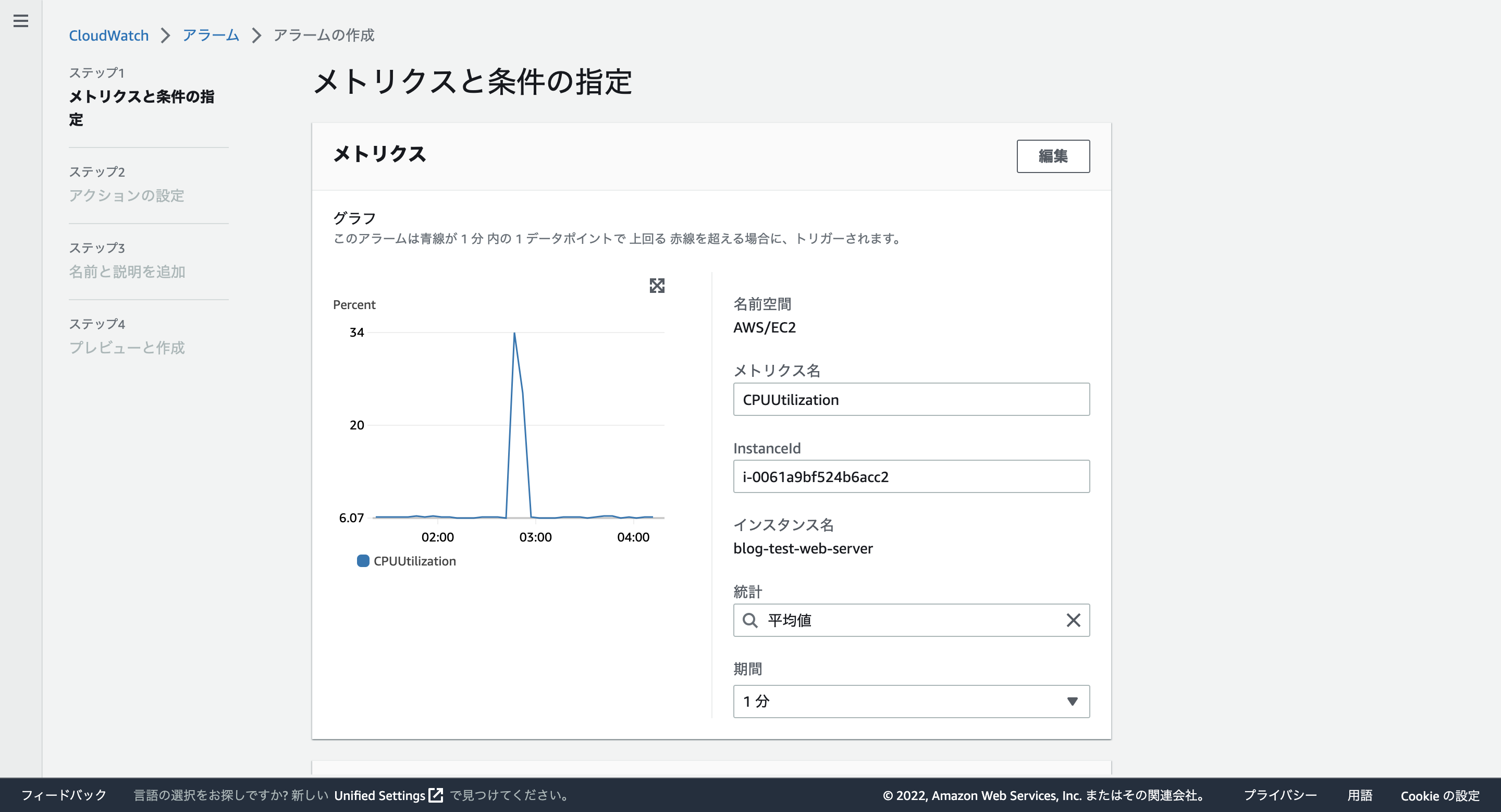
アラーム条件は「以上」にしておきます。閾値を60にしておきます。これはCPU使用率が60%以上になったらアラームを出すように設定しています。その後、「次へ」をクリックします。
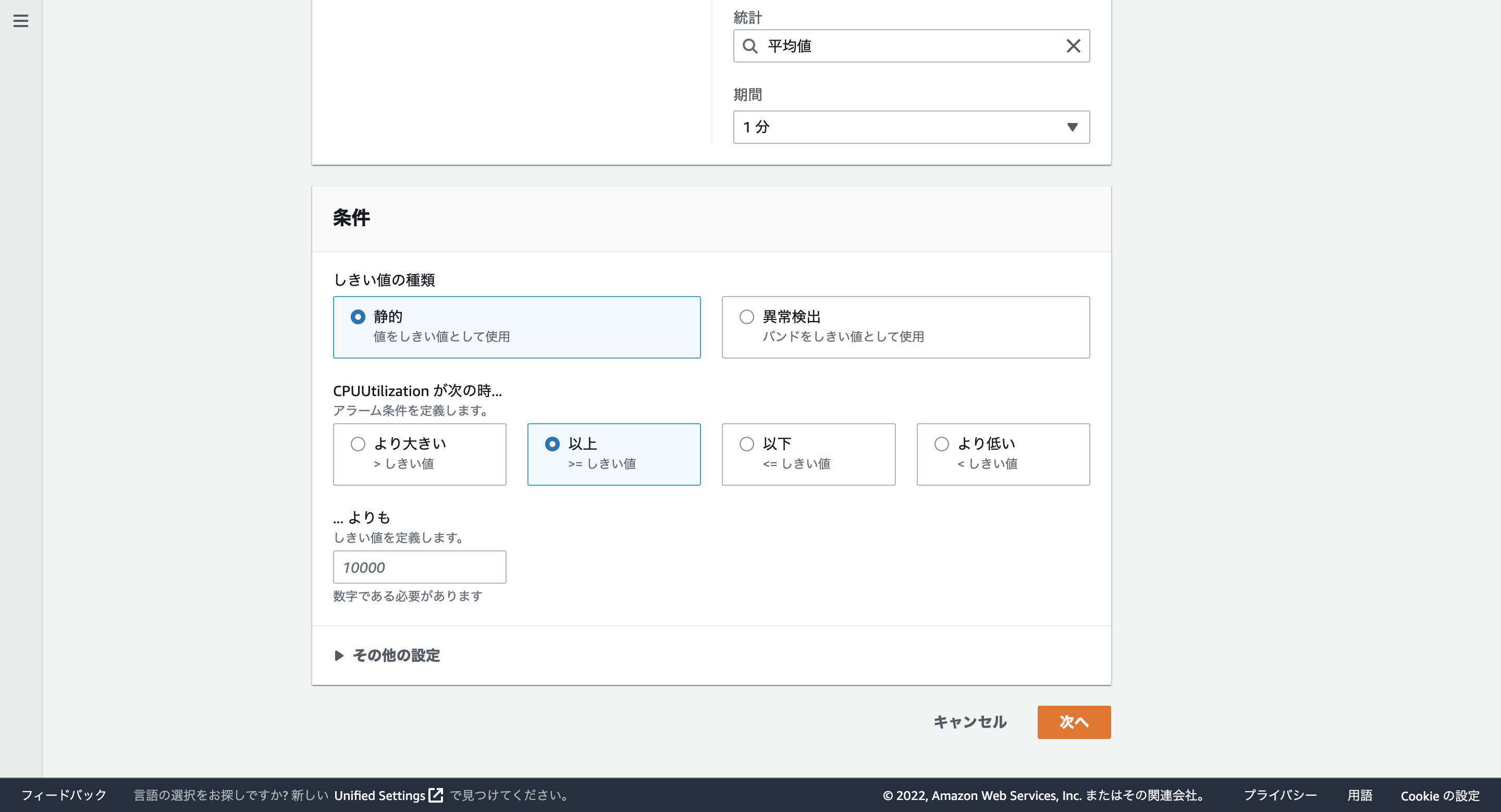 手順2:
手順2:
