【Rails】前方一致検索機能を実装してみた
目次
背景
仕事でユーザーが入力した文字列から検索候補を表示する機能を実装して、その際に前方一致検索のAPIを実装したので、忘れないように記事にします。
どうやって前方一致検索を実装するのか
whereメソッド、LIKE句、プレースホルダー、ワイルドカードの4つを使用して実装します。
whereメソッドの2つの引数の指定方法について
whereメソッドの引数の指定方法は2つあります。
1. シンボル指定
User.where(name: "yuki")
2. 文字列指定
User.where("name = 'yuki'")
文字列指定ではプレースホルダーを使用できます。?(プレースホルダー)が第二引数で指定した値に置き換えられます。
# ?の部分はプレースホルダーと呼ばれる。 User.where("name = ?", "yuki") # 上のコードは下記のコードと同じ モデル名.where("name = 'yuki'") モデル名.where(name: "yuki")
ワイルドカードについて
ワイルドカードとは、任意の文字列を指定するときに使う「%」や「_」などの特殊文字のことです。SQLのLIKE句で主に使用します。
| ワイルドカード | 意味 |
|---|---|
| % | 0文字以上の任意の文字列 |
| _ | 任意の1文字 |
具体的な実装
LIKE句を使用することで、あいまいな文字列を検索できます。以下ではwhereメソッドに文字列で引数を指定しています。 第二引数には「ユーザーが入力した名前 + 0文字以上の任意の文字列」を指定しているので、?が置き換えられます。%は0文字以上の任意の文字列なので、結果的に、名前で前方一致検索ができます。前方一致検索があることで、ユーザーが名前を全部入力しなくても名前を検索でき、ユーザー体験が向上します。
# モデルクラス.where("カラム名 LIKE ?", "検索したい文字列")であいまいな文字列で検索できる def serach users = params[:name].present? ? User.where("name LIKE ?", "#{params[:name]}%") : [] render json: Response::Success.new(data: { users: }), status: :ok end
(注) 名前だけ返すと、そのユーザーの情報を再度取得する必要があり、使いにくいAPIになってしまいます。そのため、返してはいけないデータだけシリアライズして除き、基本的にはユーザー情報全部を返します。
参考記事
【Rails】ハッシュを要素とする配列をストロングパラメータで受け取る方法をざっくりまとめてみた
目次
概要
業務でハッシュを要素とする配列をストロングパラメータで受け取るのを実装したので、忘れないように実装方法を振り返ってみようと思います。
実装
フロント側から渡す値
以下のような値をフロント側から渡します。
params = {
products: [
{
date: '2022-11-25',
weight: 70,
},
{
date: '2022-11-25',
weight: 60,
},
]
}
ストロングパラメータ
def create_params params.permit( products: [ :date, :weight, ], ).to_h[:products] end
実行結果
[{"date"=>"2022-11-25", "weight"=>70},
{"date"=>"2022-11-25", "weight"=>60}]
最後に to_h[:products] を呼び出すことで、ActionController::Parametersのインスタンスを、ハッシュを要素とする配列に変換できます。あとはそれぞれのハッシュでインスタンスを作成してsave!を使うことで、各要素をDBに保存することができます。
感想
permit内でのキーの指定方法が独特なので、また使う場面が出てきたら、この記事を見ようと思います。
参考記事
【Rails】【臨時更新】Railsのバリデーションでよく使うヘルパーをざっくりまとめてみた
目次
概要
Railsのバリデーションでよく使うヘルパーをざっくりまとめました。 まだ働いて1年も経っていないので、仕事を通して重要だなと感じたやつは随時追加していきます。
バリデーションでよく使うヘルパー
バリデーションって言葉はvalid(有効な)が由来なので、「有効か?、有効ではないか?」を検証しているんだと思っていただけると理解しやすいです。
presence
このヘルパーは、指定した属性が空でないことを検証します。属性が空であることが許されない場合に、使用します。
class Event < ApplicationRecord include Hashid::Rails belongs_to :user validates :reserve_date, presence: true end
numericality
このヘルパーは、属性が数値のみを持つかどうかを検証します。整数値のみを許可するように指定するには、:only_integer を true に設定します。
class Event < ApplicationRecord include Hashid::Rails belongs_to :user # validates :price, numericality: trueと書くと、少数も通してしまう validates :price, numericality: { only_integer: true } end
only_integer以外にも、許容値に制約を加えるため様々なオプションが存在します。主に重さや値段など0より小さいことが許されない場合や、属性の値をある数値と比較して検証したい場合に、numericalityヘルパーを使用します。
class Event < ApplicationRecord include Hashid::Rails belongs_to :user validates :price, numericality: { greater_than_or_equal_to: 0 } # 0より大きい値のみ許容する場合は、greater_thanを使用する validates :price, numericality: { greater_than: 0 } # numericalityには複数のオプションを指定できる validates :contents_quantity, numericality: { only_integer: true, greater_than_or_equal_to: 1 }, allow_nil: true end
length
このヘルパーは、属性の値の長さを検証します。何文字以上何文字以下を検証したい場合、inオプションを指定します。
class User < ApplicationRecord validates :name, length: { minimum: 2 } # inオプションは、属性の長さは、与えられた間隔に含まれなければならないことを検証します # 以下の場合、6文字以上20文字以下ならOK validates :password, length: { in: 6..20 } # isオプションは、属性の長さは、与えられた値と等しくなければならないことを検証します # 以下の場合、6文字であればOK validates :registration_number, length: { is: 6 } end
(注) あくまでlengthオプションは、文字列の長さを検証するだけなので、数値の大小などは検証できません。数値の大小を検証したい場合、numericalityヘルパーを使用します。
comparison(Rails7)
Rails7からcomparisonヘルパーが追加されました。このヘルパーのおかげで、日付の検証で独自の検証メソッドを定義しなくても、検証できるようになりました。
このヘルパーは、比較可能な任意の2つの値の比較を検証します。主に日付の比較をしたい時に使用します。過去の日付で予約日を入力できないようにしたり、未来の日付で記録した日を入力できないようにしたい場合に使用します。
class Event < ApplicationRecord include Hashid::Rails belongs_to :user validates :date, comparison: { less_than_or_equal_to: proc { Date.today } } validates :reserve_date, comparison: { greater_than_or_equal_to: proc { Date.today } }, allow_nil: true end
(注) procを書かないと挙動がおかしい時があるので、必ず書きましょう。
uniqueness
このヘルパーは、オブジェクトが保存される直前に属性の値が一意であることを検証します。DBの一意制約とは違うので、DB側にも一意制約を設定しておきましょう。メールなど、一意であってほしい値を検証するときにuniquenessヘルパーを使用します。
class User < ApplicationRecord validates :email, uniqueness: true end
独自の検証メソッドを使ったバリデーション
validatesメソッドに用意されているヘルパーでは有効性を検証できない場合に使用します。事前に検証用のプライベートメソッドを定義しておいて、validateメソッドにそのプライベートメソッドを指定します。valid? メソッドは、errors コレクションが空であることを確認します。したがって、プライベートメソッド内で検証が失敗した場合、errors.addを実行する必要があります。モデルに定義すべきでないメソッドをモデル内に定義することは、ファットモデルの原因になるので、ヘルパーで対処できる場合は、そちらを優先的に利用しましょう。
class Event < ApplicationRecord include Hashid::Rails belongs_to :user validate :discount_cannot_be_greater_than_total_price # 省略 private def discount_cannot_be_greater_than_total_price if discount > total_price errors.add(:discount, "can't be greater than total value") end end end
参考記事
Active Record Validations — Ruby on Rails Guides
【さわって学ぶクラウドインフラ docker 基礎からのコンテナ構築】第7章 複数コンテナをまとめて起動するDocker Composeで知らなかったことをざっくりまとめてみた
目次
- 目次
- 概要
- ブログシステムをDocker Composeなしで構築する
- Docker Composeの仕組み
- Docker Composeの4つのメリット
- Docker Composeのインストール
- Docker Composeで複数のコンテナを一気に起動させてみる
- コンテナの停止と破棄
- YAML形式の書き方
- docker-compose.ymlの書き方
- docker-composeコマンドとdockerコマンドで実行する場合の3つの違い
- 参考記事
概要
実際のシステムでは、複数のコンテナを組み合わせる事が多いです(Webサーバーのコンテナ + DBサーバーのコンテナ等)。コンテナを組み合わせる時、コンテナをまとめて起動したり停止したりできると便利です。その仕組みがDocker Composeです。今回はDocker Composeを使用して、複数のコンテナをひとまとめにして操作する方法を学びます。
ブログシステムをDocker Composeなしで構築する
大まかな流れ
- Dockerネットワークを作成する
コンテナ同士を繋ぐのに規定のbridgeネットワークを使ってもできますが、何のネットワークを使っているか分かりにくいので、新しくDockerネットワークを作成します。 - ブログのデータを保存するためのボリュームを作る
MySQLコンテナのDBのデータ永続化に用いるためのボリュームを作成します。 - MySQLコンテナを作る
- WordPressコンテナを作る
Docker Composeを使わないでブログシステムを構築したときの問題点
Dockerネットワークを作って、--netオプションで指定すれば、複数のコンテナを組み合わせて使う事は容易です。しかし、コンテナの起動や停止、オプションの指定等をコンテナの数に比例して実行しなければならないです。また、ボリュームやDockerネットワークを使う場合、あらかじめ作成する必要があります。コンテナを使い終わって削除するときは、不要になったネットワークも削除する必要があります。
このような操作を手動でやるのはとてもめんどくさいです。 こうしたコンテナの作成や停止、破棄の一連の操作をまとめて実行する仕組みがDocker Composeです。
Docker Composeの仕組み