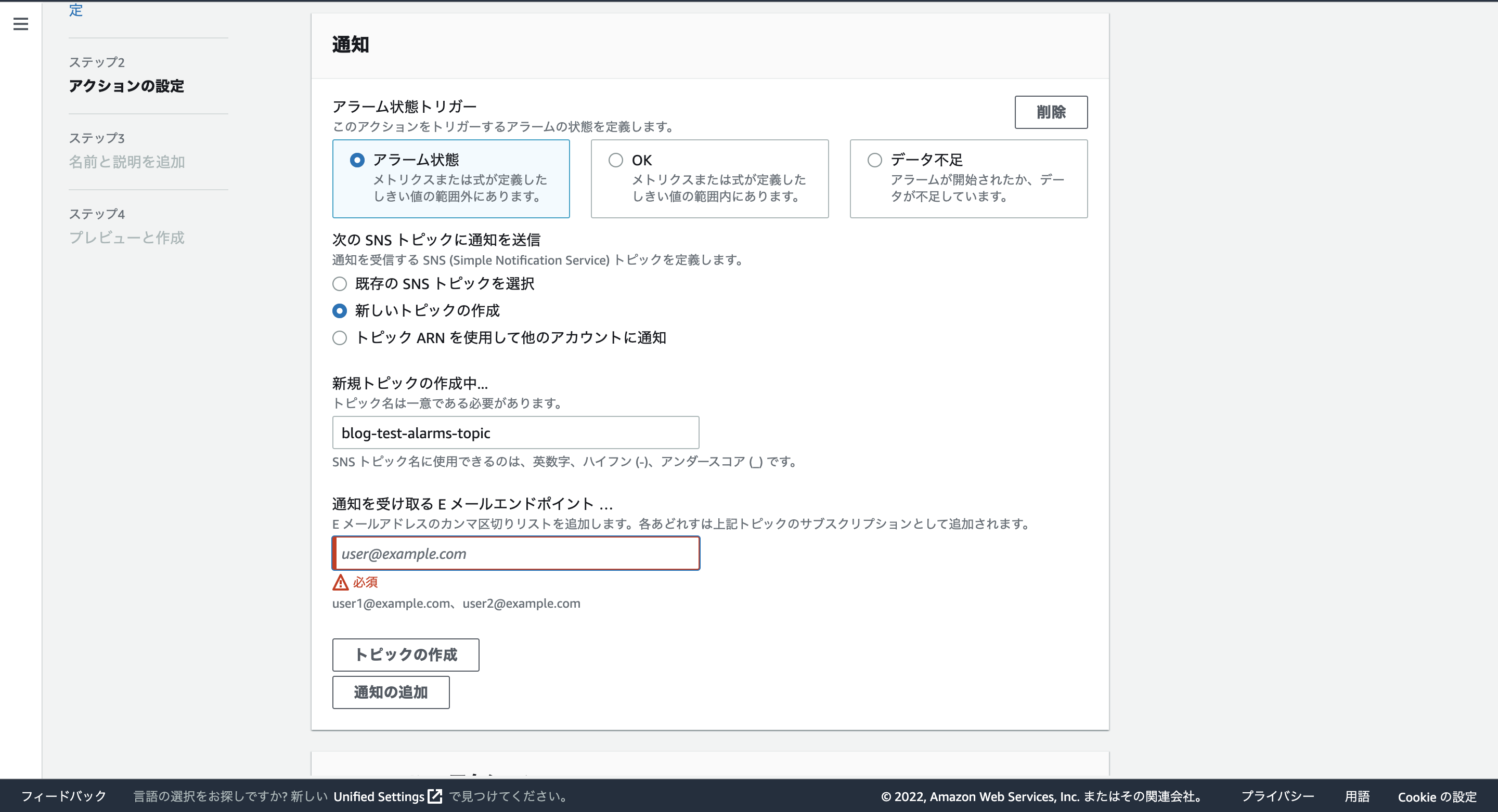
Amazon SNSのトピックを作成します。先ほどの設定画面の通知の部分で、「新しいトピックの作成」をクリックします。一意なトピック名もつけます。blog-test-alarms-topicにしました。通知を受け取るEメールには自分のEメールアドレスを入力します。その後、「トピックの作成」をクリックして、「次へ」をクリックします。