Docekr Composeでは、あらかじめコンテナの起動方法やボリューム、ネットワークの構成などを書いた定義ファイル(docker-compose.yml)を用意しておき、その定義ファイルを読み込ませることで、まとめて実行します。
(※) 定義ファイルは「Composeファイル」と呼ばれ、既定では「docker-compose.yml」というファイル名です。
(注) Docker Composeを使う場合、定義ファイルやコピーしたいファイルなどは、一つの作業用ディレクトリにまとめておきます。
Docker Composeの4つのメリット
長い引数からの解放
docker run(もしくはdocker create)の際、長い引数を指定する必要がなくなります。複数コンテナの連動
複数のコンテナをまとめて起動できます。起動順序の指定もできます。まとめて指定・破棄
定義したコンテナをまとめて停止したり、破棄したりできます。コンテナの起動時の初期化やファイルコピー
コンテナ起動後にコマンドを実行したりファイルをコピーしたりする初期化などの操作を行えます。
Docker Composeのインストール
Docker Composeは、Docker操作の補佐をするPython製のツールです。Docker Engineの一部ではないです。 そのため、Docker Engineとは別にインストールする必要があります。 いくつかの方法がありますが、今回はpipコマンドでインストールします。ptyhonをインストールした後に、Docker Composeをインストールします。
sudo apt install -y python3 python3-pip
sudo pip3 install docker-compose
インストールできたら、docker-compose --versionで確認します。
ubuntu@ip-10-0-12-65:~$ docker-compose --version docker-compose version 1.29.2, build unknown
Docker Composeで複数のコンテナを一気に起動させてみる
WordPressコンテナとMySQLコンテナを起動するという行程を、Docker Composeで実現します。Docker Composeを使うには何か作業用のディレクトリを作り、そこにdocker-compose.ymlファイルを配置します。
docker-compose.ymlは「YAML形式」と呼ばれる形式のファイルです。YAML形式では、空白によるインデント(字下げ)で構造ブロックを表現します。インデントが間違っていると、正しく動作しません。インデントは「空白2つ」 or 「空白4つ」が一般的です。
↓ docker-compose.yml
version: "3" services: wordpress-db: image: mysql:5.7 networks: - wordpressnet volumes: - wordpress_db_volume:/var/lib/mysql restart: always environment: MYSQL_ROOT_PASSWORD: myrootpassword MYSQL_DATABASE: wordpressdb MYSQL_USER: wordpressuser MYSQL_PASSWORD: wordpresspass wordpress-app: depends_on: - wordpress-db image: wordpress networks: - wordpressnet ports: - 8080:80 restart: always environment: WORDPRESS_DB_HOST: wordpress-db WORDPRESS_DB_NAME: wordpressdb WORDPRESS_DB_USER: wordpressuser WORDPRESS_DB_PASSWORD: wordpresspass networks: wordpressnet: volumes: wordpress_db_volume:
その後、 docker-compose.ymlを置いたディレクトリをカレントディレクトリとして、docker-composeのupコマンドを実行してコンテナを起動させます。 ちなみにdocker-composeコマンドは次の書式で実行します。
docker-compose コマンド オプション 引数
docker-compose up -d
コンテナの命名規則
docker-composeで立ち上げたコンテナの名前は、以下のような命名規則になっています。 dockerコマンドでdocker-composeで立ち上げたコンテナを操作する場合、この長い名前を指定する必要があります。docker-composeコマンドでdocker-composeで立ち上げたコンテナを操作する場合、サービス名で指定することができます。そのため、docker-composeで立ち上げたコンテナは、docker-composeコマンドで操作しましょう。
作業用ディレクトリ名_コンテナ名_1
ubuntu@ip-10-0-12-65:~/wordpress$ docker ps CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES bc7c7782c476 wordpress "docker-entrypoint.s…" 3 minutes ago Up 3 minutes 0.0.0.0:8080->80/tcp, :::8080->80/tcp wordpress_wordpress-app_1 bc29fd390a0c mysql:5.7 "docker-entrypoint.s…" 3 minutes ago Up 3 minutes 3306/tcp, 33060/tcp wordpress_wordpress-db_1
(※) 1というのは「1つ目」ということを意味します。docker composeでscaleオプションを指定すると、docker-composeファイルに記述している同じコンテナを2つ、3つと複数起動できます。その場合、「_2」「_3 」といった命名規則になります。
↓ 代表的なdocker-composeのコマンドとdockerコマンドとの対応
| docker-composeのコマンド | 対応するdockerコマンド | 説明 |
|---|---|---|
| docker-compose exec | docker exec | コンテナ内でコマンドを実行する。docker execでは「-it」オプションをつけていましたが、docker-compose execには不要です。つけなくてもキーボードがコンテナとつながります。 |
docker-composeで管理する
docker-composeで作成したコンテナは普通のコンテナと一緒です。ネットワークやボリュームについても同様です。これらのコンテナをdocker stopしたり、docker rmすることもできます。ネットワークやボリュームも同様です。しかし、そうすると、docker-composeツールから操作した状態と反故(ほご)が生じて、管理しにくくなります。 そのため、docker-composeで作成したコンテナは、docker-composeを使った管理に一元化しましょう。
コンテナの停止と破棄
docker-composeで起動したコンテナを停止・破棄するためには、docker-compose downコマンドを使います。コンテナやネットワークを停止するだけではなく、それらを破棄します。つまりdocker-copose upする前に戻します。しかし、ボリュームに関しては、削除されたらデータが永続化されないので、docker-compose downを実行しても削除されないです。
docker-compose down
ubuntu@ip-10-0-12-65:~/wordpress$ docker-compose down Stopping wordpress_wordpress-app_1 ... done Stopping wordpress_wordpress-db_1 ... done Removing wordpress_wordpress-app_1 ... done Removing wordpress_wordpress-db_1 ... done Removing network wordpress_wordpressnet ubuntu@ip-10-0-12-65:~/wordpress$ docker-compose ps Name Command State Ports ------------------------------ ubuntu@ip-10-0-12-65:~/wordpress$ docker network ls NETWORK ID NAME DRIVER SCOPE 49ea1ad2bf81 bridge bridge local d8850b15265b host host local a8e3cb52fef7 none null local ubuntu@ip-10-0-12-65:~/wordpress$ docker volume ls DRIVER VOLUME NAME local 258ed8c33ff297aa10a214fd7d090579f94709ac887b01c56acfb2ec78f53337 local 8316dad9e908e23bdba6a139317e6cee834656a46e169414e9c3f25fcd2a3aec local wordpress_wordpress_db_volume ubuntu@ip-10-0-12-65:~/wordpress$
(注) 起動時(docker-compose up)と破棄時(docker-compose down)で、docker-compose.ymlファイルが異なる場合、注意が必要です。docker-compose downは、実行時にカレントディレクトリに置かれているdocker-compose.ymlファイルを見て操作します。そのため、起動時の状態を把握しているわけではありません。docker-compose upをした後にdocker-compose.ymlを書き換えて、docker-compose downをしたときにコンテナやネットワークの削除残しや、意図しない削除が発生しないように注意しましょう。
YAML形式の書き方
設定値の書き方
設定値は「設定項目: 設定値」のように「:」で区切って記述します。改行は入れても入れなくても同じです。文字列を指定する場合は、「"」 または「'」で囲みます。半角スペースに関しては、おそらく入れても入れなくてもどっちでもいいと思われます。
version: "3"
image: mysql:5.7
上の表記は以下のように書くこともできます。
version:
"3"
image:
mysql:5.7
複数値の書き方
一つの設定項目に複数の値を設定したい場合、「- 設定値」のように、「-」で区切って記述します。 複数値を設定しなくても、「- 設定値」のような書き方をすることもできます。その場合は、今後、複数の値を設定する可能性があると考えられます。
ports: - 8080:80
volumes: - ./frontend:/var/app:cached - node-data:/var/app/node_modules:delegated
ハッシュのネスト
半角スペースでインデントすることで、ハッシュをネストさせることができます。
environment:
MYSQL_ROOT_PASSWORD: myrootpassword
MYSQL_DATABASE: wordpressdb
MYSQL_USER: wordpressuser
MYSQL_PASSWORD: wordpresspass
コメント
「#」を記述すると、それ以降から行末までがコメントとみなされ、無視されます。
docker-compose.ymlの書き方
docker-compose.ymlでは、「サービス」「ネットワーク」「ボリューム」の3つを定義します。
サービス
全体を構成する1つひとつのコンテナのことです。 Docker Composeにおいてサービスとは、ざっくり言うとコンテナのことです。ネットワーク
サービス(つまりコンテナ)が参加するネットワークを定義します。ボリューム
サービス(つまりコンテナ)が利用するボリュームを定義します。
docker-compose.ymlでは、これらの設定をインデントしたブロック単位で記述します。
(※) 厳密に言うと、scaleオプションを指定すると、1つのサービスに対して複数のコンテナを起動することができます。つまり、本当はサービスに対してコンテナが1対多の関係です。
バージョン番号
docker-compose.ymlの冒頭の「version」では、書式のバージョン番号を記述しています。 Docker Composeは、過去、何度かバージョンアップをしており、バージョンによってdocker-compose.ymlの書き方が少し違うので、どのバージョンなのかを指定するために「version」という項目が存在します。
version: "3"
version: "3.8"
サービス
「services」の部分では、サービス(すなわち、コンテナの定義)を記述します。
services:
サービスAの名前:
サービスAの設定
...
サービスBの名前:
サービスBの設定
代表的なサービスの設定項目を以下にまとめます。
| 項目 | docker runの対応オプション | 意味 |
|---|---|---|
| env_file | なし | 環境設定情報を書いたファイルを読み込む |
| environment | -e | 環境変数を設定する |
| ports | -p | ポートのマッピングを設定する |
| volumes | -v, --mount | バインドマウントやボリュームマウントなどを設定する |
| depends_on | なし | 別のサービスに依存することを示す。docker-compose upするときやdocker-compose downするときに、指定したサービスが先に起動(もしくは終了)するようになる |
| image | イメージ引数 | 利用するイメージを指定する。このイメージをもとにコンテナを作成する |
| networks | -net | 接続するネットワークを指定する。ネットワークはdocker-compose.ymlのnetworksのところで定義していなければならない。この設定配下に「ipv4_address」「ipV6_address」を記述すると、固定IPを割り当てることもできる。 |
| restart | なし | docker compose upなどで起動する際、コンテナが停止した時の再試行ポリシーを設定する。no, always, on-failure, unless-stoppedなどがある。alwaysは終了ステータスに関わらず、いつも再起動する(明示的にdocker-compose stopで止めた場合は除く) |
ネットワーク
ネットワークは、networksの部分で定義します。Dockerネットワークの名前だけを指定していますが、オプションでIPアドレス範囲なども指定できます。
networks: Dockerネットワーク名:
(注) 実はネットワークの設定を省略することができます。Docker-Composeでは明示的にネットワークを指定しなかったときは、記述しているサービス(コンテナ)がつながる新しいDockerネットワークを自動的に作成し、全てのサービスを、そのネットワークに接続するように構成します(docker-compose downすれば、そのネットワークは、もちろん、自動的に削除されます)。この場合でも、サービス名を宛先として指定して通信できます。そのため、明示的にネットワークを設定しなければならない必然性はなく、むしろ指定が省略されることの方が多いです。
↓ ネットワークを省略した場合のdocker-compose.yml
version: "3" services: wordpress-db: image: mysql:5.7 volumes: - wordpress_db_volume:/var/lib/mysql restart: always environment: MYSQL_ROOT_PASSWORD: myrootpassword MYSQL_DATABASE: wordpressdb MYSQL_USER: wordpressuser MYSQL_PASSWORD: wordpresspass wordpress-app: depends_on: - wordpress-db image: wordpress ports: - 8080:80 restart: always environment: WORDPRESS_DB_HOST: wordpress-db WORDPRESS_DB_NAME: wordpressdb WORDPRESS_DB_USER: wordpressuser WORDPRESS_DB_PASSWORD: wordpresspass volumes: wordpress_db_volume:
ボリューム
コンテナが利用するボリュームは、volumesの部分で定義します。名前だけを指定するでもOKですが、オプションでマウント方法などを指定することもできます。 既定では、ボリュームが存在しない場合は作られ、作られたボリュームはdocker-compose downしても、削除されません(そうでないと、ボリュームに永続して保存したいデータを残せません)。
volumes: wordpress_db_volume:
docker-composeコマンドとdockerコマンドで実行する場合の3つの違い
docker-compose.ymlが必要
docker-composeコマンドは、カレントディレクトリに置かれたdocker-compse.ymlを読み込みます。このファイルがなければ失敗します。サービス名で指定する
dockerコマンドはコンテナ名またはコンテナIDで指定するのに対し、docker-composeではdocker-compose.ymlのservicesの部分に書かれたサービス名を指定します。依存関係が考慮される
docker-composeでは、depends-onで記述された依存関係が考慮されます。例えば、wordpress-appはwordpress-dbに依存しているため、「docker-compose start wordpress-app」としたときは、wordpress-dbが先に起動します。同様に、「docker-compose stop wordpress-app」としたときは、wordpress-appが終了した後、wordpress-dbも終了します。
docker-composeコマンドで立ち上げたコンテナは、docker-composeコマンドで操作した方がコンテナ名の指定が楽だったり、依存関係が考慮されるので、docker-composeコマンドで立ち上げたコンテナは、docker-composeコマンドで操作した方が良いです。
参考記事
さわって学ぶクラウドインフラ docker基礎からのコンテナ構築 | 大澤 文孝, 浅居 尚 |本 | 通販 | Amazon
【2022/11/21 ~ 2022/11/25】コードレビューで知ったことをざっくりまとめてみた
目次
- 目次
- この記事を書く背景
- Open API
- Rails
- フロントエンドとバックエンドが別のアプリの場合、どちらにもバリデーションをかける
- シリアライザー内で外部キーのハッシュIDを生成する際、encode_idメソッドを使用する
- エラーハンドリングは大元のApplicationControllerに書く
- Rubyは型のある言語ではないので、可能な限りYARDによるドキュメントの記載をする
- eachメソッド内でクエリメソッドを実行して同じものを取得しない
- 適切な場所に書かないことが、ファットコントローラやファットモデルの原因になる。再利用しないメソッドを定義するとこれらを引き起こす可能性があるので、それなら愚直に書く
- 一連の処理のどこかで例外が発生する可能性がある場合、それらの処理をトランザクションとして定義する
- error400というメソッドの命名がメソッド内の処理を表していない場合、別の命名を考える
- 201 createdのレスポンスボディには、基本的に新しく生成したリソースを入れる
- 可能な限り括弧を省略するのは避ける
- メソッドチェーンでむやみにインデントを増やさない
- 日付の比較をするだけのバリデーションなら、ラムダを使うか、Rails7ならComparisonValidatorを使う
- バリデーションのエラーメッセージはe.messageで取得できる
- テスト(Rspec)
- 感想
- 参考記事
この記事を書く背景
前職を退職したときに、コードレビューされた内容を思い出せなくて、もったいないなと感じました。今回はそのようなことをしないように、コードレビューを受けて印象に残ったことを書いていこうと思います。復習の意味も込めてます。指摘事項に関しては、ジャンルごとに分けて書いていこうと思います。
Open API
Open APIでエンドポイントを定義する場合、タグを付与する
タグは、各エンドポイントをタグで分類する際に必要です。タグの付与は必須だそうです。あまりよくわかっていませんが、タグを付与しないと、yamlファイルで定義したAPIにリクエストを出せないそうです。あまりよくわかっていないので、次使うときに調べます。
(※) タグは単数系かつキャメルケースで書きます。しかし、職場によってルールが違うかもしれません。
一対多のエンドポイントにはidを加える
一対多のエンドポイントにはidを加えます
↓ 例
/events/{id}/logs
対象のスキーマが一つしかない場合、allofは不要
そもそもallofは、モデル定義を組み合わせたり拡張(プロパティの上書きや追加)して1つのスキーマを作成したい場合に使用します。対象のスキーマが一つしかない場合、allofは使わなくて大丈夫です。
(※) スキーマとは、ざっくり言うとひとまとまりのデータ定義のことです。OpenAPIの文脈では、レスポンスの返却内容の定義を指すこともあります。
operationIdがそのまま自動生成されるAPIコード上でのメソッド名になるので、使いにくいメソッド名になっていたら変更する
特にoperationIdに「id」文字列が入っていたら、削除します。
OpenAPIでdate型を使う場合、format: dateを指定する
Stoplight上でformat: dateとexampleを定義します。
date: type: string format: date example: '2022-01-01'
nullを許容する場合、nullable: trueを追加する
OpenAPI3.1より前の場合、nullが型としてサポートされていないです。そのため、nullを型として使いたい場合、nullable: trueを追加します。 Stoplight上ではnullable: trueを追加できないので、yamlファイルを直に編集して追加します。jsonファイルが必要な場合は、編集後のyamlファイルからエクスポートします。
reserve_date:
type: string
format: date
example: '2022-01-01'
nullable: true
Rails
フロントエンドとバックエンドが別のアプリの場合、どちらにもバリデーションをかける
フロントエンドとバックエンドが別のアプリの場合、どちらにもバリデーションをかけます。
シリアライザー内で外部キーのハッシュIDを生成する際、encode_idメソッドを使用する
hashid-rails gemはDBから取得した整数のidをハッシュ化するために使用します。外部キーなどのidをハッシュ化したい場合、その外部キーに対応するモデルに対して、encode_idメソッドを実行します。
class EventSerializer < ApplicationSerializer # JSONで出力したい属性をここに書く # reserve_dateはrender json: で返却するオブジェクトの属性を参照する # id、user_idの場合、メソッドを定義しているので、そちらが優勢して呼ばれる attribute :id attribute :reserve_date attribute :user_id # 省略 def id object.hashid end def user_id User.encode_id(object.user_id) end end
(※) hashid-rails gemを導入しても、DB側ではidは整数として保持されます。その点がuuidとの違いです。ハッシュidはuuidより短いので、扱いやすいです。