次にアラームに名前をつけます。今回はblog-test-cpuという名前にしました。アラームの説明にも同じものを入力します。その後、次へを入力します。 大丈夫そうなら「アラームの作成」をクリックします。作成後は認証メールが届いているので確認して認証を完了させます。
CloudWatchのアラートを確認する
作業手順
手順1:
以下のコマンドをEC2インスタンス上で実行して、CloudWatchのアラートを発行します。yesコマンドはターミナル上で永遠に標準出力でyを出し続けるコマンドです。>はyesコマンドで出力された結果を右の場所に出力します。/dev/nullは画面に表示されない場所です。&はバックグラウンドで実行するという意味です。バックグラウンドで実行することで、このコマンドを複数回実行でき、CPU使用率をすぐに高めることができます。実行後5分 ~ 10分でアラートが来ます。
yes > /dev/null &
topコマンドでCPU使用率を確認できます。上の5個それぞれでCPU使用率が18%以上行っています。

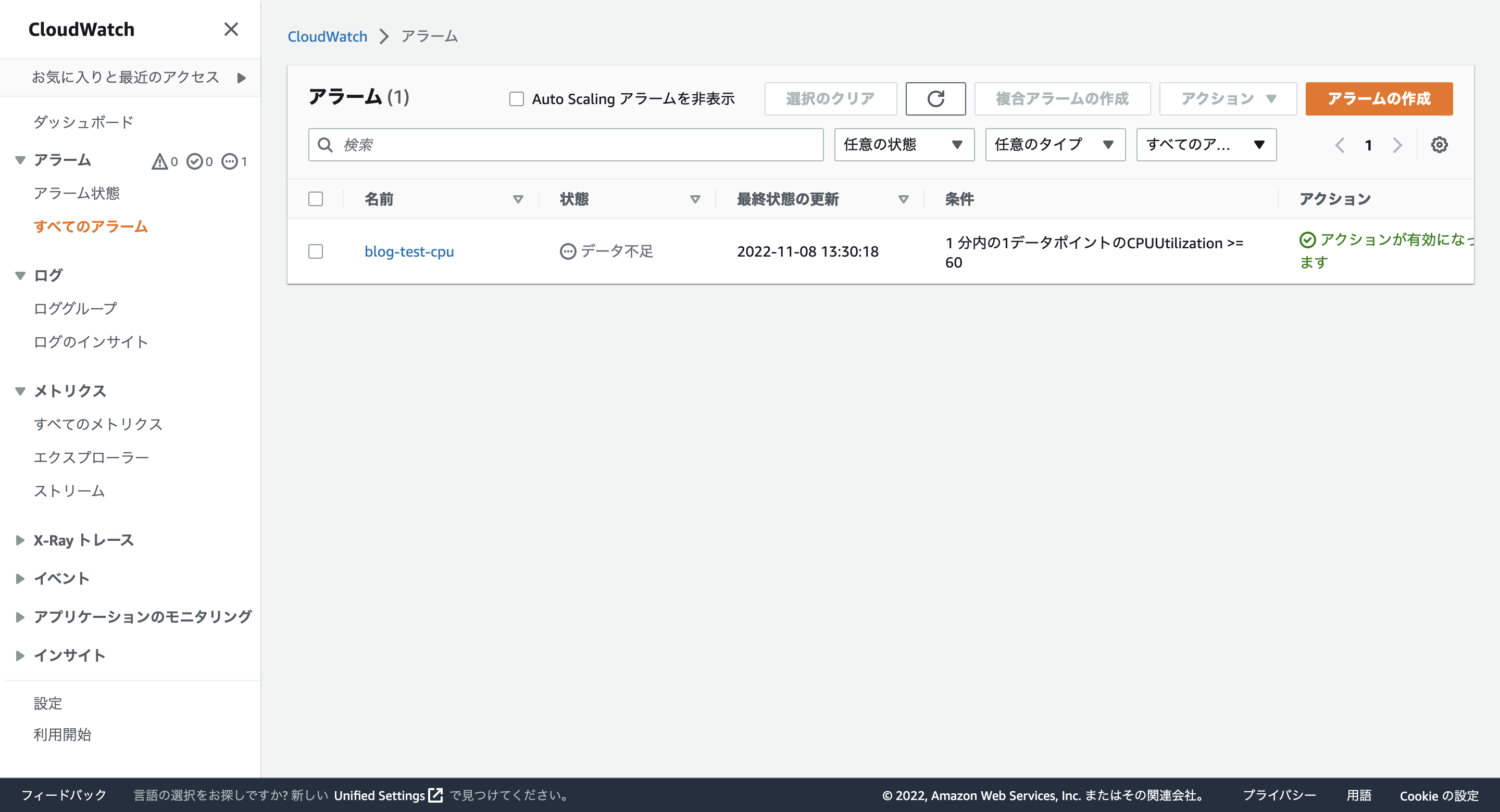
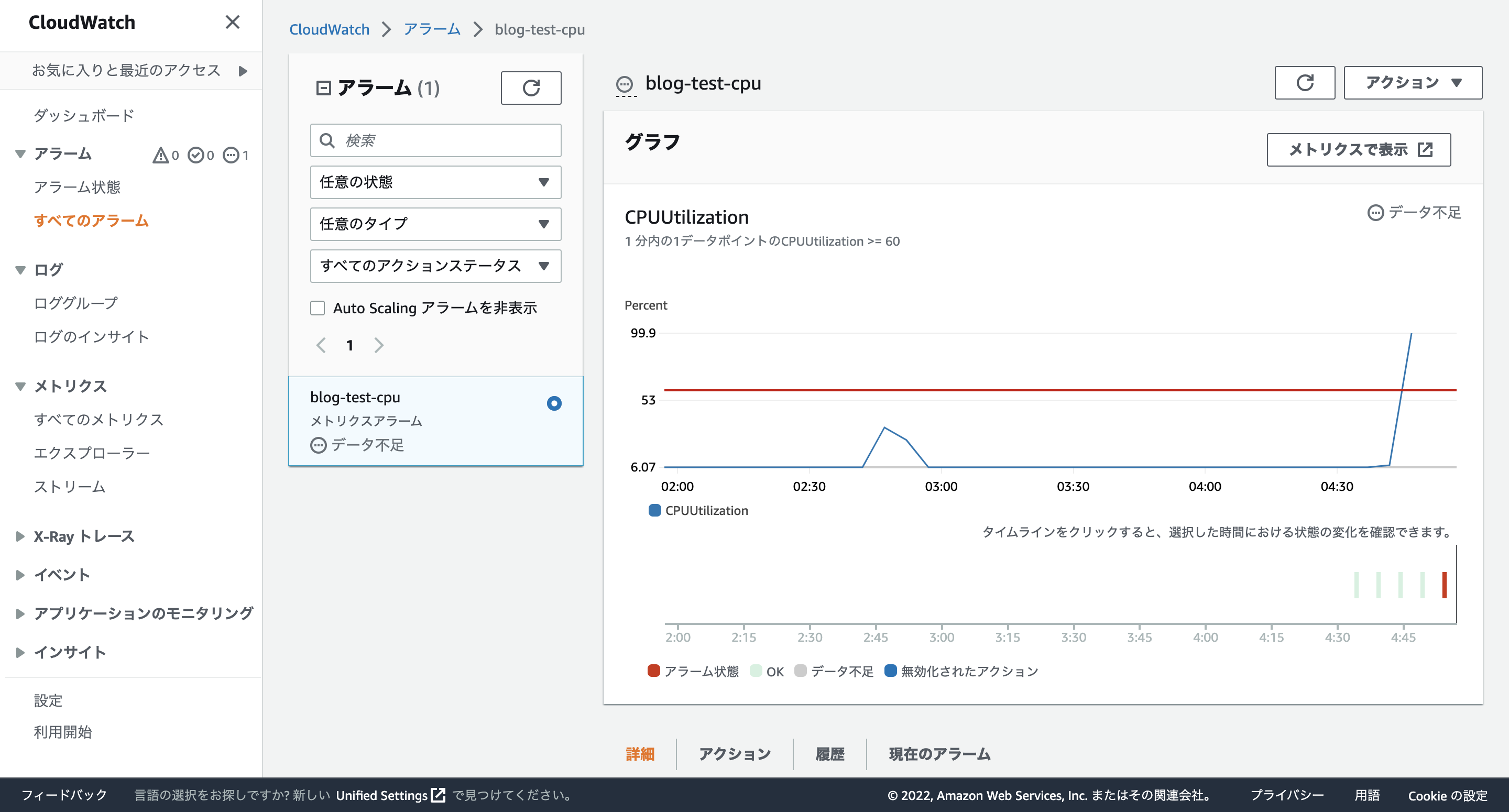