(注) コントローラでrender json:を使用すると、返却するオブジェクトのシリアライザーをRailsが検索して、利用可能であればそれを利用します。そのため、render json:の部分にわざわざシリアライザーを指定しなくても大丈夫です。
(※) シリアライザー内にattributeで属性を定義することで、シリアライザーはrender jsonで指定したオブジェクトの属性を検索します。しかし、シリアライザーはオブジェクトの属性を検索する前に、その属性の名前を持つメソッドが存在しないかを確認します。これにより、値をメソッドで修正したり、オリジナルのプロパティを追加したりできます。上の例の場合、attribute :idでidメソッド、attribute :user_idでuser_idメソッドが先に呼ばれています。
エラーハンドリングは大元のApplicationControllerに書く
rescue_fromで例外時に呼び出すメソッドを指定します。このrescue_fromと例外時に呼び出すメソッドは全てのコントローラが継承しているコントローラ(ApplicationController)に書きます。そうすることで、同じ例外処理を何度も書く必要がなくなります。
module API class ApplicationController < ActionController::API rescue_from ActiveRecord::RecordInvalid, with: :error_record_invalid # @param [ActiveRecord::RecordInvalid] e def error_record_invalid(e) # 省略 render json: #省略, status: :bad_request end end end
Rubyは型のある言語ではないので、可能な限りYARDによるドキュメントの記載をする
Rubyの場合、引数や戻り値がどんな型なのか不明なので、書いた方が親切です。以下の場合、YARDによるドキュメントを書くことで、引数の型が明確になります。また、エディタの補完機能でeと入力すると、関連するメソッドが表示されるようになります。基本的にはメソッドに対してドキュメントを書きます。
# @param [ActiveRecord::RecordInvalid] e def error_record_invalid(e) # 省略 render json: #省略, status: :bad_request end
(注) コードを見て明らかに分かる部分は、コメントとして書かなくても大丈夫です。
eachメソッド内でクエリメソッドを実行して同じものを取得しない
例えばユーザーが複数のイベントを登録する場合を考えます。イベントを登録するユーザーは常に同じなので、以下のような書き方をすると、ループごとにユーザーの取得をしてしまい、処理的にあまり良くないです。そのため、取得結果が常に同じ部分に関しては、ループ外で実行します。
↓ before
permitted.each do |event| event[:user_id] = User.find(params[:user_id]).id event[:place_id] = Place.find(event[:place_id]).id end
↓ after
user_id = User.find(params[:user_id]).id permitted.each do |event| event[:user_id] = user_id event[:place_id] = Place.find(event[:place_id]).id end
適切な場所に書かないことが、ファットコントローラやファットモデルの原因になる。再利用しないメソッドを定義するとこれらを引き起こす可能性があるので、それなら愚直に書く
save_allなどの独自メソッドをモデルに定義すると、コントローラはスッキリしますが、モデルを見に行かないとどんな処理をしているのか分かりません。また、それを繰り返すとモデルがファットになります。 そもそもメソッドを定義する目的は、処理を一つのメソッドとしてまとめて、処理を複数の場所で呼び出せるようにすることです。そのため、複数の場所でメソッドを呼び出す予定がない場合、独自メソッドを定義せず、愚直に書いた方が良いです。
複数のコントローラで独自メソッドを使用する場合、モデルに定義します。あるコントローラ内の複数のアクションで使用する場合、そのコントローラ内にプライベートメソッドとして定義します。
一連の処理のどこかで例外が発生する可能性がある場合、それらの処理をトランザクションとして定義する
トランザクションとは、 分割不可な一連の処理のことです。
一連の処理をトランザクションとして定義したい場合、それらの処理を
ApplicationRecord.transaction メソッドで囲みます。transactionブロック内で例外が発生した場合、transactionブロック内で行われたデータベース更新処理を全てロールバックすることができます。そのため、Railsでトランザクションを機能させるためには、transactionメソッド内で例外を発生させる必要があります。
def create permitted = create_params events = [] ApplicationRecord.transaction do permitted.each do |event_params| event = Event.new(event_params) event.save! events.push(event) end end render json: # 省略, status: :created end
(注) 上の例でtransactionメソッドを使用しない場合、例外が発生する以前にeachメソッド内で登録されたデータをロールバックすることができません。つまり、例外発生前にeachメソッド内で登録されたデータを登録しなかったことにすることができないので、中途半端にデータがDBに登録された状態になってしまいます。また、フロント側には例外処理した結果が返されるので、ユーザーがもう一度データを登録しようと再リクエストした場合、DBの整合性が保たれていなくて、データが保存できなくなる可能性があります。もしくは、同じデータが重複して登録される可能性があります。そのため、 複数のデータをまとめて登録する等の「分割不可な一連の処理」は、トランザクションとして定義した方が良いです。
error400というメソッドの命名がメソッド内の処理を表していない場合、別の命名を考える
error400 と言いつつ、RecordInvalid 専用の処理になっている場合、error_record_invalid のような処理内容をちゃんと表す命名に修正します。
module API class ApplicationController < ActionController::API rescue_from ActiveRecord::RecordInvalid, with: :error_record_invalid # @param [ActiveRecord::RecordInvalid] e def error_record_invalid(e) # 省略 render json: #省略, status: :bad_request end end end
201 createdのレスポンスボディには、基本的に新しく生成したリソースを入れる
201 createdのレスポンスボディには、基本的に新しく生成したリソースを入れます。
可能な限り括弧を省略するのは避ける
括弧を省略する/しないは、個人の感覚に依存するので、可能な限り括弧を省略するのは避けましょう。特に引数の入ったメソッドを呼び出す場合、括弧を省略しないようにします。
↓ before
end_date.after? start_date
↓ after
end_date.after?(start_date)
括弧を省略した方が明らかに良い場合、括弧を省略します。
- 引数のない関数呼び出し
empty? など - DSL拡張系の関数
belongs_to や validates など
メソッドチェーンでむやみにインデントを増やさない
メソッドチェーンの「.」を改行して揃えるのは良いですが、むやみにインデントを増やすと可読性が落ちるので、その場合は、増やさない方が良いです。
↓ before
permitted = params.permit(
events: [
# 省略
],
)
.to_h[:product_logs]
↓ after
permitted = params.permit(
events: [
# 省略
],
).to_h[:product_logs]
日付の比較をするだけのバリデーションなら、ラムダを使うか、Rails7ならComparisonValidatorを使う
日付の比較をするバリデーションを定義するために独自メソッドを定義することがありますが、日付の比較などの簡単な比較の場合、validationsメソッドが用意しているヘルパーを使用した方が良いです。簡単な要件のバリデーションを実装するのに、独自メソッドを定義するのはやりすぎです。Rails7の場合、ComparisonValidatorを使うとスッキリ書くことができます。以下の例では、「予約日が今日以降の日付ならOK。それ以外なら例外を発生させる」というバリデーションを定義しています。
↓ before
validate :reserve_date_cannot_be_in_the_past private def reserve_date_cannot_be_in_the_past if !reserve_date.present? errors.add(:reserve_date, message: "cannot be in the past") if reserve_date.before?(Date.today) end end
↓ after(予約日が今日以降の日付ならOK。それ以外なら例外を発生させる)
validates :reserve_date, comparison: { greater_than_or_equal_to: proc { Date.today } }, allow_nil: true
バリデーションのエラーメッセージはe.messageで取得できる
module API class ApplicationController < ActionController::API rescue_from ActiveRecord::RecordInvalid, with: :error_record_invalid # @param [ActiveRecord::RecordInvalid] e def error_record_invalid(e) # 省略 e.message # => Validation failed: Date must be less than or equal to 2022-11-25 render json: #省略, status: :bad_request end end end
テスト(Rspec)
リクエストスペックのリクエストボディにidを入れる場合、ハッシュIDを渡す
(注) hashid-railsを使用する前提で話しています。
なるべく実際にユーザーが使う状況と同じ状況を再現した方が良いので、リクエストスペックのリクエストボディにidを入れる場合、ハッシュidに変換して渡します。
let(:id) { create(:event).hashid }
過去、未来、現在の日付ごとにテストを作成する
時制の日付の違いで異なるテスト結果が得られる場合、それぞれに対応するテストケースを作成した方が良いです。
ちなみにFaker gemで過去、未来、現在の日付は以下のように作ります。