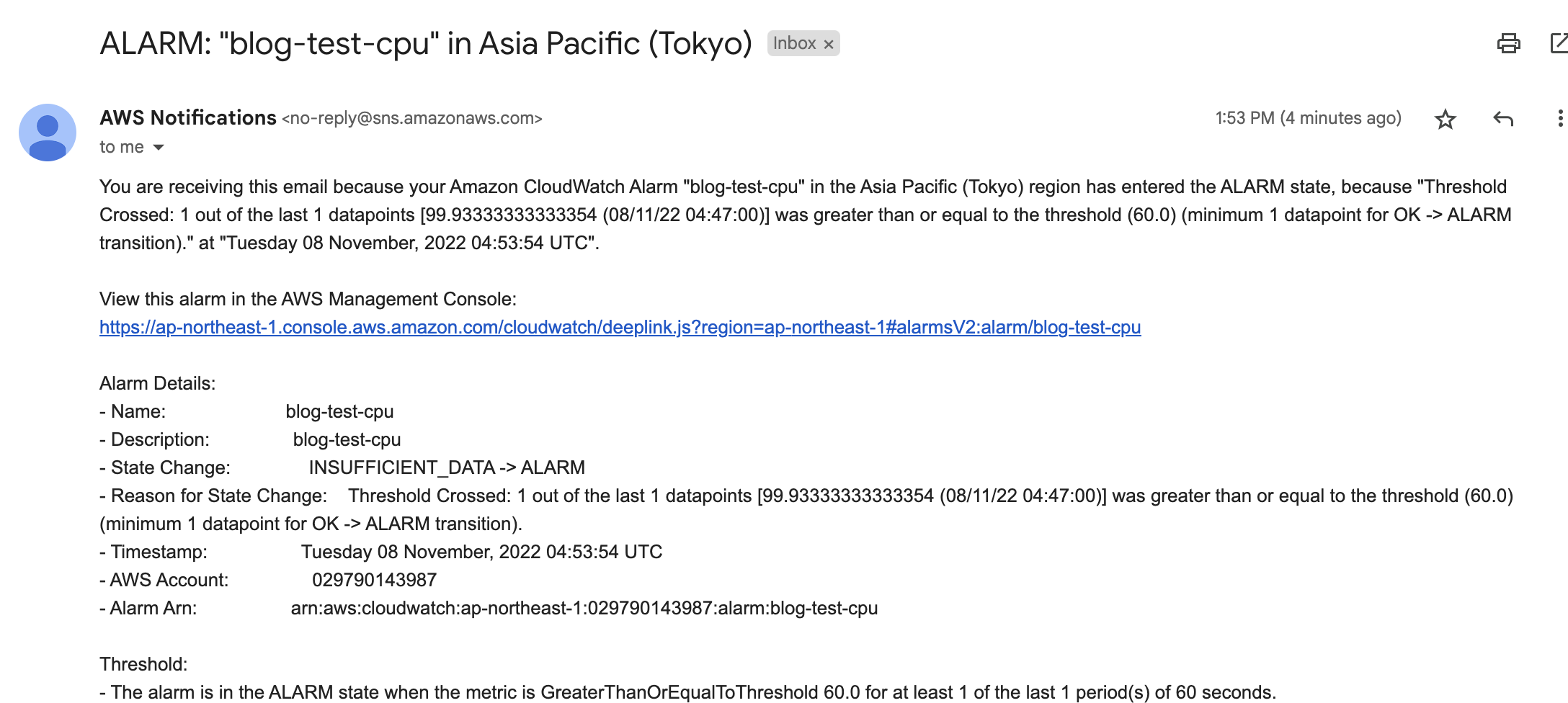
CloudWatchの画面で閾値を超えていることと、メールが届いているのも確認できました。
↓ CloudWatchの画面
↓ アラームのメール
手順2:
アラームが機能することを確認できたので、yesコマンドを解除します。以下のコマンドで解除します。
ps aux | grep yes
kill -9 プロセスのID
プロセスを消したので、しばらくするとCloudWatchのアラートも解除されます。
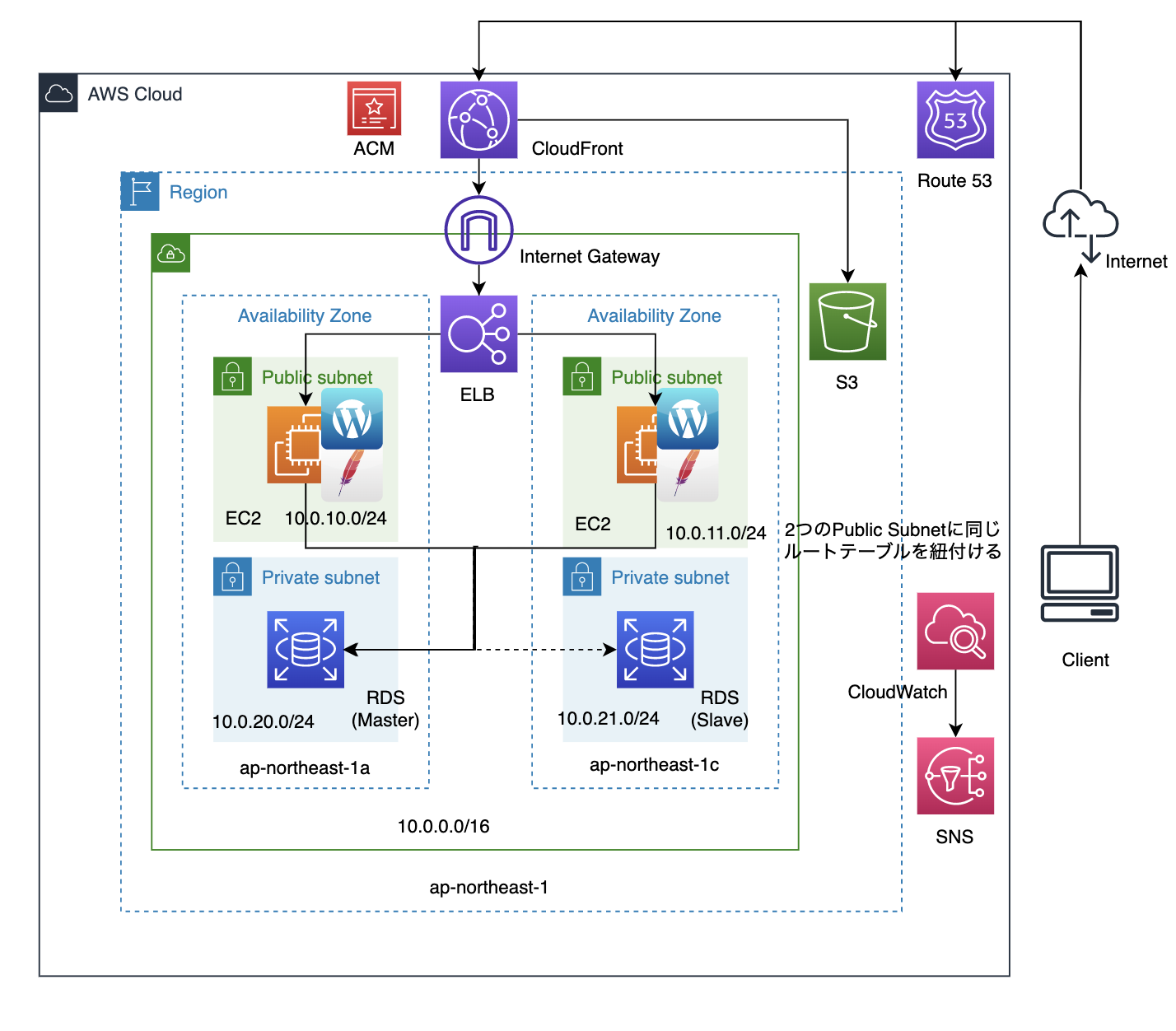
インフラ構成図
以前のインフラ構成図にCloudWatchとSNSを追加しました。
参考記事
AWS:ゼロから実践するAmazon Web Services。手を動かしながらインフラの基礎を習得 | Udemy