# 現在 let(:date) { Date.today.strftime("%Y-%m-%d") } # 過去 let(:date) { Faker::Date.between(from: 5.days.ago, to: Date.today - 1).strftime("%Y-%m-%d") } # 未来 let(:date) { Faker::Date.between(from: Date.today.next_day, to: 5.days.from_now).strftime("%Y-%m-%d") }
2つのデータを登録するテストケースで2つとも同じデータを使用しない。その際、Factoryを使わずに愚直にテストを書く
1つのデータを登録するテストケースは基本のテストケースです。1つのデータは一番外側のスコープに定義します。2つのデータを登録するテストケースでは、実際の状況を再現するために、2つとも別のデータを使用します。以下のように、2個目のデータはベタ書きします。 テストではDRYが推奨されておらず、愚直に書くぐらいの方がわかりやすいので、テストを書くときは過度にDRYにしないよう気をつけましょう
let(:params) do { events: [ { reserve_date:, price:, # 省略 }, ], } end let(:price) { price: Faker::Number.number(digits: 5) } # 省略 context "when reserve_date is present date" do let(:reserve_date) { Date.today.strftime("%Y-%m-%d") } context "one test data" do # 省略 end context "two test data" do let(:params) do { events: [ { reserve_date:, price:, # 省略 }, { date:, price: Faker::Number.number(digits: 5), # 省略 }, ], } end it "returns 201" do # 省略 end end end
(注) FactoryBotを使ってリクエストデータを一気に生成することもできますが、FactoryBotの本来の使い方は、モデルのインスタンスを用意するためであり、リクエストデータを作る目的で開発されたわけではありません。また、定義したFactoryを見ないとどんなデータがリクエストで使われているか不明です。そのため、リクエストでデータを渡す場合、愚直にletで書いた方が良いです。その方がテストの可読性が上がります。
テストケースをそこまで書いていない場合、shared_examplesはspec全体の見通しが悪くなるので、使わない
テストケースをそこまで書いていない場合、shared_examplesは、spec全体の見通しが悪くなるので、使わないようにします。 それぞれのcontext内のテストケースがどういうレスポンスであるべきなのかの見通しが悪くなってしまうので、愚直に書いたほうがいいです。先ほどのテストでは過度なDRYを避けるに通じます。
contextの説明を具体的にする
contextは、テストの内容を「状況・状態」のバリエーションごとに分類するために利用します。contextには、具体的に状況や状態を書きましょう。以下の場合、 何がpresentなのか不明なので、具体的に書いた方が可読性が上がるので良いです。
↓ before
context "present" do
↓ after
context "when date is present date" do
むやみにテストケースを増やすようなデータの持ち方をしない
例として2つのデータを登録するテストケースを考えます。データにはexpiry_date属性があり、この属性はnilを許容するとします。expiry_date属性がnilではない同じような2つのデータを登録するテストケースを作成した場合、expiry_date属性がnilの時のテストケースを作成する必要があります。むやみにテストケースを増やしたくないのと、expiry_date属性がnilでもレスポンス結果が変わらない(データが登録できる)ので、2つ目のデータのexpiry_date属性をnilにします。そうすることで、expiry_date属性がnilの時のテストケースを作成せずにnilの時の検証ができます。
context "two test data" do let(:params) do { events: [ { date:, price:, expiry_date:, # 省略 }, { date:, price: Faker::Number.number(digits: 5), expiry_date: nil, # 省略 }, ], } end
レスポンスが変化しない場合、テストケースを増やさなくて良い
日付が現在の場合で、2つのデータが登録できるなら、日付が過去の場合で2つのデータが登録できることを検証しなくても大丈夫です。テストケースが増えるのを避けたいのと、既に検証済みのテストケースなので、あえて増やさなくても大丈夫です。
また、データを渡すと例外を返すテストケースの場合、データが1個でも2個でも同じレスポンスを返すので、データが2個以上の時のテストケースをわざわざ作成する必要はないです。
同じようなテストを再度する必要はない(重要)。
テストケースが網羅されることは重要ですが、数が増えすぎると見通しが悪くなり、テストのメンテナンスコストが上がってしまい、生産性を下げてしまいます。そのため、テストケースは「必要最低限」を心がけます。
感想
転職してバックエエンドのコードレビューを初めて受けたのですが、自分の分かっていない部分が明確になって良かったです。Rails7、OpenAPI、テストがもっとできるようになりたい、、とりあえずテストに関しては、「テストケースを無駄に増やしすぎずかつ網羅する、DRYに書かずに愚直に書く」というのが知れて良かったです。また、Railsに関しても、「どのタイミングでメソッドを定義するか、トランザクションはどうやって定義するか」を知ることができて良かったです。ちなみにComparisonValidatorはRails7の公式ドキュメントから見つけたので、「やっぱり公式ドキュメントって偉大だな、まず最初に見るべき情報だな」と感じました。
どういう基準でテストケースを作成するか、OpenAPIが具体的に分かっていないので、実務を通して理解を深めていこうと思います。
あとTDDでAPIを実装したのですが、TDDだとすごく実装しやすかったので、引き続きAPIを実装するときはTDDで実装しようと思います。
参考記事
【Rails】hashid-railsを用いてIDを難読化・暗号化させる方法|TechTechMedia
OpenAPIにおけるundefinedとnullの設計 | フューチャー技術ブログ
スキーマファースト開発のためのOpenAPI(Swagger)設計規約 | フューチャー技術ブログ
CRUDでプロパティが変わるモデルをOpenAPIで書くときの定義分割 | インサイトテクノロジー
OpenAPI(swagger): 定義したスキーマの使用時に一部を上書きしたい時の小技 - Qiita
最低限知っておきたい!Railsのトランザクション実装例 - 行動すれば次の現実
GitHub - rails-api/active_model_serializers at 0-8-stable
2021年9月30日 現場Rails Chapter5 Rspecの基本形 - 6時だョ!!全員集合!!
【初心者向け】テストコードの方針を考える(何をテストすべきか?どんなテストを書くべきか?) - Qiita
【さわって学ぶクラウドインフラ docker 基礎からのコンテナ構築】第6章 コンテナのネットワークで知らなかったことをざっくりまとめてみた
目次
- 目次
- 概要
- 3つのネットワーク
- bridgeネットワーク
- コンテナに割り当てられているIPアドレスを確認する
- コンテナ同士の通信
- Dockerのネットワークを新規に作成して通信を分ける
- Dockerネットワーク内にコンテナを作る
- 既存のコンテナを別のDockerネットワークに所属させる
- コンテナ名で通信ができることを確認する
- Dockerネットワークの削除
- hostネットワーク
- noneネットワーク
- 参考記事
概要
Dockerホスト上では、複数の独立したコンテナを実行する事ができます。時にはコンテナ間での通信が必要な場面があるので、コンテナのネットワークについて学びます。
3つのネットワーク
Dockerでは、 さまざまなネットワークを作り、Dockerホストとコンテナ、またはコンテナ間で通信する事ができます。 以下のコマンドでDockerが管理するネットワークを確認できます。
ubuntu@ip-10-0-12-65:~$ docker network ls NETWORK ID NAME DRIVER SCOPE 49ea1ad2bf81 bridge bridge local d8850b15265b host host local a8e3cb52fef7 none null local ubuntu@ip-10-0-12-65:~$
規定では「bridge」「host」「none」という3つのネットワークがあります。このうちよく使われるのが「bridge」ネットワークです。
bridgeネットワーク
bridgeネットワークとは、 デフォルトのネットワークのことです。docker run(もしくはdocker create)でコンテナを作成する場合、ネットワークオプションを指定しなかったら、このネットワークが使われます。このネットワークにコンテナが属すことになります。 bridgeネットワークにおいては、それぞれのコンテナのネットワークは独立しており、-pオプションでどのコンテナ(またはDockerホスト)と通信するかを決めます。
(注) bridgeネットワークはIPマスカレード(ポート番号を利用することで、1つのグローバルIPアドレスと複数のプライベートIPアドレスを紐付けて変換する技術)を使って構成されています。
コンテナに割り当てられているIPアドレスを確認する
DockerホストやDockerコンテナは一つの仮想的なbirdgeネットワークによて接続されます。ネットワーク通信なので、DockerホストやDockerコンテナにはIPアドレスが付与されています。
コンテナのIPアドレスを確認するためには、コンテナを起動させて、docker container inspectコマンドを実行します。このうち「NetworkSettings」の部分にIPアドレスが記載されています。
(※) コンテナのIPアドレスを確認するためには、docker container inspect以外に、コンテナ内でipコマンドやifconfigコマンドを実行して確認する事ができます。イメージによっては、軽量化のためにipコマンドやifconfigコマンドが入っていない場合もあります。
docker container inspect コンテナ名
"NetworkSettings": { "Bridge": "", "SandboxID": "ff3b23c1fcb196bcc3ad90310c87b73d56a21977c04ea38b6c34aae574a829ec", "HairpinMode": false, "LinkLocalIPv6Address": "", "LinkLocalIPv6PrefixLen": 0, "Ports": { "80/tcp": [ { "HostIp": "0.0.0.0", "HostPort": "8080" }, { "HostIp": "::", "HostPort": "8080" } ] }, "SandboxKey": "/var/run/docker/netns/ff3b23c1fcb1", "SecondaryIPAddresses": null, "SecondaryIPv6Addresses": null, "EndpointID": "a2e7c6bb5d3fa4c254754499871c086bb39f54ca7e53fda8cd28472a95fbce48", "Gateway": "172.17.0.1", "GlobalIPv6Address": "", "GlobalIPv6PrefixLen": 0, "IPAddress": "172.17.0.2", "IPPrefixLen": 16, "IPv6Gateway": "", "MacAddress": "02:42:ac:11:00:02", "Networks": { "bridge": { "IPAMConfig": null, "Links": null, "Aliases": null, "NetworkID": "49ea1ad2bf81b1c4315446f90cb1e10339d886434673c2e1c78146875beaa801", "EndpointID": "a2e7c6bb5d3fa4c254754499871c086bb39f54ca7e53fda8cd28472a95fbce48", "Gateway": "172.17.0.1", "IPAddress": "172.17.0.2", "IPPrefixLen": 16, "IPv6Gateway": "", "GlobalIPv6Address": "", "GlobalIPv6PrefixLen": 0, "MacAddress": "02:42:ac:11:00:02", "DriverOpts": null } } }
docker container inspectを実行すると、そのコンテナの全情報が表示されるので、--formatオプションを指定して特定の項目だけ表示することもできます。以下のコマンドでは、IPアドレスの部分だけを取得しています。
docker container inspect --format="{{.NetworkSettings.IPAddress}}" コンテナ名
コンテナ同士の通信
コンテナはそれぞれIPアドレスを持ち、bridgeネットワークに接続されています。そのため、コンテナ同士は、このネットワークを通じて互いに通信できます。 コンテナ間の通信の場合、-pオプションを指定しなくても可能です。-pオプションはあくまでDockerホストで受信したリクエストをDockerコンテナの特定のポートに転送するための設定です。Dockerコンテナ間で通信する場合は、Dockerホストを経由しないので、-pオプションは関係ないです。
コンテナのシェルを立ち上げて、curlコマンドやpingコマンドを使うことで、別のコンテナと通信できるかを確認できます。
作業手順
手順1:
以下のコマンドを実行して、ubuntuのコンテナを立ち上げます。
docker run --rm -it ubuntu /bin/bash
手順2:
ip、ping、curlという3つのコマンドを使いたいので、aptコマンドでインストールします。
apt update apt -y upgrade apt install -y iproute2 iputils-ping curl
手順3:
ipコマンドを入力して、コンテナ自身のIPアドレスを確認します。
ip address
コンテナのIPアドレスは172.17.0.4である事が分かりました。
root@00f8a5490627:/# ip address 1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000 link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00 inet 127.0.0.1/8 scope host lo valid_lft forever preferred_lft forever 24: eth0@if25: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default link/ether 02:42:ac:11:00:04 brd ff:ff:ff:ff:ff:ff link-netnsid 0 inet 172.17.0.4/16 brd 172.17.255.255 scope global eth0 valid_lft forever preferred_lft forever
手順4:
既に存在しているコンテナに対してpingコマンドを使って疎通確認をします。結果が「0% packet loss」になっていれば疎通できています。
root@00f8a5490627:/# ping -c 4 172.17.0.2 PING 172.17.0.2 (172.17.0.2) 56(84) bytes of data. 64 bytes from 172.17.0.2: icmp_seq=1 ttl=64 time=0.104 ms 64 bytes from 172.17.0.2: icmp_seq=2 ttl=64 time=0.063 ms 64 bytes from 172.17.0.2: icmp_seq=3 ttl=64 time=0.066 ms 64 bytes from 172.17.0.2: icmp_seq=4 ttl=64 time=0.065 ms --- 172.17.0.2 ping statistics --- 4 packets transmitted, 4 received, 0% packet loss, time 3054ms rtt min/avg/max/mdev = 0.063/0.074/0.104/0.017 ms root@00f8a5490627:/# ping -c 4 172.17.0.3 PING 172.17.0.3 (172.17.0.3) 56(84) bytes of data. 64 bytes from 172.17.0.3: icmp_seq=1 ttl=64 time=0.098 ms 64 bytes from 172.17.0.3: icmp_seq=2 ttl=64 time=0.066 ms 64 bytes from 172.17.0.3: icmp_seq=3 ttl=64 time=0.067 ms 64 bytes from 172.17.0.3: icmp_seq=4 ttl=64 time=0.065 ms --- 172.17.0.3 ping statistics --- 4 packets transmitted, 4 received, 0% packet loss, time 3058ms rtt min/avg/max/mdev = 0.065/0.074/0.098/0.013 ms
(※) -c 4は4回試したら終わるオプションです。オプションを省略すると、ずっと動きっぱなしになるので、ctrl + cで停止します。
手順5:
curlコマンドでWebサーバーに接続してコンテンツを取得できるかを確認します。ポートは省略すると既定のポート80番に接続されます。
curl http://IPアドレス/
root@00f8a5490627:/# curl http://172.17.0.2 <html><body><h1>It works!</h1></body></html>
(注) pingコマンドやcurlコマンドにIPアドレスではなくコンテナ名を指定すると、エラーになるので、気をつけましょう。
Dockerのネットワークを新規に作成して通信を分ける
コンテナ間で通信するためには、IPアドレスを指定する必要があります。しかし、コンテナのIPアドレスをdocker container inspectで確認しないといけないので、面倒です。 コンテナ名で通信するためには、Dockerネットワークを新規作成するか、linkオプションを指定します。linkオプションは推奨されていないので、コンテナ名でコンテナ間通信をするために、Dockerネットワークを作成します。Dockerネットワークを作成して、その中に複数のコンテナを所属させれば、そのDockerネットワークに所属しているコンテナ間でコンテナ名を使って通信ができます。
Dockerネットワーク
Dockerネットワークとは、 ユーザーが作成した任意のネットワークのことです。 ネットワークを作ることで、「あるコンテナは、こちらのネットワークに、別のコンテナはこちらのネットワークに」というように、別々のネットワークにコンテナを所属させる事ができます。
Dockerネットワークを作ると、その数だけ、Dockerホスト上には「br-DockerのネットワークIDの先頭」という名前のネットワークインターフェースが作られます。
Dockerネットワークのメリット
Dockerネットワークのメリットは、コンテナ間で通信するときに、コンテナ名を指定して通信ができるところです。bridgeネットワークで問題となっていたIPアドレスでしか通信できないという問題を解決します。
Dockerネットワークを作る
以下のコマンドを実行して、Dockerネットワークを作成します。
docker network create ネットワーク名
(※) Dockerネットワークを作成すると、それに伴い、Dockerホストにネットワークインターフェースが追加されます。
ubuntu@ip-10-0-12-65:~$ docker network create mydockernet 51b0d74b3e53d3e295802c483dfe40d22b02ebc6481d89a51677d372ad59a566 ubuntu@ip-10-0-12-65:~$ docker network ls NETWORK ID NAME DRIVER SCOPE 49ea1ad2bf81 bridge bridge local d8850b15265b host host local 51b0d74b3e53 mydockernet bridge local a8e3cb52fef7 none null local
新しく「mydockernet」という名前のネットワークがbridgeというドライバーで作成された事が分かります。
Dockerネットワークの詳細情報を見るためには、以下のコマンドを実行します。
docker network inspect Dockerネットワーク名
ubuntu@ip-10-0-12-65:~$ docker network inspect mydockernet
[
{
"Name": "mydockernet",
"Id": "51b0d74b3e53d3e295802c483dfe40d22b02ebc6481d89a51677d372ad59a566",
"Created": "2022-11-23T06:46:47.833364427Z",
"Scope": "local",
"Driver": "bridge",
"EnableIPv6": false,
"IPAM": {
"Driver": "default",
"Options": {},
"Config": [
{
"Subnet": "172.18.0.0/16",
"Gateway": "172.18.0.1"
}
]
},
"Internal": false,
"Attachable": false,
"Ingress": false,
"ConfigFrom": {
"Network": ""
},
"ConfigOnly": false,
"Containers": {},
"Options": {},
"Labels": {}
}
]
Dockerネットワーク内にコンテナを作る
Dockerネットワーク内にコンテナを作成するためには、--netオプションを指定します。
docker run -dit --name web01 -p 8080:80 --net Dockerネットワーク名 httpd:2.4
docker network inspect ネットワーク名で、Containersの部分にネットワークに所属させたコンテナが存在すればOKです。
既存のコンテナを別のDockerネットワークに所属させる
既存のコンテナを別のDockerネットワークに所属させるためには、docker network connectコマンドおよびdocker network disconnectコマンドを使用します。docker network connectでコンテナをネットワークに所属させたり、docker network disconnectでコンテナをネットワークから切断したりできます。
docker network connect ネットワーク名(ネットワークID) コンテナ名(コンテナID)
docker network disconnect ネットワーク名(ネットワークID) コンテナ名(コンテナID)
bridgeネットワークから別のDockerネットワークにコンテナを所属させるためには、以下のコマンドを実行します。
docker network disconnect bridge web01 docker network connect mydockernet web01
コンテナ名で通信ができることを確認する
Dockerネットワーク内のコンテナ間では、以下のようにpingやcurlでコンテナ名を指定して通信する事ができます。
root@9ed0ae318511:/# ping -c 4 web01 PING web01 (172.18.0.2) 56(84) bytes of data. 64 bytes from web01.mydockernet (172.18.0.2): icmp_seq=1 ttl=64 time=0.085 ms 64 bytes from web01.mydockernet (172.18.0.2): icmp_seq=2 ttl=64 time=0.082 ms 64 bytes from web01.mydockernet (172.18.0.2): icmp_seq=3 ttl=64 time=0.069 ms 64 bytes from web01.mydockernet (172.18.0.2): icmp_seq=4 ttl=64 time=0.068 ms --- web01 ping statistics --- 4 packets transmitted, 4 received, 0% packet loss, time 3060ms rtt min/avg/max/mdev = 0.068/0.076/0.085/0.007 ms root@9ed0ae318511:/#
root@9ed0ae318511:/# curl http://web01 <html><body><h1>It works!</h1></body></html>
(※)Dockerネットワークを使ってコンテナ間で通信する際にコンテナ名でアクセスできる理由は、Dockerが用意しているDNSサーバーを使って、コンテナ名とIPアドレスを紐づけているからです。
Dockerネットワークの削除
ネットワークを削除するためには、まずはネットワークを利用しているコンテナを削除 or ネットワークから切断する必要があります。その後Dockerネットワークを削除できます。 以下のコマンドでDockerネットワークを削除できます。
docker network rm Dockerネットワーク名
(※) Dockerネットワークを削除すると、それに対応するDockerホストのインターフェースも削除されます。
hostネットワーク
hostネットワークでは、IPマスカレードを使わずに、コンテナがホストのIPアドレスを共有します。あまり使わないので、使う時になったら調べます。
noneネットワーク
noneネットワークでは、コンテナはネットワークに接続されません。docker run(もしくはdocker create)の際に、--net noneを指定します。または、docker network disconnectでネットワークから切断しても同じ状態になります。セキュリティを高めたいなどの理由でコンテナをネットワーク通信から隔離したい時に使います。hostネットワークと同様、あまり使わないので、使う時になったら調べます。
参考記事
さわって学ぶクラウドインフラ docker基礎からのコンテナ構築 | 大澤 文孝, 浅居 尚 |本 | 通販 | Amazon
Docker の bridge と host ネットワークについて勉強する - Qiita
第29回 Docker Networkingの基礎知識 標準的なネットワークを理解する:古賀政純の「攻めのITのためのDocker塾」(5/5 ページ) - ITmedia エンタープライズ
【 ping 】コマンド/【 ping6 】コマンド――通信相手にパケットを送って応答を調べる:Linux基本コマンドTips(143) - @IT
【さわって学ぶクラウドインフラ docker 基礎からのコンテナ構築】第5章 コンテナ内のファイルと永続化で知らなかったことをざっくりまとめてみた
目次
- 目次
- 概要
- 2つのhttpdコンテナを1つのDockerホスト内で起動させてみる
- コンテナの中のファイルを変更する
- pushdコマンド・popdコマンド
- index.htmlをDockerホストに作り、それをコンテナにコピーしてみる
- コンテナの破棄をすると、コピーしたファイルが失われる
- データを独立させる
- Dockerホストのディレクトリを2つ以上のコンテナで同時にマウントする
- バインドマウントとボリュームマウント
- MySQLコンテナを起動させてみる
- Dockerイメージを使う時の注意点
- データのバックアップ
- ボリュームの削除
- ボリュームをリストアする
- 参考記事
概要
コンテナを破棄すれば、その中にあるファイルは自ずと失われます。今回は、コンテナを破棄してもファイルを残すための方法、そして、バックアップの方法について学びます。
2つのhttpdコンテナを1つのDockerホスト内で起動させてみる
マウントをせず、2つのhttpdコンテナ(web01とweb02)を起動させます。
作業手順
手順1:
1つ目のhttpdコンテナを起動します。
docker run -dit --name web01 -p 8080:80 httpd:2.4
手順2:
2つ目のhttpdコンテナを起動します。
docker run -dit --name web02 -p 8081:80 httpd:2.4
手順3:
「http://18.183.203.210:8081/」と「http://18.183.203.210:8081/」にアクセスすると、どちらにも接続でき「It works!」と表示されます。つまり、この2つのコンテナは完全に互いに独立していることが分かりました。そして、1台のDockerホストに2台のWebサーバーを同居させることができました。
コンテナの中のファイルを変更する
コンテナの中のファイルを変更するには、docker execコマンドで/bin/bashを起動してコンテナの内部に入り、そこでvimを起動して、/usr/local/apache2/htdocs/index.htmlを編集するという方法が考えられます。しかし、httpdイメージはファイルサイズを小さくするために、Vimなどは含まれていません。入っていない場合は、aptコマンドでVimをインストールすればいいのですが、結構めんどくさいです。 この場合、docker cpコマンドを使用します。docker cpコマンドを使うことで、 DockerホストとDockertコンテナ間でファイルやディレクトリをコピーすることができます。docker cpコマンドは、コンテナが稼働中でも停止中でも、どちらの場合でもファイルやディレクトリをコピーできます。
↓ ホスト→コンテナの向きでファイルをコピーする場合
docker cp オプション コピー元のパス名 コンテナ名またはコンテナID:コピー先のパス名
↓ コンテナ→ホストの向きにコピーする場合
docker cp オプション コンテナ名またはコンテナID:コピー元のパス名 コピー先のパス名
docker cpコマンドは、パーミッションをそのままコピーします。また、ディレクトリも再帰的にコピーします。
(注) docker cpでは、/proc、/sys、/dev、tmpfs配下のような、システムファイルはコピーできません。こうしたファイルをコピーしたいときは、標準入出力経由でコピーします。あと、コピー先のパスのファイル名は自由につける事ができます。
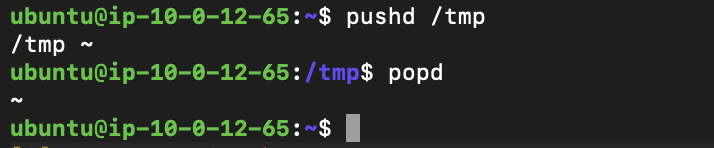
pushdコマンド・popdコマンド
pushdコマンドは、シェルにおいて、現在のカレントディレクトリの状態を保存した上で、パスで指定した場所にカレントディレクトリを移動させます。保存したカレントディレクトリの位置まで戻るには、popdと入力します。
index.htmlをDockerホストに作り、それをコンテナにコピーしてみる
docker cpコマンドを使うことで、 Dockerホスト上のファイルをコンテナにコピーできます。
作業手順
手順1:
pushdコマンドでカレントディレクトリを/tmpにします。その後、/tmp配下にweb01コンテナ用のindex.htmlを作成します。
pushd /tmp
手順2:
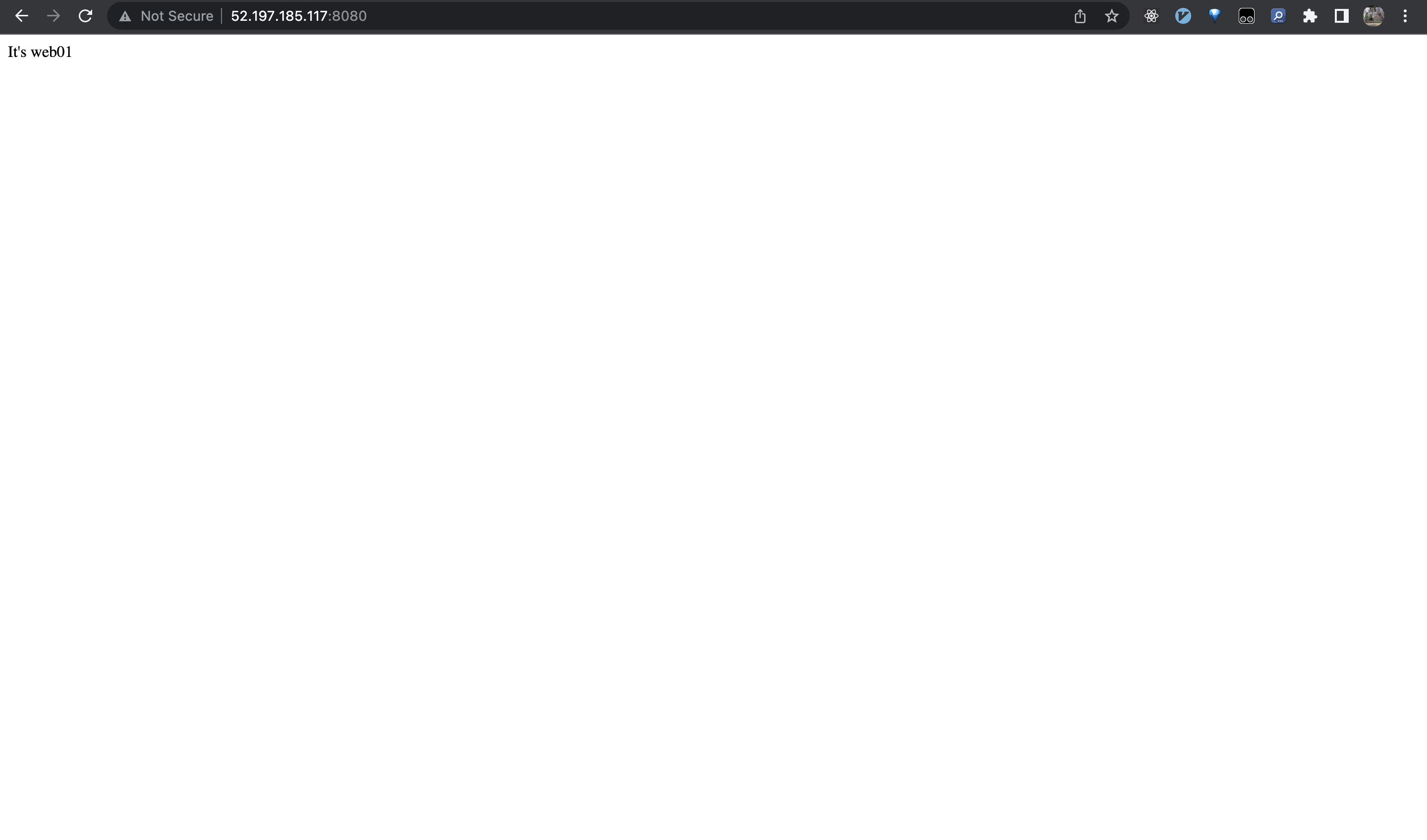
index.htmlファイルを、以下のコマンドで、コンテナweb01の/usr/local/apache2/htdocs/にコピーします。
docker cp /tmp/index.html web01:/usr/local/apache2/htdocs/index.html
(注) コピー先のパスのファイル名は自由につける事ができます。
ブラウザで「http://Dockerホスト:8080/」に接続すると、index.htmlの内容が表示されていることがわかります。
手順3:
Dockerホストのファイルが本当にコンテナにコピーされたかを、コンテナに入って確認します。起動中のコンテナに入るためには、起動しているコンテナの中のbashを実行すれば良いので、以下のコマンドを実行します。
docker exec -it web01 /bin/bash
/usr/local/apache2/htdocs/に移動してlsコマンドを実行すると、index.thmlが存在することを確認できました。catコマンドで内容を確認すると同じであることも分かりました。

web02コンテナに対しても同じことをします。index02.htmlというファイルを作成します。index02.htmlの内容は、web02に関する内容にします。またDockerホストからweb02コンテナにコピーするときは、コンテナ上でのファイル名をindex.htmlとしてコピーします。
docker cp /tmp/index02.html web02:/usr/local/apache2/htdocs/index.html
手順4:
popdコマンドで、カレントディレクトリに戻します。
コンテナの破棄をすると、コピーしたファイルが失われる
コンテナを停止して再開しても、Dockerホストからコンテナにコピーしたファイルは失われません。しかし、コンテナを破棄してコンテナを立ち上げると、DockerホストからDockerコンテナにコピーしたファイルは失われています。
docker run -dit --name web01 -p 8080:80 httpd:2.4
これは起動前のコンテナと削除後に起動したコンテナが別物であることを意味します。実際にdocker psコマンドでコンテナIDを確認すると、違う事がわかります。コンテナIDが違うので、別のコンテナであることがわかります。
大事なことは コンテナを作り直すと、別のコンテナが作成されるので、不注意にコンテナを削除してファイルを削除しないように気をつけましょう。
データを独立させる
docker rmでコンテナを破棄すると、そのコンテナの中にあるデータは失われます。 失ってはならないデータをコンテナに持たせたい場合、Dockerホストからコンテナに対してマウントを行います。
(※) コンテナでは「実行するシステム」と「扱うデータ」は別に管理することが推奨されています。
マウントはディレクトリを同期することなので、ディレクトリを指定します。マウントする場合は、-vオプションを指定します。以下のコマンドでは、Dockerホストのubuntuディレクトリをコンテナのhtdocsディレクトリにマウントしています。
docker run -dit --name web01 -p 8080:80 -v /home/ubuntu/:/usr/local/apache2/htdocs httpd:2.4
Dockerホスト上にあるディレクトリは、コンテナを破棄しても失われることはありません。Dockerホスト上のディレクトリをマウントすることで、コンテナを破棄しても、また同じファイルを持ったコンテナを作成する事ができます。 また、データをDockerホスト側に持つことで、イメージのアップデートに対応するのが容易になります。
Dockerホストのディレクトリを2つ以上のコンテナで同時にマウントする
Dockerホストのディレクトリを2つ以上のコンテナで同時にマウントすることもできます。そうすることで、2つ以上のコンテナ間でファイルの共有をする事ができます。
(※) ボリュームでも同じように2つ以上のコンテナに対して、同時にマウントできます。
バインドマウントとボリュームマウント
バインドマウントとは、 Dockerホストにあらかじめディレクトリを作っておき、それをマウントする方法のことです。 今までやってきた-vオプションのマウント元にパスを指定するのが、バインドマウントです。
ボリュームマウント
ボリュームマウントとは、 ホスト上のディレクトリではなく、Docker Engine上で確保した領域をマウントする方法のことです。確保した場所のことを「データボリューム」または「ボリューム」と呼びます。 ボリュームマウントをする場合、-vオプションのマウント元にボリュームを指定します。または、-vオプションではなく、mountオプションを使用します。
ボリュームマウントをする場合、コンテナを作る前に、ボリュームをあらかじめdocker volume createコマンドを使って作成します。
ボリュームマウントのメリット
ボリュームマウントのメリットは、それぞれのDockerホストのディレクトリ構成を意識せずにマウントが行えることです。また、ボリュームはブラックボックスなので、Dockerホストから変更させたくないようなファイルをマウントするのに適しています。そのため、データベース用のコンテナのデータを保存する場所として、ボリュームは優れています。
(※) ボリュームはデフォルトではDockerホスト上のストレージですが、ボリュームプラグインをインストールすることで、AWSのS3ストレージやNFSなどのネットワークストレージを用いることもできます。
MySQLコンテナを起動させてみる
↓ MySQLがインストールされたコンテナのDockerイメージ Docker Hub
マウントすべきディレクトリ
DBのデータは/var/lib/mysqlディレクトリに保存されます。ここをボリュームマウント(またはバインドマウント)することで、コンテナを破棄しても、DBの内容が失われないようにします。
rootユーザーのユーザー名、パスワード、既定のデータベース名などの指定方法
DBにアクセスする際のrootユーザーのユーザー名、パスワード、既定のデータベースなどは、環境変数として引き渡します。MYSQL_ROOT_PASSWORDのみ必須で、残りはオプションです。 環境変数を指定するときは、-eオプションを指定します。
作業手順
手順1:
以下のコマンドを実行してボリュームを作成します。
docker volume create --name ボリューム名
docker volume create --name mysqlvolume
作成したボリュームは以下のコマンドで確認できます。
docker volume ls
以下のように表示されます。
ubuntu@ip-10-0-12-65:~$ docker volume ls
DRIVER VOLUME NAME
local mysqlvolume
手順2:
ボリュームをマウントしてMySQLのコンテナを起動します。rootユーザーのパスワードを「mypassword」にします。ボリュームマウントをしたい場合、-vオプションのマウント元にボリュームを指定します。
docker run --name db01 -dit -v mysqlvolume:/var/lib/mysql -e MYSQL_ROOT_PASSWORD=mypassword mysql:5.7
手順3:
MySQLコンテナにログインして、新しいDBを作り、適当なデータを書き込みます。その後、コンテナを破棄して新しいコンテナをボリュームマウントして作り直しても、そのデータが破棄されていない事が分かります。
Dockerイメージを使う時の注意点
Dockerイメージを使う場合、そのイメージの制作者が「どのような使い方を想定して作っているのか」「各種設定はどのようにして行えば良いのか」を、記載されているドキュメントから汲み取る必要があります。
データのバックアップ
バインドマウントの場合、Dockerホスト上のファイルをバックアップすれば良いので、Dockerホストで別のディレクトリにコピーするか、tarコマンドでファイルをまとめて保存すればバックアップできます。
ボリュームマウントの場合、ボリュームのバックアップをするには、ボリュームを適当なコンテナに割り当てて、そのコンテナを使ってバックアップを取ります。
tarコマンドとは
以下の記事が分かりやすかったので、引用させていただきます。
↓ 引用(【 tar 】コマンド――アーカイブファイルを作成する/展開する)
「tar」は、複数のファイルを1つにまとめた“アーカイブファイル”を作成/展開するコマンドです。
(※) アーカイブとは書庫という意味です。tarコマンドはプログラムの複数ファイル群をまとめて保管したり、配布する際に使用します。
ボリュームの詳細情報を確認する
ボリュームの詳細情報は以下のコマンドで確認できます。
docker volume inspect ボリューム名 (またはボリュームID)
Mountpointが実際にコンテナにマウントされている場所です。
ubuntu@ip-10-0-12-65:~$ docker volume inspect mysqlvolume
[
{
"CreatedAt": "2022-11-23T01:31:40Z",
"Driver": "local",
"Labels": {},
"Mountpoint": "/var/lib/docker/volumes/mysqlvolume/_data",
"Name": "mysqlvolume",
"Options": {},
"Scope": "local"
}
]
ubuntu@ip-10-0-12-65:~$
ボリュームバックアップの作業手順
適当なLinuxシステムが入ったコンテナを1つ別に起動します。その際、コンテナ内の/tmpなどのディレクトリにパックアップ対象のボリュームをマウントします。その後、tarコマンドでパックアップを作り、そのバックアップをDockerホストで取り出せばバックアップは完了です。リストアするときは逆の手順で戻します。
(注) コンテナの稼働中のバックアップはデータの整合性が取れなくなる可能性があるので、バックアップ中はコンテナ(DBコンテナ等)を停止しておくのが望ましいです。
手順1:
ボリュームを利用中のコンテナが停止中または存在しないかを確認します。
docker ps -a
手順2:
軽量Linuxシステムのbusyboxが入ったコンテナを、mysqlvolumeをマウントして起動します。その際、tarコマンドを実行してアーカイブします。
docker run --rm -v mysqlvolume:/src -v "$PWD":/dest busybox tar czvf /dest/backup.tar.gz -C /src .
このコマンドでは、一つ目のvオプションでバックアップをしたいmysqlvolumeを/srcにボリュームマウントしています。2つ目のvオプションではDockerホストのカレントディレクトリを/destにバインドマウントをしています。最後に tar czvf /dest/backup.tar.gz -C /src .を実行することで、/srcディレクトリの全ファイルが/dest/backup.tar.gzにバックアップしています。/destをDockerホストのカレントディレクトリにマウントしているので、このファイルはDockerホストのカレントディレクトリから参照する事ができます。
(注) 1つのコンテナに対して複数のマウントをすることができるので、その点を忘れないようにしましょう。
ボリュームの削除
以下のコマンドを実行することで、ボリュームを削除できます。
docker volume rm ボリューム名
どのコンテナからもマウントされていないボリュームを削除する場合、以下のコマンドでボリュームをまとめて削除する事ができます。
docker volume prune
ボリュームをリストアする
カレントディレクトリにあるbackup.tar.gzをリストアするためには、ボリュームを一旦削除後、同じ名前のボリュームを再度作り直してリストアします。リストアするためには以下のコマンドを実行します。
docker run --rm -v mysqlvolume:/dest -v "$PWD":/src busybox tar xzf /src/backup.tar.gz -C /dest
このコマンドでは、リストア先のボリューム(mysqlvolume)を/destにボリュームマウント、Dockerホストのカレントディレクトリを/srcにバインドマウントしています。こうすることで、カレントディレクトリに置いたbackup.tar.gzは、/src/backup.tar.gzとして参照する事ができます。その後、tar xzf /src/backup.tar.gzを実行して、ファイルを/destに展開しています。/destはリストア先のボリューム(mysqlvolume)にマウントされているので、結果的にそのボリュームにファイルが展開されます。
参考記事
さわって学ぶクラウドインフラ docker基礎からのコンテナ構築 | 大澤 文孝, 浅居 尚 |本 | 通販 | Amazon